Clear Sky Science · es
EchoNet++: un conjunto de datos multilingüe de comentarios de audio de partidos de fútbol
Por qué importa el sonido del fútbol
Cualquiera que haya visto un gran partido sabe que el rugido de la multitud y el vaivén de la voz del comentarista son parte integral del drama tanto como los goles. Sin embargo, casi toda la tecnología deportiva moderna sigue centrada en lo que ven las cámaras, no en lo que oyen los micrófonos. Este artículo presenta EchoNet y EchoNet++, un sistema y un conjunto de datos combinados que convierten el sonido caótico de las retransmisiones profesionales de fútbol de muchos países en texto limpio y buscable que los ordenadores pueden analizar. Eso hace posible estudiar tácticas, emoción y narración a través de ligas e idiomas a una escala que ningún equipo humano de traductores podría igualar.
Del estadio ruidoso a la señal limpia
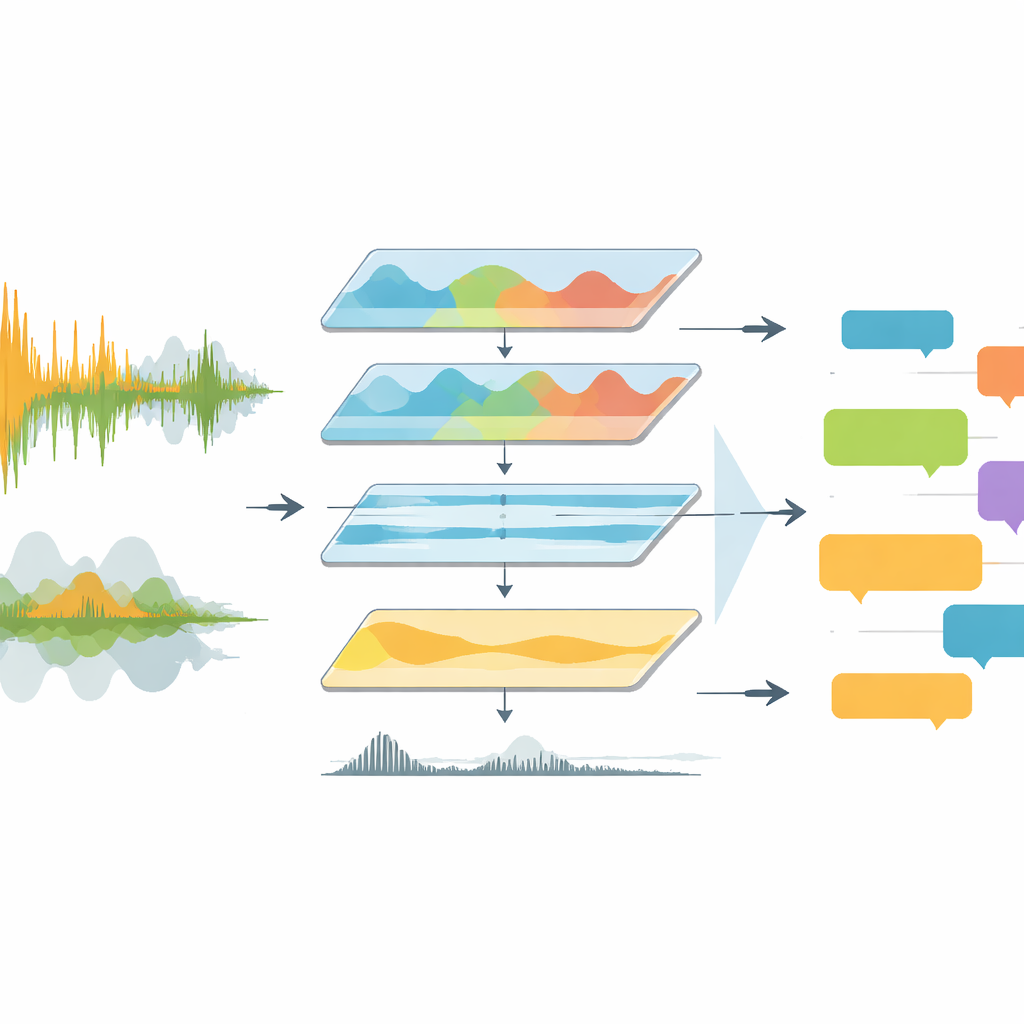
Los partidos televisados son acústicamente desordenados. Los comentaristas hablan sobre cánticos de aficionados, música del estadio y explosiones súbitas de vítores. Las herramientas previas solían enviar este ruido bruto directamente a software de reconocimiento de voz, que tenía problemas con voces superpuestas, cambios de idioma y mala calidad de audio. EchoNet aborda el problema como una canalización de ingeniería en lugar de un único modelo ingenioso. Comienza extrayendo la pista de audio de los vídeos de partido completo y convirtiéndola a un formato estándar y de alta calidad. A continuación el sistema pasa al dominio de la frecuencia, centrando la atención en el rango donde reside la voz humana mientras suprime graves retumbantes y artefactos agudos. Una herramienta de aprendizaje profundo llamada Demucs separa además los sonidos similares a la voz del resto, dejando una pista mucho más clara para que las etapas posteriores la interpreten.

Enseñar a las máquinas a distinguir voces del ruido
Una vez que el sonido está limpio, EchoNet debe decidir cuándo alguien está realmente hablando y si esa voz pertenece al comentarista o a la multitud. Para ello, los autores usan un detector neuronal de actividad de voz que analiza el audio en ventanas cortas y etiqueta cada instante como habla o no habla. Los fragmentos de habla detectados se examinan luego con mayor detalle. Los segmentos que muestran el ritmo y la estructura constantes del lenguaje hablado se etiquetan como comentarios, mientras que los que parecen estallidos de energía caótica se etiquetan como espectadores. Esta separación importa: las frases del comentarista transmiten significado táctico y narrativo, mientras que las reacciones de la multitud señalan principalmente picos emocionales como goles o ocasiones claras. Al dividir estas fuentes, el sistema puede tratarlas de forma diferente en los análisis posteriores.
Convertir muchos idiomas en una sola historia
EchoNet alimenta cada segmento de comentario a varias versiones del modelo de reconocimiento automático de voz Whisper, incluidas variantes estándar y optimizadas para velocidad. Estos modelos se entrenan con cientos de miles de horas de audio multilingüe, lo que los hace adecuados para las principales ligas europeas, donde las retransmisiones alternan entre inglés, alemán, español, italiano, francés y otros idiomas. El sistema registra la sincronización, el idioma y la transcripción de cada segmento en archivos JSON estructurados vinculados a las mitades del partido. Para los fragmentos en idiomas no ingleses, EchoNet primero transcribe en el idioma original y luego envía el texto a un motor de traducción para obtener versiones en inglés. Este diseño en dos pasos mantiene separados los errores de transcripción y traducción, lo que ayuda a los investigadores a depurar fallos y comparar el comportamiento específico de cada idioma.
Medir qué tan bien funciona todo
Como una canalización es tan fuerte como su eslabón más débil, los autores evalúan EchoNet desde varios ángulos. Introducen una nueva puntuación de “Precisión de Informe” que convierte las tasas de error de palabra tradicionales en un porcentaje más intuitivo de contenido prácticamente correcto. En tres conjuntos de datos, incluido su nuevo conjunto EchoNet++ publicado de 20 partidos completos, el preprocesamiento con EchoNet reduce de forma consistente los errores de transcripción y aumenta la Precisión de Informe en varios puntos para cada modelo Whisper probado. Las medidas de calidad de la señal, que estiman qué tan comprensible sería el habla para un oyente humano, también mejoran notablemente tras el filtrado, la denoización y la normalización. Estudios de ablación, en los que se eliminan componentes individuales como el filtro de paso de banda o el detector de voz, muestran que cada etapa contribuye de forma significativa tanto a la claridad como a la corrección.
Qué significa esto para aficionados y analistas
En términos cotidianos, EchoNet y EchoNet++ ofrecen una manera fiable de convertir horas de comentarios multilingües y ruidosos en texto limpio alineado en el tiempo e indicadores de la multitud. Con esta base, los desarrolladores pueden detectar automáticamente eventos clave a partir del tono y las palabras del comentarista, emparejar esos momentos con picos en la reacción de la grada y crear resúmenes detallados o recopilaciones de lo más destacado sin registro manual. Crucialmente, el conjunto de datos y el código se publican para uso investigativo, ofreciendo a la comunidad una plataforma compartida y reproducible para estudiar el fútbol a través del sonido. Para aficionados y analistas por igual, este trabajo empuja la cobertura deportiva hacia un futuro en el que la banda sonora del partido sea tan rastreable y analizables como el vídeo mismo.
Cita: Majeed, F., Nazir, M., Agus, M. et al. EchoNet++: A multilingual soccer match audio commentary dataset. Sci Rep 16, 8884 (2026). https://doi.org/10.1038/s41598-026-39884-8
Palabras clave: analítica del fútbol, audio deportivo, reconocimiento de voz, comentarios multilingües, análisis de transmisiones