Clear Sky Science · es
R-GAT: clasificación de documentos sobre cáncer aprovechando una red residual basada en grafos para escenarios con datos limitados
Por qué importa clasificar los artículos sobre cáncer
Cada día, los científicos publican cientos de estudios nuevos sobre el cáncer, desde la detección temprana hasta fármacos prometedores. La mayor parte de este trabajo aparece primero como resúmenes breves denominados abstracts. Médicos, investigadores y responsables de políticas no pueden leerlos todos, y pasar por alto un artículo importante puede frenar el progreso. Este estudio aborda una pregunta sencilla pero poderosa: ¿es posible construir un sistema informático rápido y ligero que ordene automáticamente abstracts relacionados con el cáncer por tipo de cáncer, incluso cuando solo hay una cantidad modesta de datos etiquetados y recursos de cálculo disponibles?
Una forma más inteligente de leer la investigación sobre cáncer
Los autores se centran en cuatro tipos de abstracts presentes en la base de datos PubMed: los relativos a cáncer de tiroides, cáncer de colon, cáncer de pulmón y temas biomédicos más generales. Crearon una colección cuidadosamente verificada de 1.875 abstracts recientes, aproximadamente equilibrada entre estos cuatro grupos. Este equilibrio ayuda a evitar sesgos hacia un tipo de cáncer concreto. Antes de cualquier modelado, los textos se limpiaron: las palabras se tokenizaron, se revisó la ortografía, se consolidaron formas relacionadas y se eliminaron términos poco informativos. Los abstracts limpiados se convirtieron después en forma numérica usando varios métodos estándar para que distintos tipos de modelos pudieran compararse de manera justa.
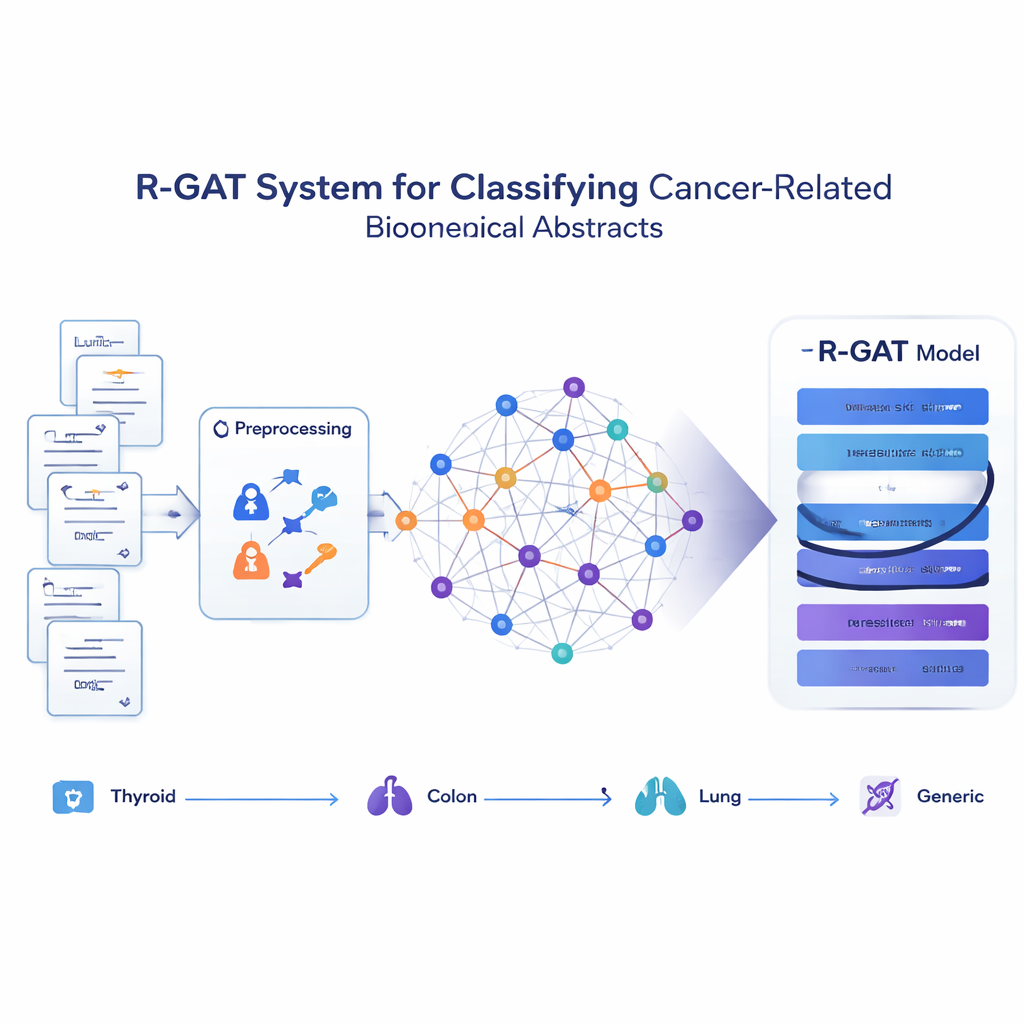
Convertir los artículos en una red de ideas
En lugar de tratar cada abstract como una cadena aislada de palabras, el método propuesto, llamado R-GAT (Residual Graph Attention Network), considera la colección entera como una red. En esa red, cada abstract es un nodo y las conexiones representan cuán similares son dos abstracts en contenido. Si dos artículos tratan temas estrechamente relacionados, el enlace entre ellos es fuerte; si no, es débil o inexistente. Esto permite que el modelo analice un abstract en el contexto de sus vecinos, imitando cómo un lector humano puede entender mejor un estudio sabiendo lo que dicen trabajos relacionados.
Cómo aprende el nuevo modelo a partir de los vecinos
R-GAT se basa en dos ideas clave de la inteligencia artificial moderna: atención y conexiones residuales. La atención permite que el modelo se centre más en los abstracts vecinos más relevantes de la red, en lugar de tratar a todos los vecinos por igual. Múltiples "cabezas" de atención buscan a la vez distintos tipos de patrones. Las conexiones residuales actúan como atajos que transmiten información a través de las capas profundas de la red, ayudando al modelo a no perder señales importantes mientras aprende. Tras procesar el grafo mediante varias capas de atención y estos caminos de atajo, el sistema condensa la información de toda la red en un resumen compacto que se alimenta a un clasificador final que predice a cuál de las cuatro categorías pertenece cada abstract.
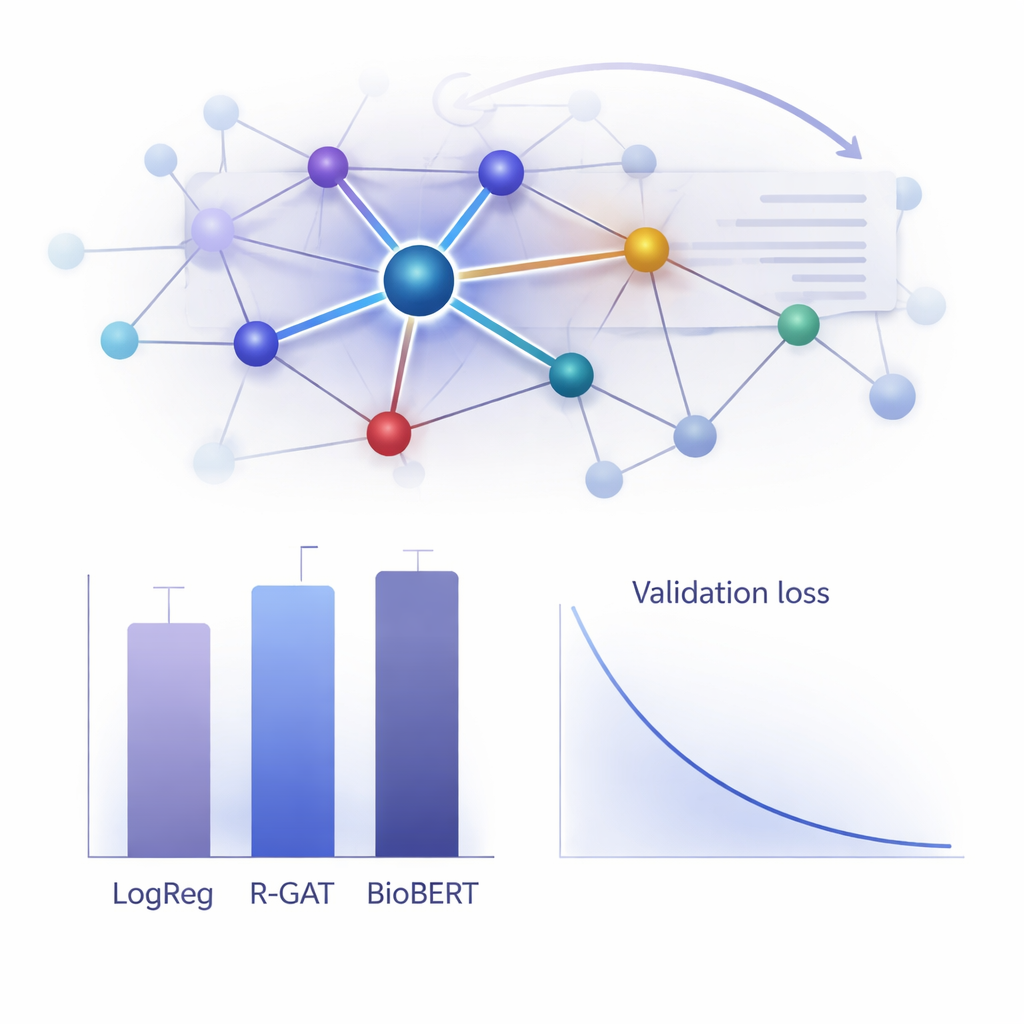
¿Qué tan bien funciona en la práctica?
Para evaluar el valor de R-GAT, los autores lo compararon con una amplia gama de alternativas, desde modelos lineales clásicos hasta sistemas transformadores de última generación como BioBERT, que son populares pero exigentes a nivel computacional. Sorprendentemente, un modelo simple de regresión logística con características de recuento de palabras obtuvo la mejor puntuación bruta en este conjunto de datos concreto, y BioBERT también rindió de forma excelente; pero ambos tuvieron inconvenientes, incluida la dependencia de elecciones específicas de características o la necesidad de recursos computacionales considerables. R-GAT alcanzó una puntuación macro F1 de aproximadamente 0,96, cercana a la de los mejores modelos, mostrando a la vez resultados muy estables a través de distintas particiones de entrenamiento y prueba. Pruebas cuidadosas en las que se quitaron la atención o las conexiones residuales mostraron caídas claras en el rendimiento, lo que confirma que ambos ingredientes son cruciales para la robustez del modelo cuando los datos son limitados.
Qué significa esto para la investigación futura sobre el cáncer
Para un público general, la conclusión es clara: R-GAT es una herramienta práctica que ayuda a clasificar artículos de investigación sobre cáncer por tipo con alta y consistente precisión, sin necesitar conjuntos de datos enormes ni hardware costoso. No reemplaza a los modelos de lenguaje más potentes del mercado, pero ofrece un punto intermedio fiable, especialmente útil para hospitales, grupos de investigación o equipos de salud pública que necesitan resultados reproducibles y dependientes con restricciones de datos y presupuesto. Al publicar tanto su modelo como su conjunto de datos curado de forma abierta, los autores también proporcionan un referente compartido que otros pueden usar para construir y probar sistemas mejorados. A largo plazo, estas herramientas podrían facilitar que los expertos se mantengan al día de la literatura sobre cáncer y traduzcan nuevos hallazgos en mejores cuidados.
Cita: Hossain, E., Nuzhat, T., Masum, S. et al. R-GAT: cancer document classification leveraging graph-based residual network for scenarios with limited data. Sci Rep 16, 6582 (2026). https://doi.org/10.1038/s41598-026-39894-6
Palabras clave: informática del cáncer, minería de texto biomédico, clasificación de documentos, redes neuronales de grafos, aprendizaje con datos limitados