Clear Sky Science · es
Una nueva integración de transformador entre variables y descomposición de señales para la predicción en tiempo real del nivel de los ríos: una implicación para la gestión sostenible de los recursos hídricos
Vigilando los ríos que protegen las ciudades costeras
Para millones de personas que viven a lo largo de los deltas fluviales, un aumento repentino del agua puede significar hogares inundados, cultivos dañados y ciudades paralizadas. Sin embargo, muchos ríos en riesgo, sobre todo en regiones pobres o remotas, carecen de las medidas detalladas de meteorología y caudal que suelen exigir las herramientas modernas de predicción. Este estudio presenta una nueva forma de prever diariamente los niveles de los ríos usando únicamente lecturas pasadas del propio nivel del agua, ofreciendo una vía prometedora para mejorar la preparación ante inundaciones en zonas con escasez de datos.
Por qué los registros simples de los ríos no son tan simples
Los niveles de los ríos suben y bajan bajo la influencia de mareas, precipitaciones, presas aguas arriba e incluso patrones climáticos lejanos. Estos vaivenes producen series temporales que parecen ruidosas e irregulares, con picos bruscos durante tormentas o mareas altas. Los modelos tradicionales suelen necesitar muchos insumos distintos —lluvia, temperatura, evaporación y más— y se ven superados cuando solo están disponibles registros del nivel del agua. En el río Rupsa‑Pasur de Bangladés, que atraviesa las ciudades costeras de Khulna y Mongla, esta es exactamente la situación: riesgo elevado de inundación, pero datos de apoyo limitados. Los autores se propusieron responder a una cuestión práctica: ¿podemos aún así hacer predicciones en tiempo real y con alta precisión del nivel diario del agua cuando solo disponemos de una única serie histórica irregular?
Dividir una señal compleja en piezas manejables
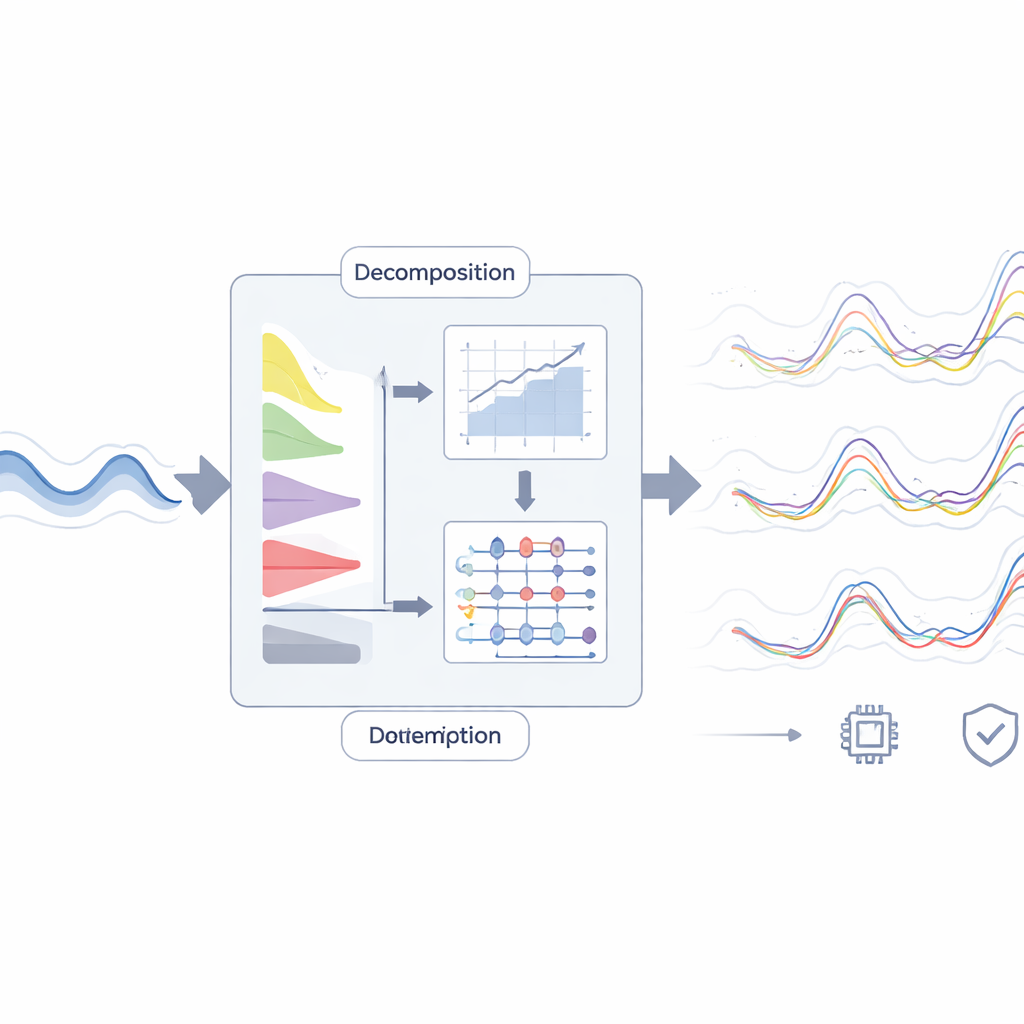
Los investigadores abordan este reto prestando primero más atención a la historia del río. En lugar de alimentar la serie cruda de niveles directamente a un modelo predictivo, aplican métodos avanzados de descomposición de señales. Estos métodos separan el registro original en varias sub‑señales más suaves, cada una capturando patrones en distintas escalas temporales —desde oscilaciones rápidas diarias hasta cambios estacionales más lentos— además de un residuo restante. Se prueban cinco técnicas, incluida una reciente llamada descomposición sucesiva de modos variacionales, diseñada para extraer componentes claros incluso con datos ruidosos. Estas piezas descompuestas actúan como un conjunto más rico de pistas, creado a partir de la única variable disponible.
Un nuevo motor de aprendizaje para el comportamiento fluvial
Para aprender de estas pistas, el equipo usa un modelo de pronóstico moderno conocido como CLIENT, que combina dos ideas. Una parte es un modelo lineal simple y rápido que sigue las tendencias generales del nivel del agua. La otra parte es un módulo transformador —un tipo de arquitectura de aprendizaje profundo muy usado en modelos de lenguaje— que sobresale en detectar relaciones sutiles entre características de entrada. Antes de comenzar el aprendizaje, un paso de normalización reversible suaviza los desplazamientos del nivel global de la serie temporal y los restaura al final, ayudando a que el modelo se mantenga estable con el tiempo. Al alimentar a CLIENT tanto con los niveles diarios recientes como con las sub‑señales descompuestas, los autores construyen seis versiones del modelo y las comparan con herramientas más habituales como redes neuronales, redes LSTM y árboles de decisión.
¿Qué tan bien podemos predecir el nivel del río para el día siguiente?
Probado en las estaciones de Khulna y Mongla, el enfoque híbrido rinde de forma notable. Todas las versiones de CLIENT mejoradas con descomposición reducen los errores de predicción frente a modelos que solo usan los niveles diarios recientes. La combinación estrella es la que utiliza la descomposición sucesiva de modos variacionales, etiquetada C6 en el estudio. En ambas estaciones, este modelo reproduce casi todas las oscilaciones diarias observadas y capta con gran precisión los eventos extremos de crecida, logrando puntuaciones de habilidad cercanas a la perfección manteniendo un tiempo de cálculo moderado. Los autores someten luego al mismo modelo a pruebas rigurosas en tres ríos muy distintos de Bangladés y Estados Unidos, con múltiples particiones de entrenamiento‑prueba, y encuentran que sigue prediciendo de forma fiable, incluso cuando los registros de datos son relativamente cortos o muy variables.
Del código de investigación a alertas de inundación prácticas
Para ir más allá de la teoría, el equipo empaqueta su mejor modelo en una interfaz informática interactiva. Los usuarios pueden subir una hoja de cálculo sencilla con niveles diarios pasados y recibir predicciones para el día siguiente, con el pesado trabajo matemático oculto bajo el capó. Porque el método depende únicamente de registros del nivel del agua —a menudo el dato hidrológico más disponible— abre la puerta a que más comunidades, sobre todo en regiones costeras en desarrollo, accedan a pronósticos fluviales oportunos. En términos sencillos, el estudio muestra que, al reconfigurar y aprender inteligentemente a partir de una única corriente de mediciones, podemos construir herramientas rápidas y precisas que ayudan a planificadores, ingenieros y residentes a detectar niveles peligrosos con un poco más de antelación y actuar antes de que lleguen las inundaciones.
Cita: Ratul, M., Akter, U., Mollick, T. et al. A novel integration of cross variable transformer and signal decomposition for real-time prediction of river water level: an implication for sustainable water resources management. Sci Rep 16, 9366 (2026). https://doi.org/10.1038/s41598-026-39591-4
Palabras clave: predicción del nivel del río, riesgo de inundación, aprendizaje automático, descomposición de series temporales, costa de Bangladés