Clear Sky Science · es
Aprendizaje automático para predecir estadios de enfermedad renal crónica en pacientes con enfermedad renal poliquística autosómica dominante: un estudio de cohorte nacional en Japón
Por qué esto importa para la salud cotidiana
La enfermedad renal a menudo avanza de forma silente, y cuando aparecen los síntomas el daño puede ser difícil de revertir. Para las personas nacidas con enfermedad renal poliquística autosómica dominante (ERPAD) —una condición en la que sacos llenos de líquido desplazan lentamente el tejido renal normal— conocer la velocidad a la que pueden fallar sus riñones puede condicionar decisiones vitales. Este estudio explora si técnicas informáticas modernas, conocidas como aprendizaje automático, pueden utilizar los datos de reconocimientos médicos rutinarios para pronosticar cómo cambiará la función renal de una persona en los próximos tres años, sin depender de costosas pruebas genéticas o exploraciones avanzadas.
Una enfermedad frecuente con futuros inciertos
La ERPAD es uno de los trastornos renales heredados más comunes y una causa principal de enfermedad renal crónica (ERC). Muchas personas afectadas acaban necesitando diálisis o un trasplante, pero la velocidad del deterioro varía ampliamente. Algunas progresan despacio y mantienen una función renal razonable hasta la vejez; otras alcanzan insuficiencia renal en sus cuarenta o cincuenta años. Los médicos desearían clasificar a los pacientes en grupos de riesgo de forma temprana, para adaptar el tratamiento y el seguimiento. Las herramientas de predicción existentes a menudo dependen de pruebas genéticas detalladas o de resonancias magnéticas completas de los riñones, que no están disponibles de forma rutinaria en muchos sistemas de salud, incluido el programa nacional de seguro de Japón. Esa laguna motivó a los autores a buscar una forma más simple y de uso general para estimar el estadio futuro de la ERC.
Convertir un registro nacional en una herramienta de predicción
Los investigadores se basaron en un registro nacional japonés que recoge información de personas con enfermedades de difícil tratamiento que reciben apoyo gubernamental. Se centraron en 2.737 adultos con ERPAD que se registraron por primera vez entre 2015 y 2021. Para cada persona, el equipo recopiló datos de la solicitud inicial —incluyendo resultados de análisis de sangre, hallazgos en orina, medidas corporales básicas, presión arterial y tamaño renal registrado por el médico— y luego examinó el estadio de ERC de esa persona tres años después. El estadio de ERC, que se basa principalmente en la capacidad de filtración renal, sirve tanto como marcador de gravedad de la enfermedad como criterio clave para la asistencia financiera en Japón.
Cómo aprendieron las computadoras a partir de datos de pacientes
Para construir su sistema de predicción, los científicos probaron tres métodos comunes de aprendizaje automático: bosque aleatorio (random forest), máquina de vectores de soporte (support vector machine) y naïve Bayes. Los tres aprenden a partir de ejemplos en lugar de fórmulas fijas. El conjunto de datos se dividió en una porción de entrenamiento, usada para afinar cada modelo, y una porción de prueba, usada para comprobar el rendimiento de los modelos finales en casos no vistos. Las computadoras intentaron predecir a qué uno de varios estadios de ERC llegaría cada paciente tras tres años. El método de bosque aleatorio, que combina muchos “árboles” de decisión simples en un comité de votación, mostró el mejor rendimiento, prediciendo correctamente el estadio en alrededor del 73% de los pacientes de prueba. La máquina de vectores de soporte, que asume sobre todo relaciones lineales entre factores y resultado, obtuvo un desempeño menor, mientras que el modelo naïve Bayes simple quedó en un punto intermedio.
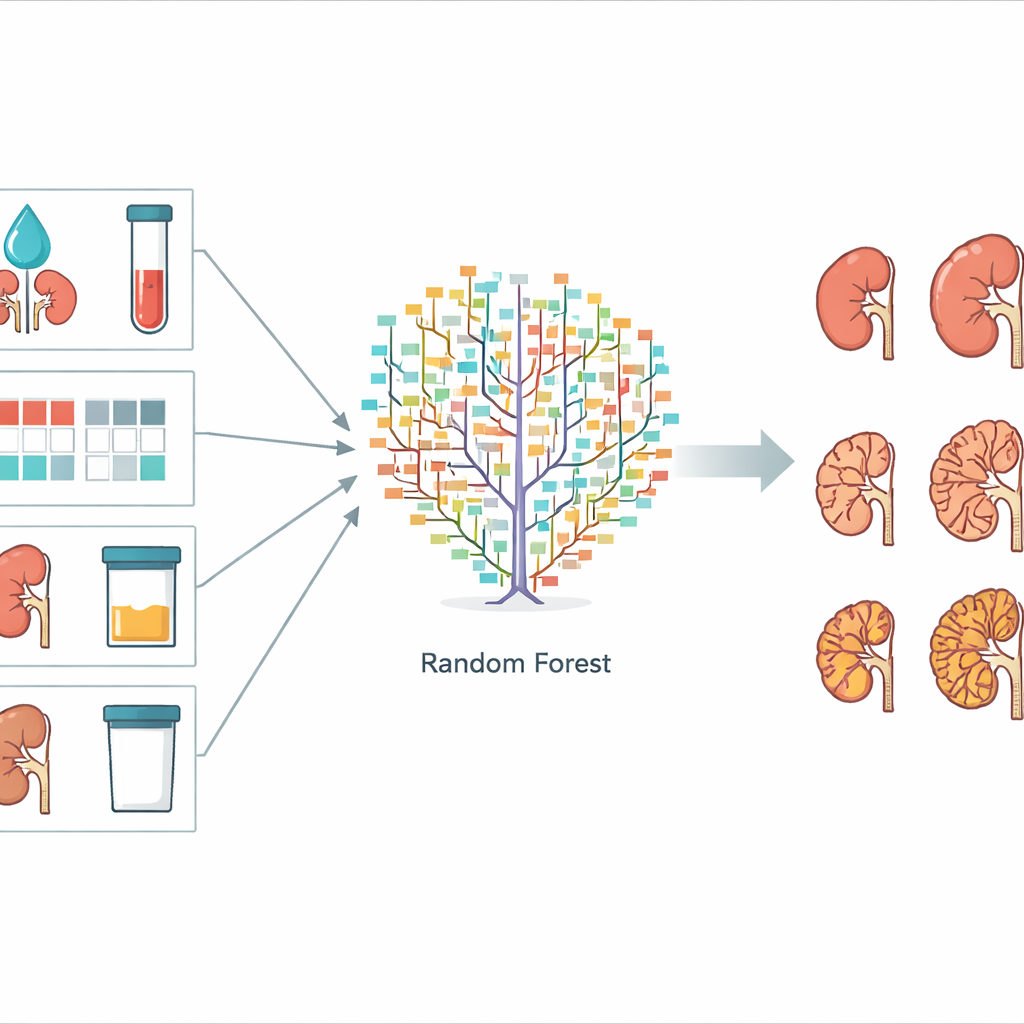
Qué fue lo más importante para la predicción
El equipo también analizó qué piezas de información fueron más útiles para el modelo de bosque aleatorio. Midieron esto mezclando (barajando) un factor a la vez y observando cuánto empeoraban las predicciones. Cinco características destacaron como especialmente importantes: la tasa de filtración estimada de los riñones (eTFG), el nivel de creatinina en sangre (otro marcador de la función renal), un “mapa de calor” codificado por colores de la ERC que combina filtración y hallazgos de proteína en orina, la cantidad de proteína en orina y el volumen total de ambos riñones. Todas estas son medidas que pueden recogerse en visitas de clínica ordinarias, sin archivos de imagen especializados ni secuenciación genética. Otros elementos, como el número exacto de quistes observados en las exploraciones, contribuyeron poco, lo que sugiere que no son esenciales para una herramienta de predicción práctica.
Qué significa esto para pacientes y médicos
Para las personas que viven con ERPAD, el estudio sugiere que un modelo informático cuidadosamente entrenado, alimentado con análisis de laboratorio estándar y resúmenes básicos de imagen, puede ofrecer un pronóstico razonablemente preciso de la salud renal dentro de tres años. Dado que el modelo de mejor rendimiento puede captar relaciones complejas y no lineales entre factores, puede ser más adecuado que las tablas de riesgo tradicionales para esta enfermedad variable y de por vida. Aunque el trabajo se limita a pacientes japoneses y no puede demostrar causalidad, apunta hacia herramientas amigables para la clínica que ayudan a identificar quién probablemente empeore rápido y quién puede tener un curso más lento. En términos claros, el artículo concluye que el aprendizaje automático —especialmente el enfoque de bosque aleatorio— puede convertir datos médicos cotidianos en vistas previas individualizadas del futuro renal, apoyando una atención más personalizada y una mejor planificación para pacientes con ERPAD.
Cita: Shimada, Y., Kataoka, H., Nishio, S. et al. Machine learning for predicting CKD stages in patients with autosomal dominant polycystic kidney disease: a nationwide cohort study in Japan. Sci Rep 16, 8771 (2026). https://doi.org/10.1038/s41598-026-39885-7
Palabras clave: enfermedad renal poliquística, enfermedad renal crónica, aprendizaje automático, predicción de riesgo, medicina personalizada