Clear Sky Science · es
Un marco adaptable de reequilibrio de datos para la predicción en tiempo real del riesgo de tráfico
Por qué importa equilibrar los datos de tráfico para la seguridad
Los accidentes en autopista son eventos poco frecuentes en comparación con la gran cantidad de conducción ordinaria y sin incidentes. Eso es una buena noticia para la seguridad, pero crea un problema oculto para los sistemas informáticos que intentan predecir cuándo y dónde podrían ocurrir choques en tiempo real. Cuando los datos están dominados por situaciones seguras, los algoritmos pueden volverse muy buenos en predecir “no pasará nada” y seguir pareciendo precisos sobre el papel, mientras fallan silenciosamente en detectar los momentos realmente peligrosos. Este estudio aborda ese desequilibrio de frente, proponiendo una forma adaptable de “reequilibrar” los datos de tráfico para que los sistemas de alerta reconozcan mejor condiciones de riesgo raras pero importantes sin volverse demasiado lentos para su uso en el mundo real.
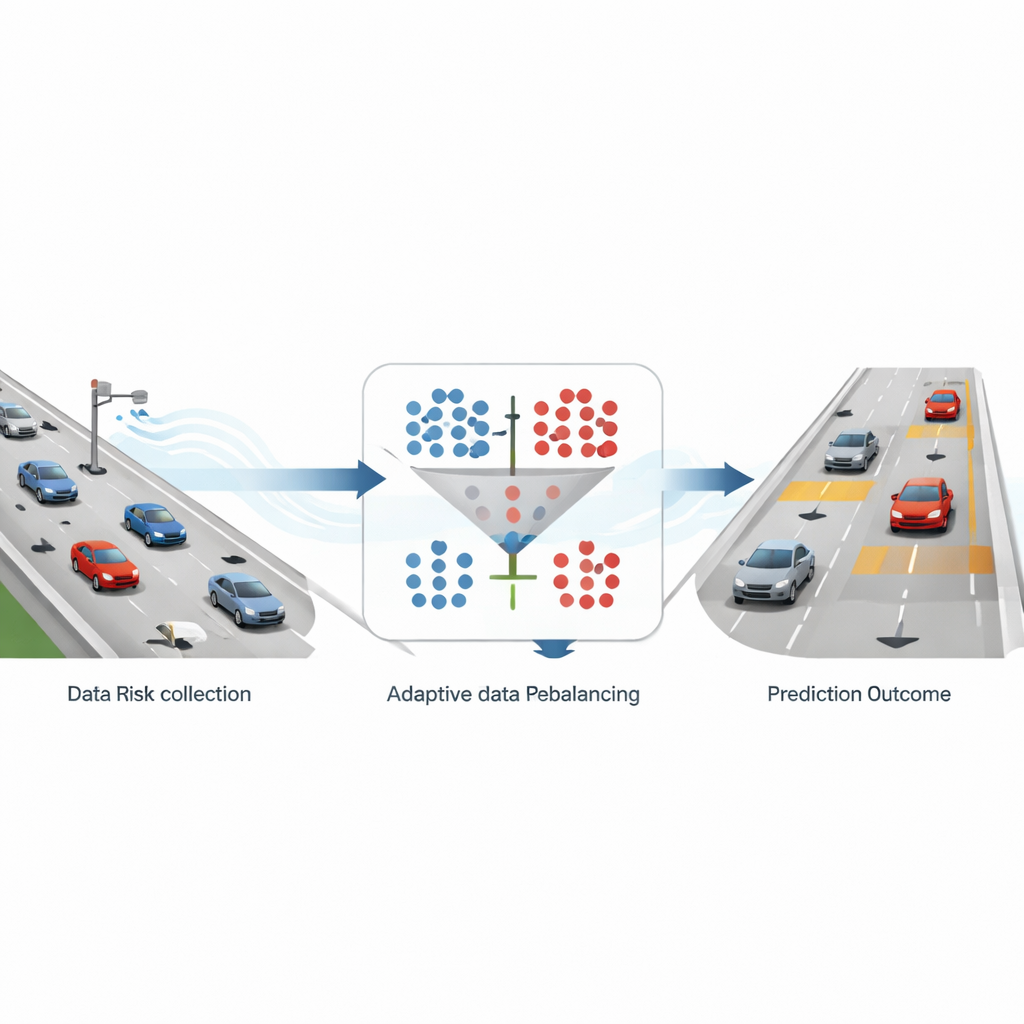
Cómo se convierte el tráfico real en señales de alerta
Los investigadores construyen su marco sobre datos detallados de trayectorias en autopista procedentes de un gran conjunto de datos tomado por drones y registrado en autopistas alemanas. La posición y la velocidad de cada vehículo se rastrean muchas veces por segundo a lo largo de segmentos de seis carriles. A partir de este rico registro de movimiento, el equipo calcula un indicador de seguridad ampliamente usado llamado tiempo hasta la colisión, que estima cuánto tardaría un vehículo que sigue a otro en chocar si ambos continuaran igual. Cuando este tiempo cae por debajo de tres segundos, la situación se etiqueta como “alto riesgo”; en caso contrario se considera “no riesgo”. Tras agregar estas medidas en intervalos de 10 segundos y centrarse en vías de seis carriles, obtienen aproximadamente nueve muestras seguras por cada una de riesgo, un conjunto de datos fuertemente sesgado que refleja las condiciones reales de autopista.
Corregir el sesgo sin perder lo importante
Para abordar este sesgo, el estudio compara dos estrategias comunes. Una, llamada sobremuestreo, añade más ejemplos de situaciones raras y riesgosas creando muestras sintéticas similares a casos reales de alto riesgo. La otra, submuestreo, reduce la gran cantidad de casos seguros descartando aleatoriamente algunos de ellos. Los autores usan un método popular de sobremuestreo (SMOTE) y un método simple de submuestreo aleatorio, aplicándolos en varias proporciones fijas de muestras seguras a riesgosas: 1:1, 2:1, 3:1 y 4:1. Después, alimentan tanto los conjuntos de datos originales como los modificados a cuatro modelos de predicción: dos enfoques tradicionales de aprendizaje automático y dos modelos de aprendizaje profundo especializados en series temporales. Al probar todas estas combinaciones, pueden ver cómo distintas maneras de equilibrar los datos cambian la capacidad del sistema para detectar riesgo sin dejar de reconocer condiciones seguras.
Dejar que un algoritmo busque el punto óptimo
En lugar de asumir que números perfectamente iguales de muestras seguras y riesgosas son los mejores, los investigadores permiten que un algoritmo genético—un método de búsqueda inspirado en la evolución—busque el equilibrio más eficaz. Este optimizador ajusta la proporción seguro-a-riesgo dentro de un rango realista de 1:1 a 4:1, generando repetidamente ratios candidatos, evaluándolos y refinándolos a lo largo de cientos de iteraciones. De forma crucial, no considera solo la precisión de predicción: también tiene en cuenta cuánto tarda el modelo en entrenarse y en hacer predicciones, reflejando las demandas de tiempo real de los centros de control de tráfico. Para asegurar que precisión y tiempo de cómputo puedan combinarse de forma justa, todas las medidas se normalizan antes de fusionarse en una única puntuación de “fitness” que el algoritmo intenta minimizar.
Lo que los modelos aprenden sobre el riesgo en la carretera
A lo largo de los numerosos experimentos, destaca un patrón. Equilibrar los datos mejora la predicción de riesgo en comparación con dejar el sesgo original sin tocar, y el sobremuestreo con casos riesgosos sintéticos tiende a funcionar mejor que desechar casos seguros. Una proporción de 2:1 de muestras seguras a riesgosas ofrece el mejor rendimiento entre las configuraciones fijas, superando la elección 1:1 ampliamente utilizada. Cuando se permite que el algoritmo genético afine esta proporción, se establece en valores ligeramente desiguales pero óptimos—aproximadamente 2,3:1 para sobremuestreo y 2,7:1 para submuestreo. Entre los modelos de predicción, un tipo particular de red neuronal recurrente conocida como gated recurrent unit ofrece de forma consistente los mejores resultados, especialmente cuando se combina con sobremuestreo y optimización. Los modelos también revelan que las velocidades medias de los vehículos aguas arriba y aguas abajo de un punto en la autopista son más informativas para el riesgo que simples recuentos de vehículos.
Comprobar la estabilidad y prepararse para el mundo real
Dado que los métodos de optimización a veces pueden quedar atrapados en soluciones engañosas, los autores examinan cómo se comporta su búsqueda a lo largo del tiempo. Muestran que las puntuaciones de fitness disminuyen de forma constante y finalmente se estabilizan, lo que sugiere que el algoritmo converge a proporciones estables y de alta calidad en lugar de oscilar. Luego ajustan las proporciones elegidas hacia arriba y hacia abajo en unos pocos porcentajes para ver si el rendimiento colapsa. En la práctica, la precisión solo disminuye ligeramente ante pequeños cambios, indicando que el sistema es robusto y no está excesivamente afinado a una única configuración frágil. Sin embargo, cuando la porción de datos reservada para pruebas se vuelve muy grande, los modelos se vuelven más sensibles, lo que subraya la necesidad de datos de entrenamiento suficientemente ricos.
Qué significa esto para autopistas más seguras e inteligentes
En términos cotidianos, el estudio muestra que enseñar a las máquinas a reconocer el peligro en la carretera no es solo cuestión de modelos inteligentes; también se trata de alimentar a esos modelos con una visión justa de eventos raros pero críticos. Al ajustar cuidadosamente cuántos ejemplos seguros y riesgosos se usan en el entrenamiento—y permitiendo que un algoritmo adaptable encuentre el mejor compromiso entre precisión y velocidad—el marco propuesto hace la predicción de riesgo en autopistas en tiempo real más fiable y más práctica. Las agencias de tráfico podrían integrar este enfoque en sistemas que vigilen datos de detectores de tráfico y emitan alertas tempranas sobre probables colisiones por alcance, ayudando a orientar avisos a conductores, despliegue de patrullas o estrategias de frenado automatizado. Si bien el trabajo se demuestra en autopistas alemanas y en buenas condiciones meteorológicas, la idea subyacente del reequilibrio adaptativo de datos ofrece una receta general para mejorar las predicciones de seguridad allá donde los eventos peligrosos sean raros pero demasiado importantes como para pasarlos por alto.
Cita: Chen, S., Cui, B. & Chang, A. An adaptive data rebalancing framework for real-time traffic risk prediction. Sci Rep 16, 8882 (2026). https://doi.org/10.1038/s41598-026-39539-8
Palabras clave: seguridad vial, predicción de riesgo de choques, datos desequilibrados, aprendizaje automático, trayectorias en autopista