Clear Sky Science · es
CGDFNet: una red de segmentación semántica en tiempo real de doble rama con fusión de detalles guiada por contexto
Enseñar a los coches a ver toda la calle
Los coches modernos y los robots dependen cada vez más de cámaras para comprender el mundo que les rodea: detectar carreteras, aceras, peatones, vehículos y señales en tiempo real. Este artículo presenta CGDFNet, un nuevo sistema de visión por ordenador diseñado para realizar este tipo de «comprensión de escenas» de forma más rápida y precisa, especialmente en calles concurridas de la ciudad. Al aprender a conservar tanto los detalles finos (como postes de semáforo o ruedas de bicicleta) como la disposición global (como carreteras y edificios) al mismo tiempo, CGDFNet pretende hacer que la conducción automatizada y otras tareas de visión en tiempo real sean más seguras y fiables.
Por qué la visión a nivel de píxel es tan exigente
En la segmentación semántica, un ordenador asigna una categoría a cada píxel de la imagen: carretera, coche, peatón, cielo, etc. Esto es mucho más exigente que simplemente dibujar un recuadro alrededor de un coche, porque el sistema debe trazar con alta precisión los contornos de los objetos y las formas pequeñas. Existen muchos métodos de alta precisión, pero suelen ser lentos y consumidores de energía, lo que no encaja bien con sistemas en tiempo real en coches, drones o dispositivos portátiles. Por otro lado, los métodos ligeros que funcionan rápido a menudo sacrifican detalle o pierden de vista la escena en su conjunto, teniendo dificultades con objetos pequeños, estructuras finas o entornos urbanos concurridos.
Dos caminos: uno para el detalle, otro para el contexto
CGDFNet aborda esta tensión con un diseño de doble rama: una rama se centra en los detalles nítidos, mientras que la otra captura el contexto amplio. Sobre una red base eficiente, las capas inferiores alimentan una «rama de detalle» que mantiene mayor resolución para preservar bordes y texturas. Las capas más profundas alimentan una «rama de contexto» que ve la escena de forma más comprimida, adecuada para comprender la estructura general y las relaciones entre objetos. A diferencia de diseños de dos ramas anteriores que mantenían estas corrientes mayoritariamente separadas y luego las sumaban de forma tosca, CGDFNet fomenta la comunicación entre ellas a lo largo del procesamiento, de modo que los detalles finos se contrastan constantemente con lo que la red sabe sobre la escena global.
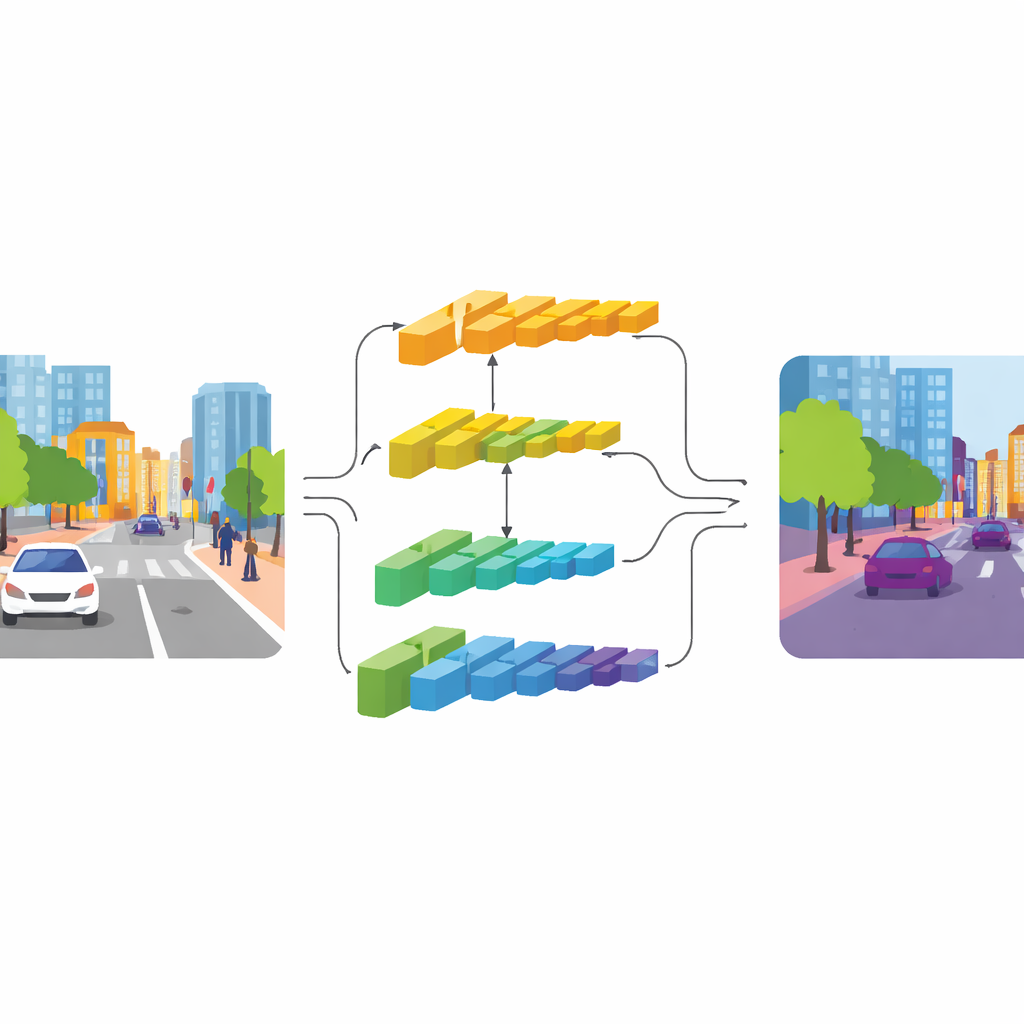
Guiar los detalles con significado
Dos componentes clave refuerzan esta interacción. En la rama de contexto, un Módulo de Refinamiento Semántico aprende a resaltar las regiones y canales más informativos en sus mapas de características. Lo hace combinando indicios locales (qué partes de la escena están activas cerca unas de otras) con indicios globales (qué ve la red en toda la imagen), de modo que la representación lleve tanto detalle de vecindario como significado a nivel de escena. En la rama de detalle, un Módulo de Detalle Guiado por Contexto utiliza esta información semántica para dirigir la atención hacia bordes y estructuras finas importantes, como el contorno de un autobús o el bastidor de una bicicleta. Se basa en un tipo especial de convolución más sensible a los cambios entre píxeles vecinos, que enfatiza de forma natural los contornos y los objetos pequeños sin añadir muchos parámetros extra.
Mezclar la información en el mundo de las frecuencias
Una característica distintiva de CGDFNet es cómo fusiona las dos ramas. En lugar de sumar simplemente sus mapas en el espacio de la imagen, los autores diseñan un Módulo de Fusión Adaptativa en el Dominio de Fourier. Este módulo transforma temporalmente las características combinadas al dominio de la frecuencia, donde los patrones se representan en términos de variaciones lentas y amplias y cambios rápidos y agudos. Un mecanismo de compuerta adaptativa aprende entonces qué componentes de frecuencia enfatizar desde la rama de detalle y cuáles enfatizar desde la rama de contexto. Tras este ponderado, las características se transforman de vuelta, produciendo una representación que une bordes nítidos con una estructura global coherente de forma más efectiva que la fusión tradicional únicamente espacial.
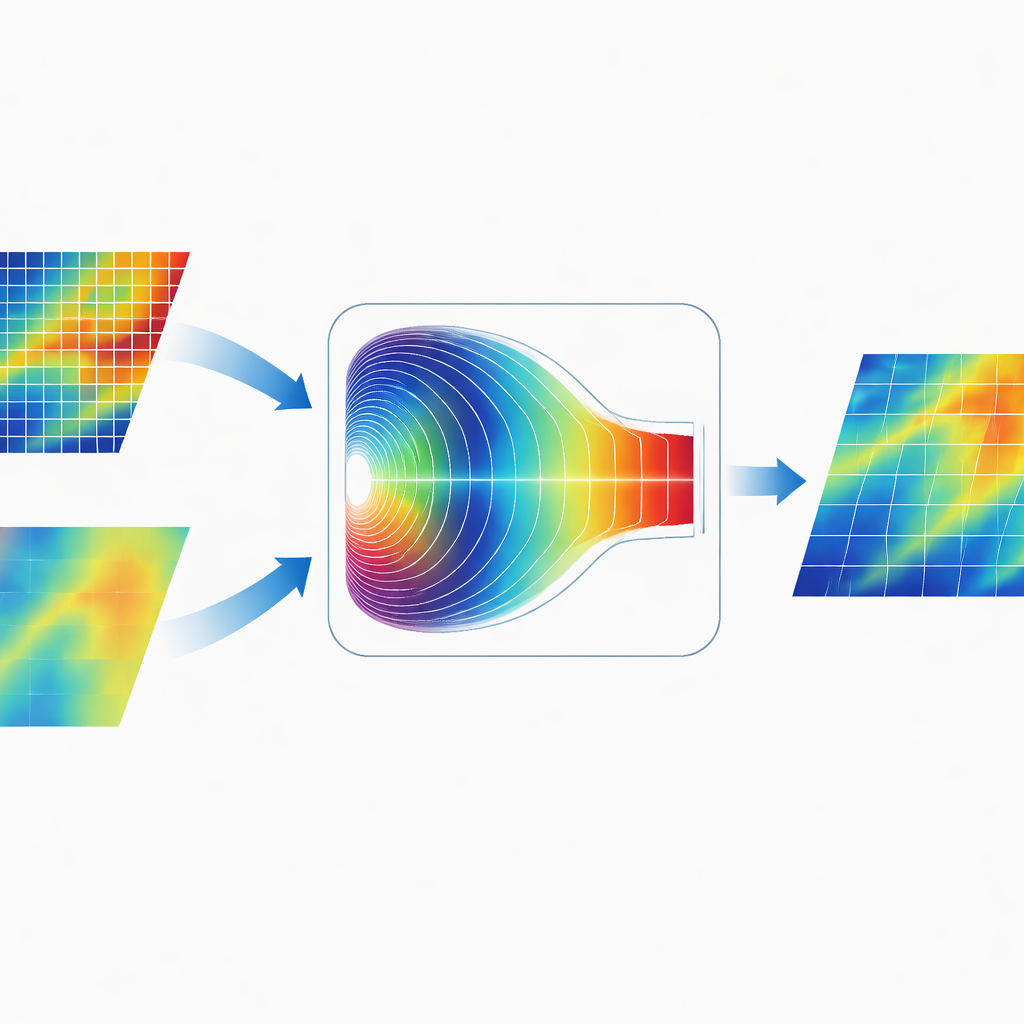
Resultados en calles reales
El equipo evaluó CGDFNet en dos conjuntos de referencia ampliamente usados para escenas de conducción urbana: Cityscapes, recogido en ciudades europeas, y CamVid, capturado desde la perspectiva del conductor en el Reino Unido. CGDFNet procesó imágenes grandes a velocidades en tiempo real: alrededor de 88 fotogramas por segundo en Cityscapes y cerca de 129 fotogramas por segundo en CamVid, mientras alcanzaba una precisión de segmentación que iguala o supera a muchos sistemas de última generación. Se comportó especialmente bien en categorías que suelen ser difíciles de segmentar, como vallas, señales de tráfico, autobuses y bicicletas, donde preservar límites precisos y estructuras pequeñas es crucial.
Qué significa esto para la tecnología cotidiana
En términos prácticos, CGDFNet demuestra que es posible construir sistemas de visión que sean lo suficientemente rápidos para el uso en tiempo real y lo bastante atentos para respetar detalles pequeños y críticos para la seguridad en escenas urbanas complejas. Al combinar una rama enfocada en el detalle, una rama enfocada en el contexto y un paso de fusión inteligente en el dominio de la frecuencia, la red mantiene una visión equilibrada de la calle: sabe dónde está todo y dónde empieza y termina cada objeto. Aunque persisten desafíos —como multitudes densas o condiciones meteorológicas adversas—, el enfoque ofrece un plano prometedor para la visión en dispositivos futuros, desde coches autónomos hasta cámaras de tráfico inteligentes y robots asistenciales.
Cita: Zhao, S., Fu, W., Gao, J. et al. CGDFNet: a dual-branch real-time semantic segmentation network with context-guided detail fusion. Sci Rep 16, 9191 (2026). https://doi.org/10.1038/s41598-026-39370-1
Palabras clave: segmentación semántica en tiempo real, visión para conducción autónoma, red neuronal de doble rama, fusión de características basada en Fourier, comprensión de escenas urbanas