Clear Sky Science · es
Llevando la validación cruzada al mundo real para evaluar la transferibilidad de modelos de vegetación basados en satélite
Por qué importa vigilar el pasto desde el espacio
Los pastizales alimentan al ganado, sostienen la vida silvestre y almacenan carbono, y muchos ganaderos y conservacionistas ahora dependen de los satélites para controlar cuánta materia vegetal hay en el suelo. Los nuevos mapas prometen vistas casi en tiempo real de las condiciones del pasto, pero su precisión en años atípicos—como sequías severas o temporadas muy húmedas—a menudo se da por supuesta. Este estudio plantea una pregunta simple pero crucial: ¿qué tan bien resisten los modelos informáticos detrás de estos mapas por satélite cuando el mundo real se niega a parecerse a los datos con que fueron entrenados?
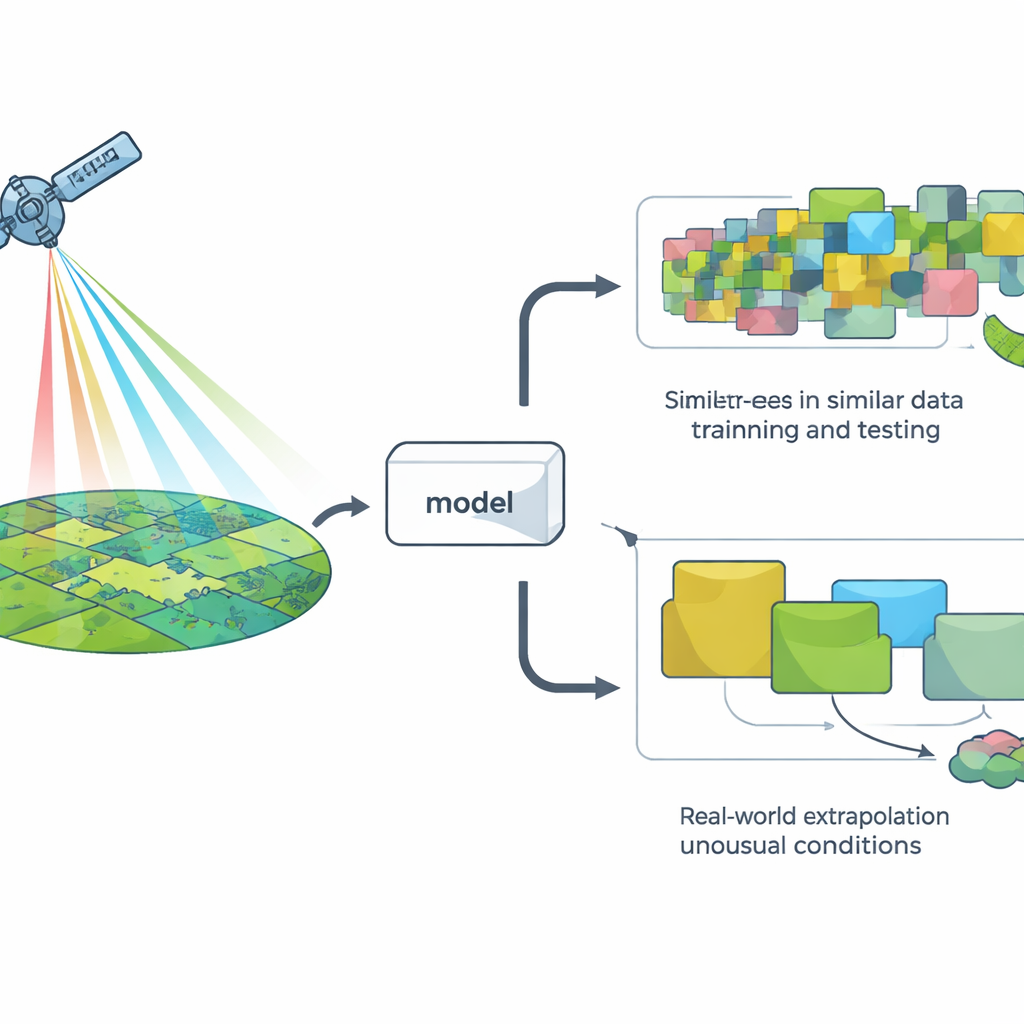
Evaluar modelos de la manera fácil frente a la difícil
Para juzgar un modelo, los investigadores suelen usar un método llamado validación cruzada: ocultan algunos datos, entrenan el modelo con el resto y ven qué tan bien predice los puntos ocultos. La versión más común divide los datos al azar, lo que funciona bien para muchos problemas pero asume en silencio que todas las observaciones son independientes. En los paisajes, esa suposición suele fallar: lugares cercanos y años vecinos tienden a parecerse desde el espacio. Como resultado, las divisiones aleatorias pueden hacer que parezca que un modelo se enfrenta a situaciones “nuevas” cuando en realidad está viendo más de lo mismo.
Poner a prueba los modelos satelitales en condiciones reales
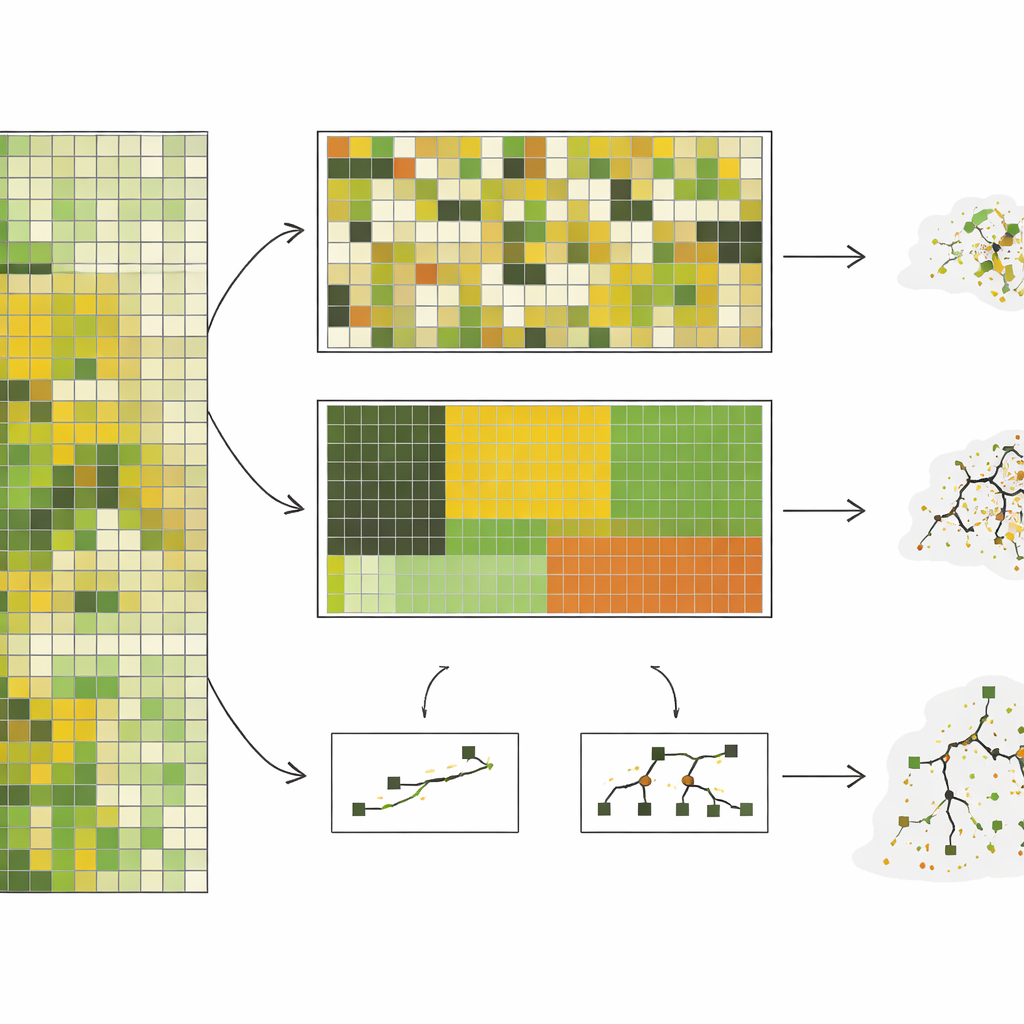
Los autores reunieron casi 10.000 mediciones sobre el terreno de biomasa herbácea en pie—esencialmente cuánto material vegetal aprovechable hay—de una estepa de pasto corto en Colorado, recogidas durante 10 años. Emparejaron estas mediciones con imágenes satelitales detalladas y luego entrenaron siete tipos diferentes de modelos informáticos, que van desde enfoques lineales simples hasta sistemas complejos de árboles de decisión. En lugar de usar solo divisiones aleatorias, probaron cinco formas de dejar datos fuera: por parcelas elegidas al azar, por bloques de pastura, por tipo de sitio ecológico, por año y por agrupaciones de píxeles que parecían espectralmente distintas. Estas dos últimas aproximaciones, especialmente agrupar por año y por clústeres espectrales, obligaron a los modelos a predecir condiciones que eran realmente diferentes a las que habían visto antes.
Cuando el futuro no se parece al pasado
En general, el rendimiento de los modelos cayó bruscamente a medida que las pruebas se volvían más exigentes. Con la división aleatoria, modelos complejos como los bosques aleatorios parecían impresionantes, explicando alrededor de tres cuartas partes de la variación en la biomasa. Pero cuando se les pidió que predijeran para un año totalmente no observado—una tarea realista para el monitoreo casi en tiempo real—su precisión disminuyó, y modelos relativamente simples basados en un puñado de variables satelitales combinadas rindieron igual o mejor. En la prueba más extrema, donde los datos se agruparon para ser lo más diferentes posible entre sí, la precisión de los modelos complejos colapsó, mientras que los mejores modelos simples mantuvieron un rendimiento moderado y más predecible. El estudio también mostró que los modelos complejos eran muy sensibles a si condiciones raras, como sequías severas, estaban representadas en los datos de entrenamiento, a veces desempeñándose muy mal en esos escenarios de alto riesgo.
Caballos de trabajo estables vencen a velocistas vistosos
Más allá de la precisión absoluta, el equipo examinó qué tan consistente era cada modelo al volver a entrenarlo con subconjuntos de años ligeramente diferentes. Los métodos más simples, especialmente la regresión por mínimos cuadrados parciales, tendían a identificar una y otra vez las mismas señales satelitales clave, necesitaban solo unas pocas decisiones de ajuste y producían resultados más estables a lo largo de los años. Los enfoques más complejos a menudo cambiaban las entradas de las que dependían, requerían muchas configuraciones de ajuste distintas y mostraban grandes oscilaciones en el rendimiento de una ejecución de entrenamiento a otra. Para los gestores del territorio que deben actualizar mapas cada año a medida que llegan nuevos datos, este tipo de estabilidad puede ser tan importante como la máxima precisión en un año favorable.
Qué implica esto para usar mapas satelitales en el terreno
Para las personas que dependen de mapas de vegetación basados en satélite para decidir cuándo y dónde pastorear, reaccionar ante sequías o seguir la salud del ecosistema, este estudio transmite un mensaje claro. Las prácticas de prueba comunes que barajan los datos al azar pueden pintar una imagen demasiado optimista de cómo funcionará un modelo cuando el tiempo cambie a extremos o cuando se aplique en lugares nuevos. Cuando los modelos se evalúan de maneras que imitan su uso en el mundo real—prediciendo años nuevos, nuevos entornos ecológicos o condiciones pocas veces vistas—métodos más simples y bien comportados pueden superar a los sofisticados y ofrecer una guía más fiable. En la práctica, eso significa que los desarrolladores deberían informar cómo se comportan sus modelos bajo varias pruebas más exigentes y realistas, y los usuarios deberían buscar productos cuya actuación haya sido verificada en los tipos de situaciones desafiantes que es más probable que enfrenten.
Cita: Kearney, S.P., Augustine, D.J., Porensky, L.M. et al. Bringing cross-validation into the real world to evaluate transferability of satellite-based vegetation models. Sci Rep 16, 9383 (2026). https://doi.org/10.1038/s41598-026-39866-w
Palabras clave: mapeo de vegetación por satélite, validación cruzada, biomasa de pastizales, modelos de aprendizaje automático, monitoreo de sequías