Clear Sky Science · es
Generación de novo y cribado in silico de candidatos peptídicos antidiabéticos mediante un marco de atención y aprendizaje profundo con fusión de características fisicoquímicas
Por qué importa diseñar péptidos más inteligentes para la diabetes
La diabetes afecta a cientos de millones de personas en todo el mundo y los fármacos actuales no funcionan perfectamente para todos. Muchos tratamientos pierden eficacia con el tiempo o provocan efectos secundarios. Una opción prometedora son los llamados péptidos antidiabéticos, una clase de pequeñas proteínas que pueden ajustar la glucemia con gran precisión. El desafío es que descubrir nuevos péptidos en el laboratorio es lento y caro. Este estudio presenta una canalización impulsada por ordenador que puede inventar y cribar un gran número de péptidos potenciales antidiabéticos, orientando a los investigadores hacia los candidatos más prometedores para probar en el mundo real.
De péptidos diabéticos conocidos a datos iniciales limpios
Los investigadores empezaron reuniendo una colección de alta calidad de péptidos que se ha demostrado experimentalmente que afectan la glucemia, principalmente influyendo en hormonas como el GLP-1 o en enzimas como la DPP-IV. Estos formaron los ejemplos “positivos”. A continuación construyeron un conjunto “negativo” emparejado de péptidos sin actividad antidiabética reportada, cuidadosamente seleccionados para que la longitud, composición y química básica se parecieran a los positivos. Para evitar engañar al modelo con casi duplicados, usaron herramientas de similitud de secuencias para asegurarse de que péptidos estrechamente relacionados nunca aparecieran tanto en los grupos de entrenamiento como en los de prueba. Esta división con conciencia de homología garantizó que el sistema se juzgara por su capacidad para reconocer patrones genuinamente nuevos en lugar de memorizar otros ya vistos.
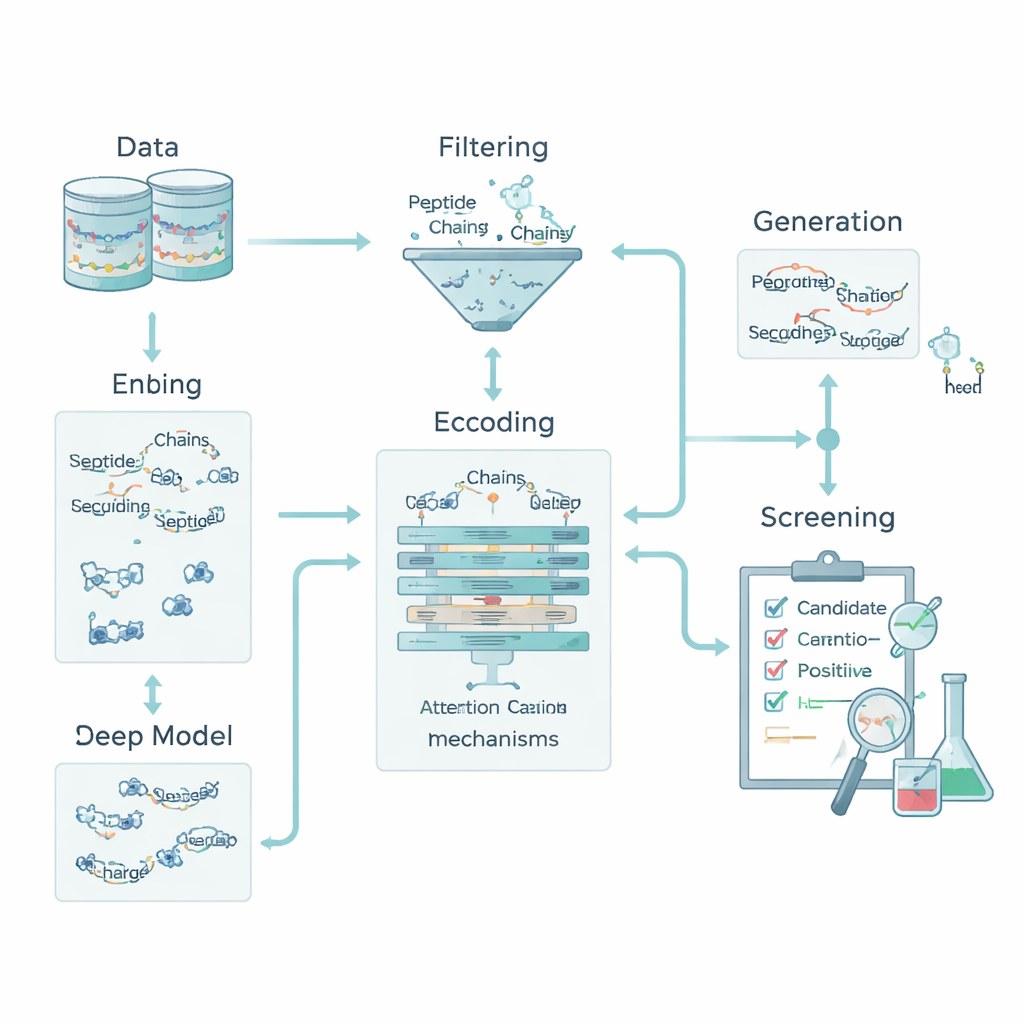
Codificar la química para que las máquinas lean péptidos
Para un ordenador, un péptido es solo una cadena de letras que representan aminoácidos. Para conectar esas letras con la biología, el equipo transformó cada aminoácido en cinco rasgos químicos básicos: cuánto repele al agua, su carga eléctrica, su tendencia a formar enlaces de hidrógeno, su masa y si tiene un anillo aromático. Esto convirtió cada péptido en una pequeña “imagen” que captura tanto el orden como la química. Además, añadieron descriptores a nivel de péptido entero, como la carga global, la hidrofobicidad media y el índice de Boman, que se relaciona con la tendencia del péptido a unirse a otras proteínas. En conjunto, estas características permiten que el modelo examine tanto patrones locales —motivos cortos de aminoácidos— como propiedades globales que influyen en el comportamiento del péptido en el organismo.
Un motor de aprendizaje profundo que explica sus decisiones
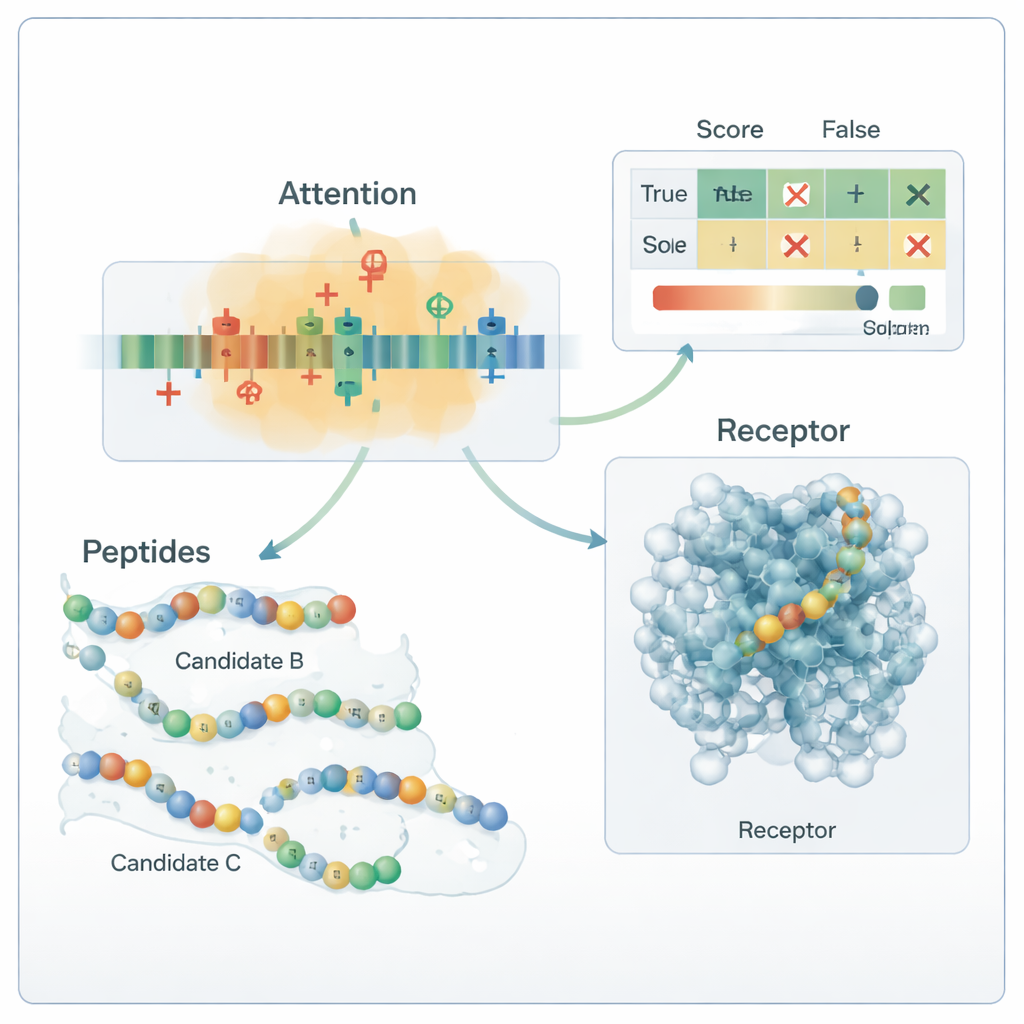
El núcleo de la canalización es un modelo híbrido de aprendizaje profundo. Una red neuronal convolucional (CNN) recorre el péptido en busca de motivos cortos que suelen aparecer en péptidos activos, de forma similar a los filtros en un sistema de reconocimiento de imágenes. Sobre esto, una capa de atención aprende qué posiciones en la secuencia son más importantes, capturando relaciones a larga distancia entre residuos distantes. La salida de este motor de secuencia se fusiona con los descriptores químicos globales y se pasa a varios clasificadores estándar de aprendizaje automático—máquinas de vector soporte, árboles de decisión, k-vecinos más cercanos y árboles potenciados por gradiente. Un método de optimización especializado, llamado OptimizedTPE, ajusta automáticamente sus parámetros, equilibrando la precisión y el riesgo de sobreajuste. El mecanismo de atención también proporciona “mapas de importancia” a nivel de residuo, ayudando a los científicos a ver qué partes de cada péptido impulsan las decisiones del modelo.
Inventar nuevos candidatos evitando la filtración de datos
Para superar el número reducido de péptidos antidiabéticos conocidos, el equipo añadió una etapa de generación que solo alimenta el proceso de entrenamiento. Usaron una mezcla de estrategias—mutación guiada, recombinación de motivos y un autoencoder variacional—para proponer nuevas secuencias que se asemejan, pero no copian, péptidos activos conocidos. Estos candidatos se sometieron luego a estrictas “puertas de descriptores” que imponen cargas, tamaños y propensión de unión realistas, además de herramientas externas que puntúan la similitud con péptidos bioactivos conocidos. Solo se conservan como positivos débilmente etiquetados para entrenamiento las secuencias que pasan estos filtros y permanecen claramente distintas de todos los péptidos de prueba; ninguna se utiliza jamás para evaluar el modelo. Este enfoque amplió el conjunto de entrenamiento manteniendo un banco de pruebas limpio e imparcial.
Qué tan bien funciona el sistema y qué significa
Cuando se puso a prueba con un panel completamente independiente de 180 péptidos estudiados experimentalmente recogidos de la literatura reciente, el marco etiquetó correctamente aproximadamente 99 de cada 100 secuencias, con precisión y recuperación cerca de 0,99. En términos prácticos, eso significa que rara vez pasa por alto un verdadero péptido antidiabético y rara vez clasifica como prometedor a un péptido inactivo. Los análisis de los mapas de atención y las pruebas de mutación mostraron que el modelo ha aprendido reglas químicamente sensatas: depende en gran medida de residuos cargados positivamente y de ciertos residuos hidrofóbicos conocidos por ser importantes para la unión a dianas relacionadas con la diabetes. Simulaciones de acoplamiento molecular sugirieron además que algunos de los péptidos recién generados pueden establecer contactos plausibles con el receptor humano GLP-1. Aunque estas predicciones aún requieren confirmación en el laboratorio, el estudio demuestra una forma reproducible y biológicamente fundamentada de explorar el vasto espacio de posibles fármacos peptídicos y priorizar los pocos que tienen más probabilidades de ayudar a controlar la diabetes.
Cita: Asl, Z.R., Rezaee, K., Ansari, M. et al. De novo generation and in silico screening of anti-diabetic peptide candidates via a deep learning–attention framework with physicochemical feature fusion. Sci Rep 16, 6580 (2026). https://doi.org/10.1038/s41598-026-39985-4
Palabras clave: péptidos antidiabéticos, aprendizaje profundo, descubrimiento de fármacos, diseño de péptidos, receptor GLP-1