Clear Sky Science · es
Un modelo visión‑lenguaje médico 3D eficiente en datos que utiliza solo un codificador 2D
Ayuda más inteligente a partir de exploraciones 3D
Cuando los médicos leen tomografías computarizadas (TC) o resonancias magnéticas (RM), no se limitan a mirar imágenes aisladas: ensamblan mentalmente cientos de cortes para comprender un problema en tres dimensiones. Enseñar a las máquinas a hacer lo mismo podría acelerar los diagnósticos, homogeneizar resultados y generar informes más claros para los pacientes. Pero los sistemas actuales de inteligencia artificial que manejan volúmenes 3D son extremadamente “insaciables” de datos, y necesitan conjuntos grandes y cuidadosamente anotados que muchos hospitales no tienen. Este artículo presenta una forma de obtener comprensión a nivel 3D a partir de tecnología de imagen 2D existente, ofreciendo herramientas potentes más fáciles y baratas de construir y desplegar.
Por qué las exploraciones 3D son difíciles para la IA
Los sistemas modernos visión‑lenguaje ya pueden mirar una imagen médica 2D y responder preguntas o redactar un informe en lenguaje natural. Extender esa capacidad a volúmenes 3D permitiría razonar sobre órganos completos y lesiones sutiles que solo se hacen evidentes cuando se observan muchos cortes juntos. El problema es que la mayoría de los sistemas 3D actuales dependen de codificadores de imagen 3D especiales entrenados desde cero con enormes colecciones de exploraciones anotadas. Esos conjuntos de datos son raros, caros de anotar y, a menudo, provienen de centros bien financiados, lo que limita quién puede beneficiarse. Al mismo tiempo, tratar cada corte como una imagen 2D independiente desperdicia la continuidad natural entre cortes y satura al modelo con información repetitiva.
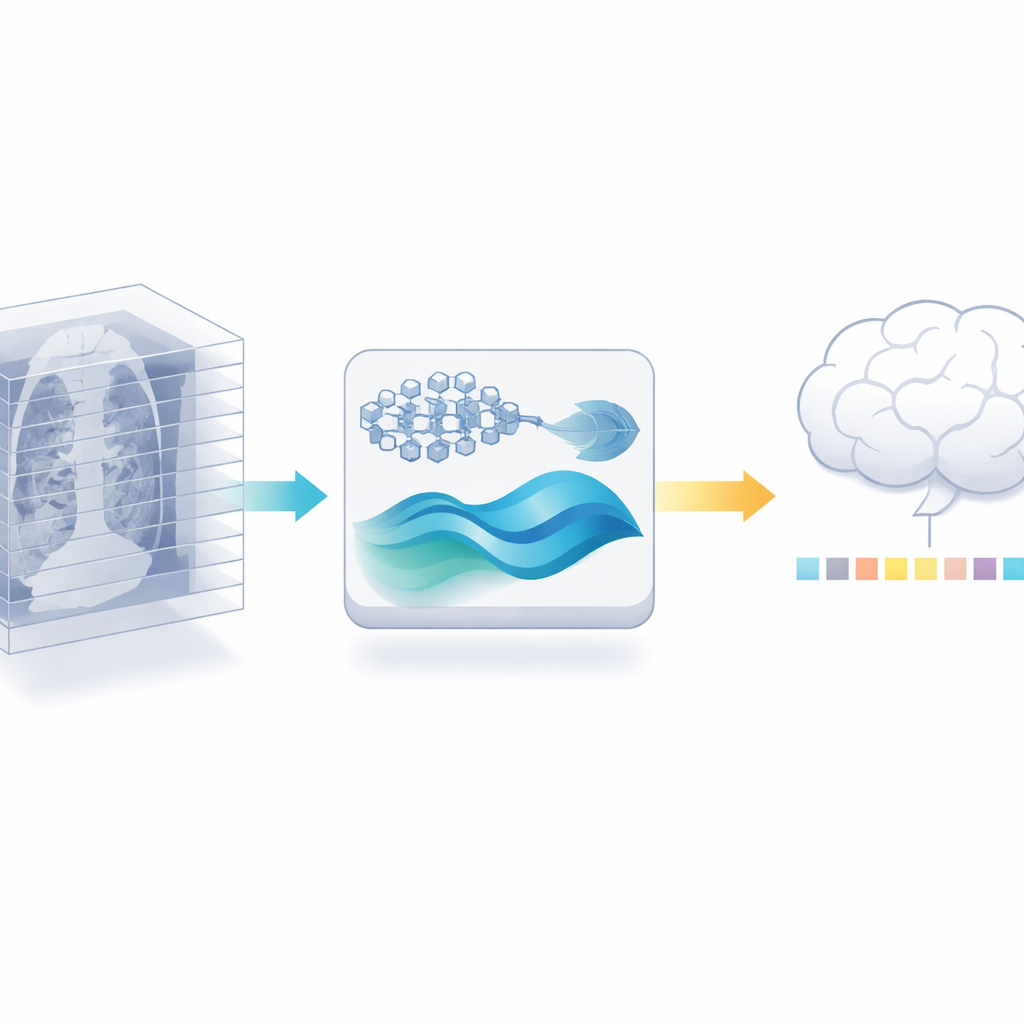
Reciclar a un experto 2D para trabajo 3D
Los autores proponen un camino distinto: en lugar de entrenar un nuevo codificador 3D, reutilizan un potente modelo de imágenes médicas 2D ya entrenado con millones de imágenes anotadas de la literatura médica. Primero dividen cada exploración 3D en sus cortes individuales y dejan que este modelo 2D extraiga características detalladas de cada corte. Luego recortan cuidadosamente la redundancia: dado que los cortes vecinos en una exploración suelen ser muy similares, una comprobación de similitud puede descartar muchos casi‑duplicados mientras conserva las vistas más informativas. Solo este paso reduce la cantidad de datos que deben manejar las etapas posteriores, sin necesidad de más exploraciones anotadas.
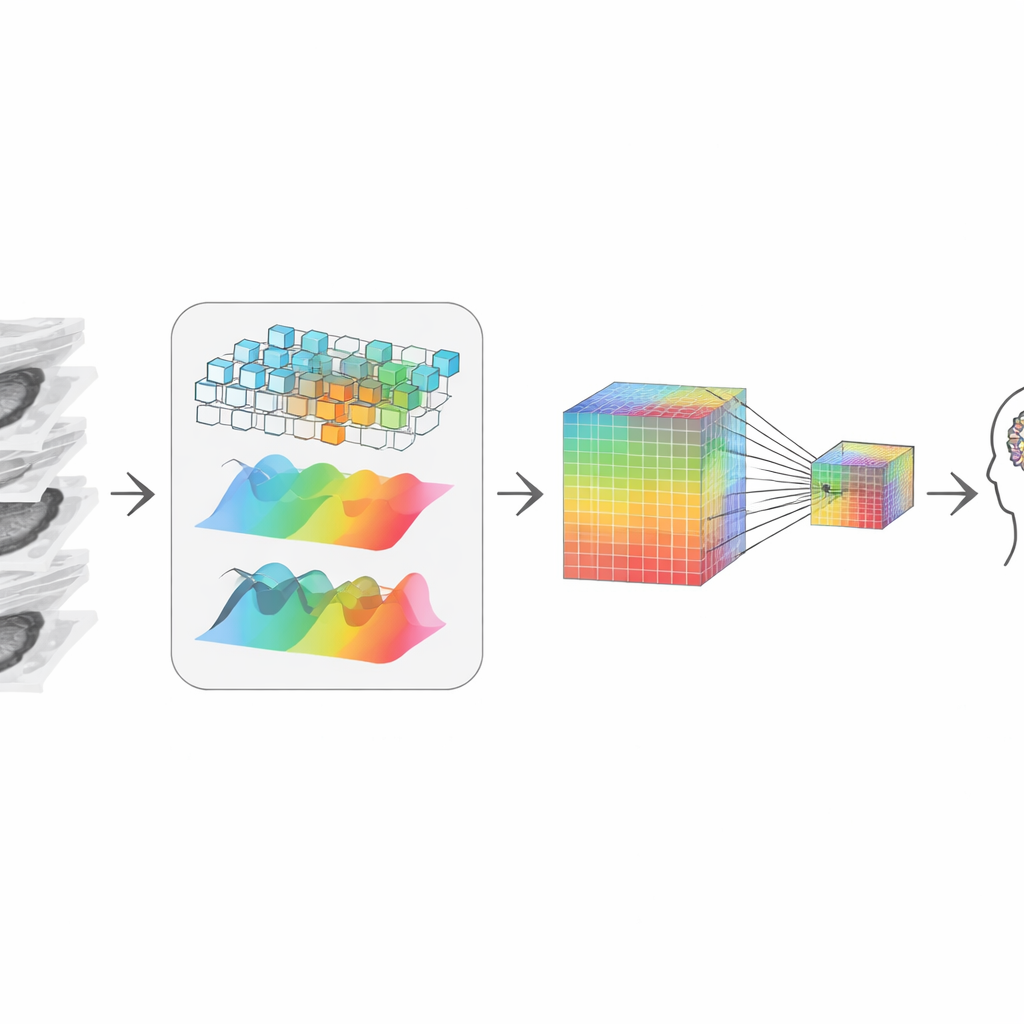
Reconstruir la historia 3D a partir de piezas
Tras el recorte, el sistema necesita “reunir” los cortes restantes en una imagen 3D coherente. Los autores lo hacen combinando dos vistas complementarias de los datos. Un camino observa formas y bordes locales, como una lupa que se desplaza por el volumen, sensible a límites nítidos y texturas. El otro transforma los datos a una vista en frecuencia, mejor para capturar patrones amplios y estructuras de largo alcance entre cortes—cómo se extiende un tumor o cómo está conformado un órgano en conjunto. Un paso de fusión adaptativa aprende cuánto confiar en cada vista en cada punto, obteniendo una representación que respeta tanto el detalle fino como el contexto global, aun partiendo de cortes 2D.
Conservar pistas diminutas mientras se comprime
Para comunicarse con un modelo de lenguaje grande—la parte que responde preguntas y redacta informes—la información visual debe comprimirse en un número moderado de tokens, o “palabras visuales”. Una reducción simple difuminaría señales pequeñas pero críticas, como calcificaciones pequeñas o cambios sutiles de textura que importan en el diagnóstico. Para evitarlo, los autores crean una representación de doble vía: una mantiene una versión de alta resolución rica en detalle y la otra es una versión más pequeña y económica. Un mecanismo de atención permite que cada punto en la versión pequeña «mire hacia atrás» a la versión grande y extraiga los detalles más nítidos disponibles. El resultado es un resumen visual compacto que sigue transportando las pistas que interesan a un radiólogo, y que luego se pasa al modelo de lenguaje para razonar.
Comprobación en tareas médicas reales
Para probar su diseño, los investigadores lo evaluaron en puntos de referencia 3D públicos que plantean dos preguntas principales: ¿puede el sistema redactar descripciones de estilo radiológico precisas de exploraciones 3D, y puede responder preguntas sobre lo que se ve en ellas? Su enfoque, a pesar de nunca entrenar un codificador específico 3D, superó a varios modelos sólidos basados en 3D en ambas tareas. Produjo informes más precisos y clínicamente ricos y respondió con mayor exactitud a preguntas difíciles sobre el órgano, la anomalía o la localización implicados. Además, funcionó más rápido, requirió muchos menos datos de entrenamiento 3D y se generalizó bien a distintos tipos de exploraciones como RM y PET.
Qué significa esto para la atención futura
En términos prácticos, este trabajo muestra que no es necesario empezar de cero con modelos 3D consumidores de datos para obtener ayuda de alta calidad de la IA en exploraciones volumétricas. Reutilizando inteligentemente un robusto experto 2D, seleccionando con cuidado los cortes informativos y reconstruyendo la imagen 3D preservando detalles minúsculos, los autores alcanzan un rendimiento de vanguardia con mucha menos información y cálculo. Si se adopta ampliamente, este enfoque podría poner asistencia avanzada basada en IA—mejores informes, explicaciones más claras y triaje más fiable—al alcance de hospitales y clínicas que carecen de grandes recursos de datos, acercando el análisis sofisticado de imágenes a la práctica clínica habitual.
Cita: Lian, Y., Xie, Y., Jiang, Y. et al. A data-efficient 3D medical vision-language model using only a 2D encoder. Sci Rep 16, 8809 (2026). https://doi.org/10.1038/s41598-026-39526-z
Palabras clave: imágenes médicas 3D, modelos visión‑lenguaje, IA en radiología, aprendizaje eficiente en datos, análisis de TC y RM