Clear Sky Science · es
Reconocimiento de lugares robusto ante cambios de iluminación usando pseudo-LiDAR a partir de imágenes omnidireccionales
Robots que nunca se pierden en la oscuridad
Imagínese un robot capaz de reconocer su posición dentro de un edificio, ya sea al mediodía con el sol entrando por las ventanas o a altas horas de la noche con solo unas pocas lámparas encendidas. Este artículo presenta una nueva forma de dotar a los robots de ese sentido de lugar fiable usando únicamente una cámara relativamente económica. Al convertir imágenes planas en información 3D, los investigadores logran que la navegación robótica sea mucho menos sensible a sombras, deslumbramientos y otros cambios de iluminación que suelen confundir a los sistemas basados en visión.
Por qué es difícil encontrar el mismo lugar dos veces
Para un robot, “reconocimiento de lugar” significa darse cuenta de “ya estuve aquí antes”, de modo que pueda localizarse en un mapa y navegar con seguridad. Los sistemas tradicionales se basan bien en cámaras convencionales o en sensores de distancia por láser conocidos como LiDAR. Las cámaras son baratas y capturan color y textura ricos, pero su apariencia varía drásticamente entre escenas nubladas, soleadas o nocturnas. El LiDAR es mucho más estable porque mide la distancia directamente, pero es voluminoso y caro. Algunos robots combinan varios sensores, pero eso aumenta el precio y la complejidad. Los autores de este trabajo siguen otra vía: mantienen el hardware simple, usando solo una cámara omnidireccional que ve todo alrededor del robot, y mejoran el software para que el robot razone sobre la estructura 3D en lugar de la mera apariencia.
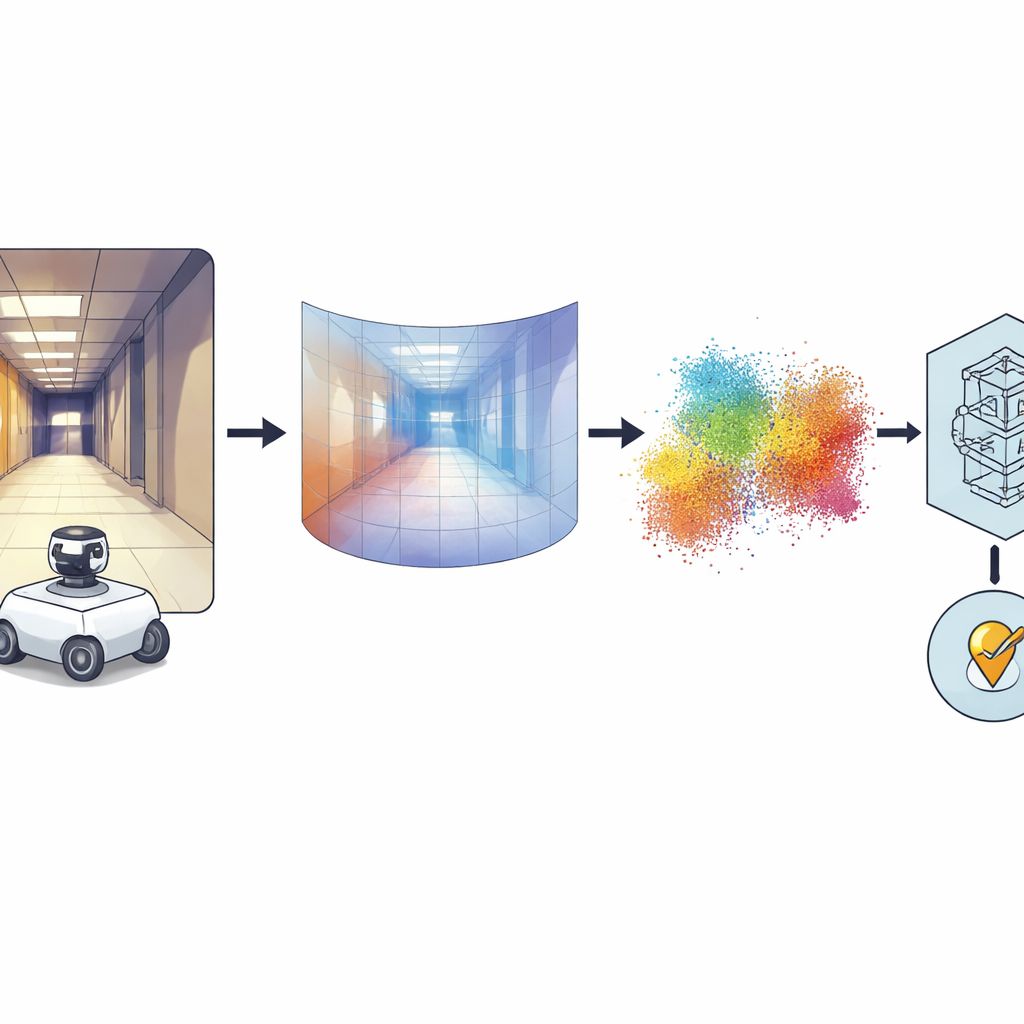
De fotos panorámicas a formas 3D
La idea clave es convertir cada imagen panorámica en un mapa denso de profundidad, donde cada píxel codifica qué tan lejos está esa parte de la escena respecto a la cámara. Para ello los autores se apoyan en un potente modelo “fundacional” llamado Distill Any Depth, que ha aprendido a inferir profundidad a partir de enormes colecciones de imágenes. El mapa de profundidad resultante se transforma luego en una nube de puntos 3D—una especie de LiDAR virtual, o pseudo-LiDAR—sin necesidad de un escáner láser real. Procesos adicionales limpian artefactos introducidos por el espejo especial usado en la cámara de 360 grados, rellenando regiones faltantes u ocultas. Finalmente, una red neuronal llamada MinkUNeXt, diseñada para trabajar directamente sobre nubes de puntos 3D, comprime cada nube en una huella compacta que captura la disposición global del lugar.
Enseñar al sistema a ignorar trucos de iluminación
Las estimaciones de profundidad no son perfectas, especialmente cuando la iluminación cambia drásticamente de un momento a otro. Para hacer el sistema robusto, los investigadores introducen un nuevo truco de entrenamiento que denominan Distilled Depth Variations. En lugar de confiar en un único modelo de profundidad, mezclan deliberadamente predicciones de profundidad procedentes de varias versiones más pequeñas y menos precisas del estimador de profundidad. Este “ruido” controlado imita los tipos de distorsiones que aparecen bajo distintas condiciones de iluminación, obligando a la red 3D a aprender qué es lo realmente importante de la geometría de un lugar y qué se puede ignorar de forma segura. También enriquecen cada punto 3D con información sobre bordes de imagen y fuerza de textura—características que tienden a ser más estables frente a cambios de iluminación que el color puro.
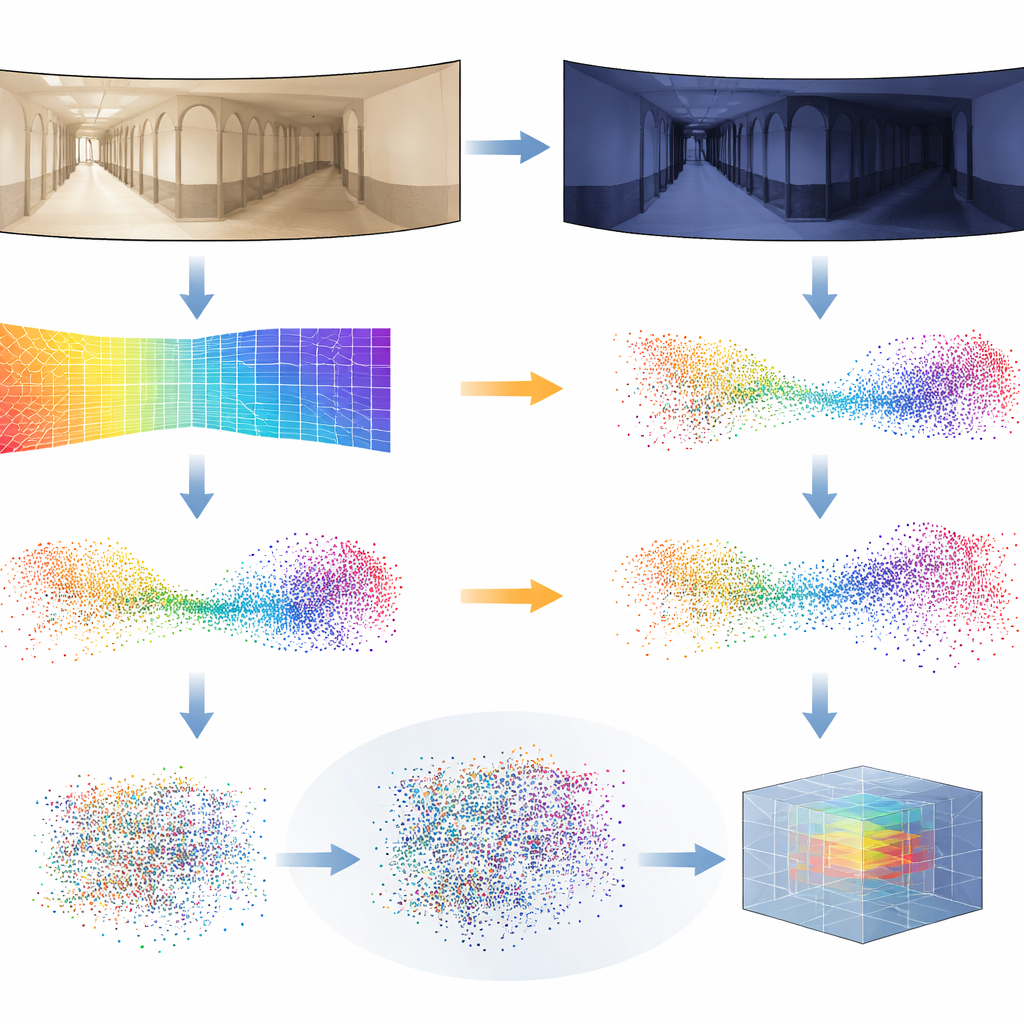
Demostrar que funciona en el mundo real
Para probar su enfoque, el equipo recurrió a exigentes conjuntos de datos públicos de recorridos interiores con robots. En estas colecciones, un robot recorre pasillos y habitaciones varias veces bajo día nublado, sol brillante y de noche, mientras muebles y personas se mueven. Los autores entrenaron su sistema usando solo imágenes nubladas de un edificio y luego lo evaluaron en todos los edificios y condiciones de iluminación, incluidas escenas que nunca había visto. Su método de pseudo-LiDAR igualó o superó de forma consistente a técnicas líderes basadas en imágenes 2D y a otros sistemas 3D, especialmente en los casos más difíciles como recorridos nocturnos o transferencias a entornos totalmente nuevos. También mostraron que la misma canalización funciona con cámaras frontales ordinarias, no solo con panorámicas, sustituyendo la proyección adecuada de la profundidad a 3D.
Qué significa esto para los robots del futuro
En términos prácticos, este trabajo demuestra que un robot puede adquirir una conciencia del entorno similar a la del LiDAR usando solo una cámara y software inteligente. Al centrarse en la estructura 3D en lugar de los detalles cambiantes de la iluminación y el color, el sistema puede reconocer lugares de forma fiable entre día, noche y cambios meteorológicos, manteniendo el hardware sencillo y asequible. Esto podría hacer que la navegación interior robusta sea más accesible para robots de servicio, vehículos de almacén y dispositivos asistivos, y abre la puerta a sistemas futuros que integren profundidad con comprensión de escena de mayor nivel para una autonomía aún más fiable.
Cita: Cabrera, J.J., Alfaro, M., Gil, A. et al. Robust place recognition under illumination changes using pseudo-LiDAR from omnidirectional images. Sci Rep 16, 8817 (2026). https://doi.org/10.1038/s41598-026-39848-y
Palabras clave: localización de robots, visión 3D, reconocimiento de lugares, estimación de profundidad, cámaras omnidireccionales