Clear Sky Science · es
Mejora de la esparsidad de la señal fuente basada en el algoritmo local de extracción sincronizada por máximos para la estimación de matriz mixta en UBSS
Desenredando señales ocultas
Muchas de las tecnologías en las que confiamos—redes inalámbricas, radar, escáneres médicos e incluso micrófonos inteligentes—deben identificar señales débiles que están completamente mezcladas. Imagínese intentar seguir varias conversaciones a la vez en un café lleno usando solo dos oídos. Este artículo presenta una nueva forma de "desenredar" señales superpuestas cuando hay menos sensores que fuentes, un escenario notoriamente difícil. Afinando cómo observamos las señales en tiempo y frecuencia, y mejorando cómo los ordenadores agrupan datos relacionados, los autores demuestran que pueden separar mezclas de manera más precisa y fiable, incluso en condiciones ruidosas del mundo real. 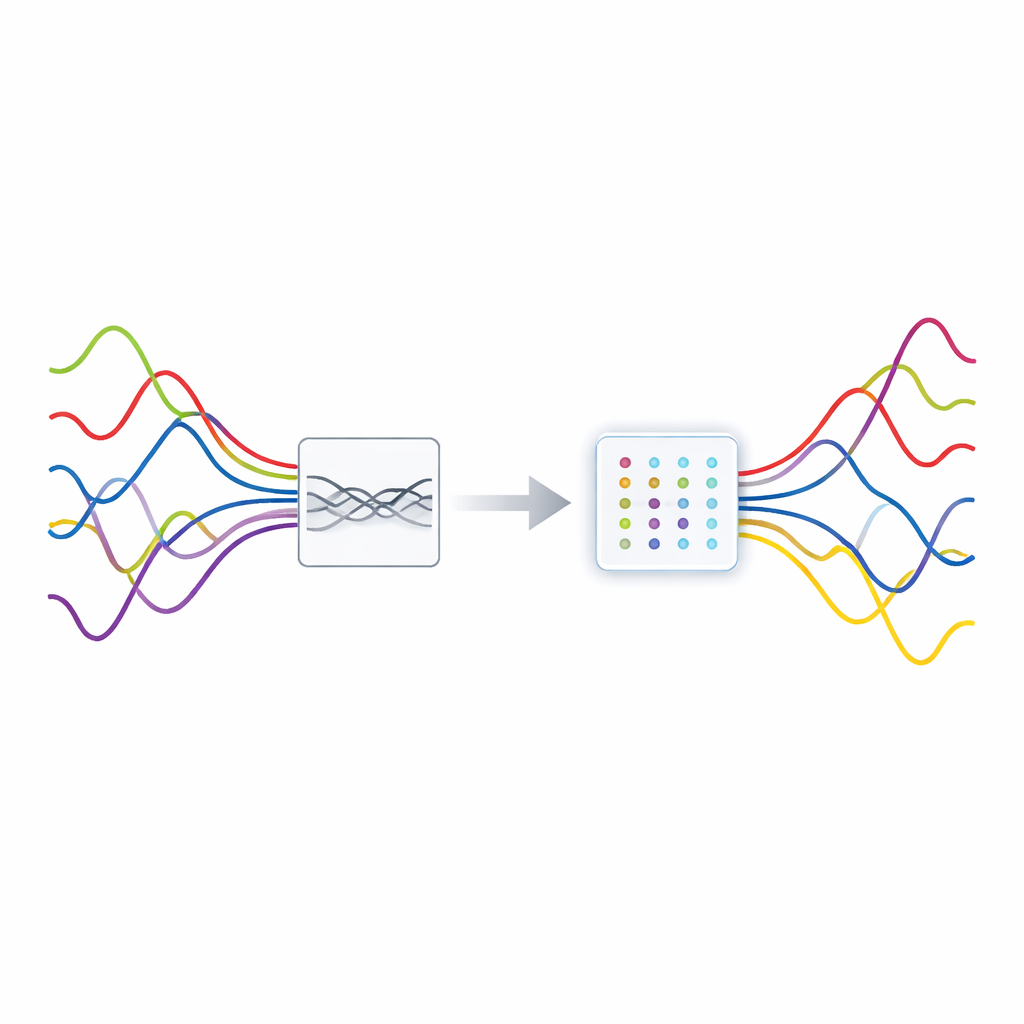
Por qué es tan difícil separar señales mezcladas
En muchos sistemas, varias señales independientes viajan por el mismo canal y son captadas por un número reducido de receptores. Esta situación, llamada separación ciega de fuentes sobredeterminada (underdetermined blind source separation), significa que hay más señales desconocidas que mediciones. Los métodos clásicos de separación de señales generalmente asumen lo contrario, por lo que fallan aquí. Un truco moderno clave es explotar la esparsidad: en una representación adecuada, cada fuente está activa solo en unos pocos instantes o frecuencias. Si, en la mayoría de los instantes, solo una fuente domina, la nube de datos observados forma naturalmente agrupaciones cuyas direcciones codifican cómo se mezcló cada fuente en los receptores. Encontrar estas agrupaciones con precisión, sin embargo, depende de disponer de una representación en la que la energía de cada fuente esté concentrada de forma nítida en lugar de difusa.
Afinando la imagen de una señal
Para descubrir la esparsidad, los ingenieros suelen transformar las señales en una representación tiempo‑frecuencia que muestra qué tonos están presentes en qué instantes. La simple transformada de Fourier de tiempo corto hace esto deslizando una ventana a lo largo del tiempo y tomando muchos espectros pequeños, pero difumina la energía y no puede ofrecer simultáneamente una buena resolución temporal y una precisión de tono. Variantes más avanzadas como el synchrosqueezing y el synchroextracting intentan arrastrar la energía dispersa hacia la cresta que sigue la frecuencia instantánea de una señal. Estos métodos mejoran el enfoque, pero siguen siendo vulnerables al ruido: cuando las perturbaciones aleatorias se comprimen a lo largo de las mismas crestas que la señal, el resultado puede ser una banda brillante pero borrosa que oculta la estructura fina.
Encontrar picos locales para impulsar la esparsidad
Basándose en estas ideas, los autores introducen la Transformada Local de Extracción Sincrónica por Máximos, o LMSET (Local Maximum Synchroextracting Transform). En lugar de empujar toda la energía cercana hacia una cresta de frecuencia, LMSET rastrea el plano tiempo‑frecuencia y, para cada instante, se fija en los picos locales a lo largo del eje de frecuencia. Solo se conservan y reasignan los coeficientes alrededor de esos máximos locales, mientras que el resto se suprime. Este cambio sencillo produce una representación en la que la energía de cada componente se concentra en curvas delgadas y limpias con muchos menos puntos dispersos. Mediante simulaciones con señales de prueba de múltiples componentes, LMSET produce la entropía de Rényi más baja, una medida estándar de concentración, superando a los métodos convencionales y de última generación en una amplia gama de niveles de ruido. En pocas palabras, LMSET ofrece una imagen más clara de dónde reside cada señal en tiempo y frecuencia.
Agrupamiento más inteligente para aprender la mezcla oculta
Una imagen más nítida es solo la mitad de la batalla; el siguiente paso es agrupar los puntos resultantes para estimar la matriz de mezcla desconocida que describe cómo cada fuente contribuye a cada receptor. Muchos enfoques se basan en el C‑means difuso, un método de agrupamiento popular que a menudo queda atrapado en soluciones pobres porque es muy sensible a la conjetura inicial y a puntos atípicos. Para superar estas debilidades, los autores acoplan LMSET con un nuevo esquema de agrupamiento más robusto. Primero usan un algoritmo de búsqueda basado en PID, inspirado en la teoría de control, para explorar todo el espacio posible de centros de clúster y evitar malas posiciones iniciales. A continuación introducen un mecanismo de pesos booleanos para reducir la influencia de los valores atípicos y emplean una estrategia basada en la información‑entropía que reduce la sensibilidad a las condiciones iniciales. En conjunto, estos pasos permiten que el agrupamiento se estabilice en las direcciones verdaderas de las fuentes ocultas de forma más consistente.
Qué revelan las pruebas
Los autores prueban su canalización completa—LMSET más el agrupamiento mejorado—en mezclas de señales de comunicación moduladas digitalmente, incluyendo QAM, QPSK y FSK, en entornos tanto silenciosos como ruidosos. Comparan las matrices de mezcla estimadas con las reales usando error angular y error cuadrático medio normalizado. En todos los casos, usar LMSET en lugar de una transformada tradicional reduce los errores, porque los puntos de datos forman clústeres más compactos y distintivos. Entre los métodos de agrupamiento, el C‑means difuso robusto optimizado por PID propuesto logra las desviaciones angulares medias más pequeñas y las mejores puntuaciones de error. En conjunto, el método combinado mejora la precisión de la estimación de la matriz de mezcla en casi un 20 por ciento respecto a los enfoques convencionales, manteniendo un rendimiento sólido incluso cuando los niveles de ruido son altos. 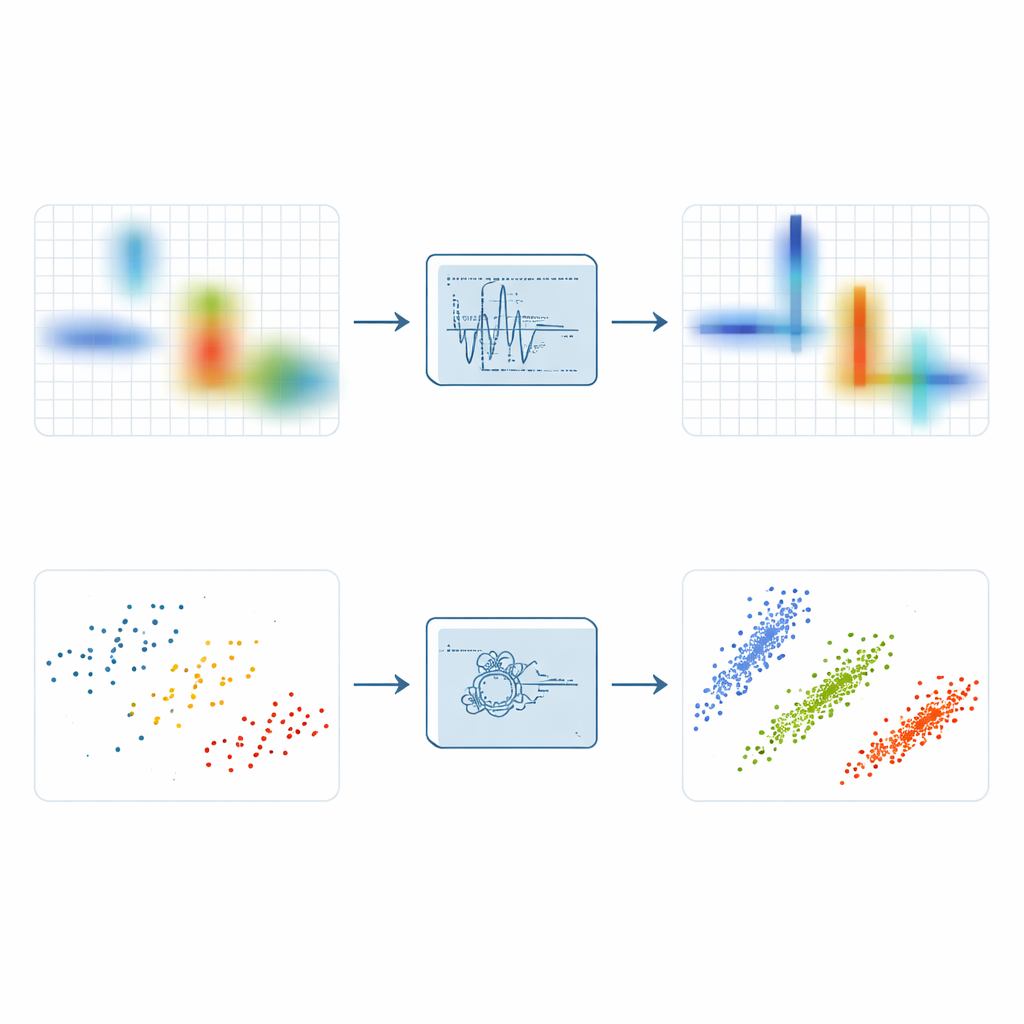
Por qué importa más allá de la teoría
Para no especialistas, la conclusión clave es que los autores han encontrado una mejor manera de observar y agrupar señales enmarañadas para que cada flujo original pueda recuperarse con mayor claridad. Al centrarse en picos locales en el paisaje tiempo‑frecuencia y combinar esta visión con una estrategia de agrupamiento más cuidadosa, su método hace que el problema imposible del café—muchas voces, pocos oídos—sea un poco más resoluble. Este avance podría beneficiar aplicaciones que van desde enlaces satelitales que deben separar transmisiones superpuestas, hasta sistemas médicos que necesitan aislar señales biológicas débiles enterradas en ruido, ofreciendo información más clara a partir de las mismas mediciones limitadas.
Cita: Li, X., Li, Z., Yao, R. et al. Source signal sparsity enhancement based on local maximum synchronous extraction transform algorithm for mixed matrix estimation in UBSS. Sci Rep 16, 9378 (2026). https://doi.org/10.1038/s41598-026-40055-y
Palabras clave: separación ciega de fuentes, esparsidad de la señal, análisis tiempo‑frecuencia, algoritmos de agrupamiento, comunicaciones inalámbricas