Clear Sky Science · es
Detección automatizada de fotorreceptores cónicos mediante datos sintéticos y aprendizaje profundo en imágenes AOSLO con óptica adaptativa confocal
Vistas más nítidas del ojo vivo
Ver las células fotosensibles del ojo una por una podría transformar la manera en que los médicos detectan y siguen las enfermedades que causan ceguera. Pero hoy en día, los expertos deben marcar estas células a mano en imágenes muy ampliadas de la retina, un proceso lento, subjetivo y difícil de escalar a miles de pacientes. Este estudio muestra cómo modelos informáticos entrenados con imágenes “falsas” realistas del ojo pueden aprender a encontrar estas células automáticamente, abriendo la puerta a revisiones oculares más rápidas y fiables y a una mejor evaluación de nuevos tratamientos.
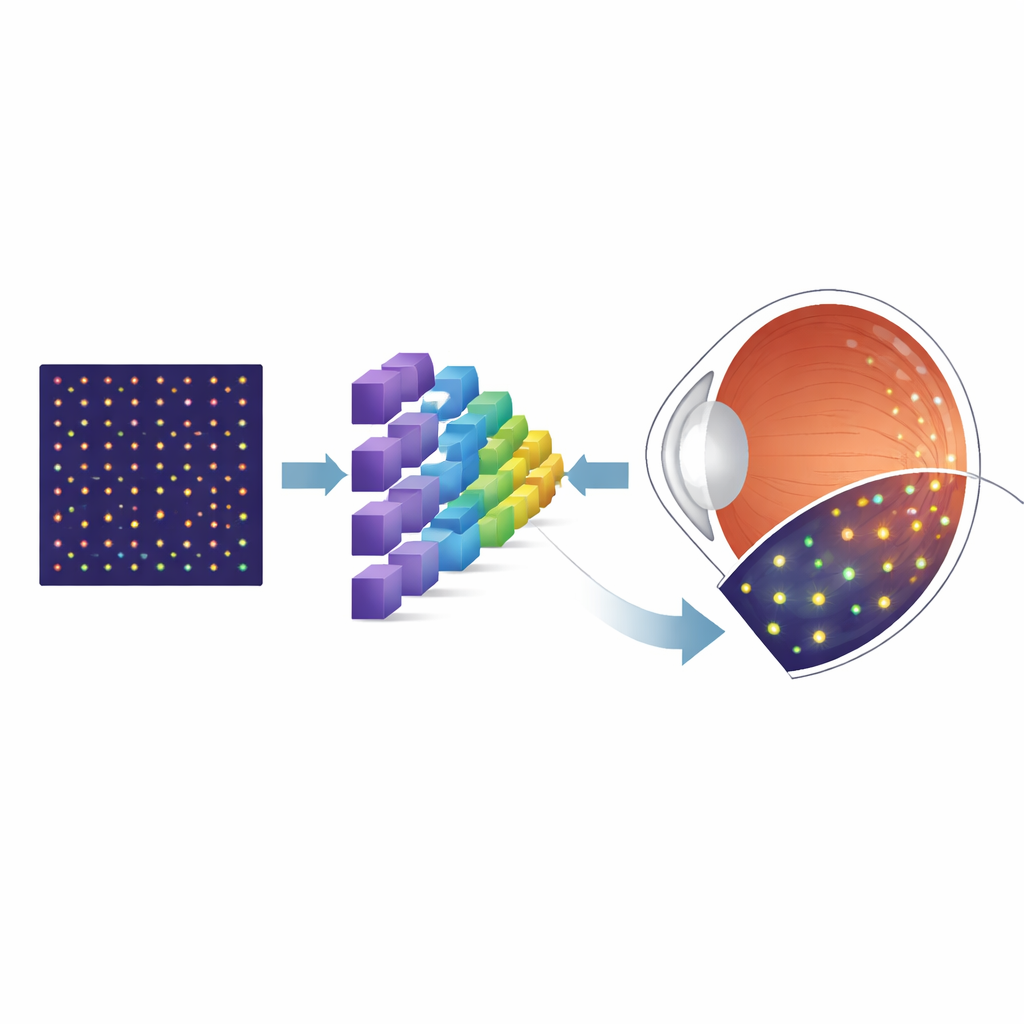
Por qué importan las células diminutas
La parte posterior del ojo está revestida por fotorreceptores: células especializadas que convierten la luz en las señales que nuestro cerebro interpreta como visión. Los fotorreceptores cónicos, en particular, son esenciales para la visión central nítida y la percepción del color, y su pérdida es una característica de muchas enfermedades retinianas. Una potente tecnología de imagen llamada oftalmoscopia láser de exploración con óptica adaptativa (AOSLO) puede capturar imágenes detalladas de estas células en personas vivas. Sin embargo, antes de que médicos e investigadores puedan medir la densidad de conos o seguir cambios con el tiempo, deben primero localizar cada cono individual en la imagen. La marcación manual no solo lleva mucho tiempo, sino que también puede variar entre personas, lo que limita su utilidad en clínicas de rutina y en grandes ensayos.
De reglas hechas a mano a aprender de los datos
Programas informáticos anteriores intentaron automatizar la detección de conos siguiendo reglas fijas: por ejemplo, buscando manchas brillantes de cierto tamaño o separación. Estos métodos basados en reglas podían funcionar bien en imágenes limpias de ojos sanos, pero a menudo tenían problemas cuando las imágenes estaban ruidosas, ligeramente desenfocadas o procedían de pacientes con enfermedad. El aprendizaje profundo ofrece una estrategia diferente. En lugar de diseñar reglas a mano, una red neuronal aprende patrones directamente a partir de ejemplos. El inconveniente es que estos modelos suelen necesitar enormes cantidades de imágenes que ya han sido etiquetadas cuidadosamente por expertos, precisamente el tipo de dato que es escaso y caro en imágenes AOSLO.
Construyendo un campo de entrenamiento virtual
Para sortear la escasez de imágenes reales etiquetadas, los investigadores recurrieron a una herramienta de simulación llamada ERICA, que puede generar imágenes AOSLO realistas de mosaicos de conos junto con un “ground truth” perfecto sobre la ubicación de cada cono. Crearon grandes conjuntos de estas imágenes sintéticas que abarcan muchas posiciones en la retina, variando sistemáticamente imperfecciones clave que afectan las imágenes reales, como ruido aleatorio y desenfoque óptico sutil. Luego entrenaron una arquitectura de red neuronal especializada, conocida como U-Net, para transformar cada imagen de entrada en un mapa de probabilidad que muestra dónde es más probable que estén los conos. Tras este entrenamiento inicial con datos sintéticos, el equipo afinó el modelo usando una colección mucho más pequeña de imágenes AOSLO reales de un conjunto público bien conocido, y finalmente lo probaron en imágenes independientes de otro laboratorio para evaluar su capacidad de generalización.

Qué tan bien coincide el ordenador con los expertos humanos
El equipo comparó su método automatizado con la marcación manual meticulosa y con dos algoritmos líderes de detección de conos. Usando una medida estándar de solapamiento entre las marcas de conos predichas y las manuales, la nueva U-Net igualó o casi igualó el rendimiento de los calificadores expertos y de los métodos automatizados competidores en el conjunto de datos público. De manera crucial, al probarse en un conjunto separado de imágenes tomadas a distintas distancias del centro de la visión y recogidas con otro instrumento, el modelo siguió rindiendo muy bien. Esto sugiere que entrenar de forma intensiva con datos sintéticos que cubren una amplia gama de condiciones visuales ayudó a la red a aprender características que se transfieren a imágenes del mundo real, en lugar de ajustarse en exceso a una cámara o grupo de pacientes concretos.
Qué podría significar esto para la atención ocular futura
Para el público general, el mensaje central es que un programa informático entrenado en gran medida con imágenes “virtuales” del ojo puede ahora encontrar conos reales en exploraciones retinianas de alta resolución con una fiabilidad similar a la de expertos humanos. Al hacer la detección de conos más rápida, objetiva y fácil de aplicar entre distintos escáneres y clínicas, este enfoque podría ayudar a convertir la imagen retiniana detallada en una herramienta de uso rutinario para el seguimiento de enfermedades a nivel de células individuales. A largo plazo, métodos similares impulsados por datos sintéticos podrían extenderse para detectar otros tipos celulares y modelar la pérdida de células relacionada con enfermedades, apoyando diagnósticos más tempranos, un mejor seguimiento de la progresión y una evaluación más precisa de nuevos tratamientos destinados a preservar la vista.
Cita: Shah, M., Young, L.K., Downes, S.M. et al. Automated cone photoreceptor detection using synthetic data and deep learning in confocal adaptive optics scanning laser ophthalmoscope images. Sci Rep 16, 8313 (2026). https://doi.org/10.1038/s41598-026-39570-9
Palabras clave: imagen retiniana, fotorreceptores cónicos, aprendizaje profundo, datos sintéticos, óptica adaptativa