Clear Sky Science · es
Una red neuronal convolucional de extremo a extremo para la transmisión segura de imágenes mediante cifrado conjunto y esteganografía
Por qué importa ocultar imágenes dentro de otras imágenes
Cada día, hospitales, bancos y particulares envían gran número de fotografías por internet —desde exploraciones médicas hasta documentos de identidad o fotos familiares. Mantener estas imágenes privadas suele implicar cifrarlas, lo que las convierte en ruido visual aleatorio, o esconderlas dentro de otras imágenes, un truco llamado esteganografía. Cada enfoque tiene una debilidad: las imágenes cifradas llaman la atención, y las imágenes ocultas pueden ser descubiertas mediante análisis inteligente. Este artículo presenta un nuevo sistema de aprendizaje profundo que combina ambas ideas, con el objetivo de enviar imágenes secretas de manera que parezcan naturales para el ojo humano y, al mismo tiempo, sean difíciles de descifrar para un atacante.
El problema de las técnicas de protección actuales
Herramientas de cifrado tradicionales como AES y DES son matemáticamente robustas, pero convierten una foto en un bloque de ruido visual que deja claro: “aquí se oculta algo importante”. La esteganografía clásica hace lo contrario: incrusta información en los detalles finos de una imagen de aspecto normal, pero con frecuencia sin una protección criptográfica fuerte. Si un atacante detecta la artimaña, el mensaje oculto puede ser relativamente fácil de extraer. Métodos recientes basados en aprendizaje profundo han mejorado ya sea el cifrado o el ocultamiento, pero la mayoría los trata como dos pasos separados. Esa separación desperdicia recursos de cómputo y puede permitir que errores en una etapa perjudiquen a la otra. Los autores sostienen que lo que falta es un único sistema que aprenda, de extremo a extremo, cómo disfrazar y proteger imágenes al mismo tiempo.
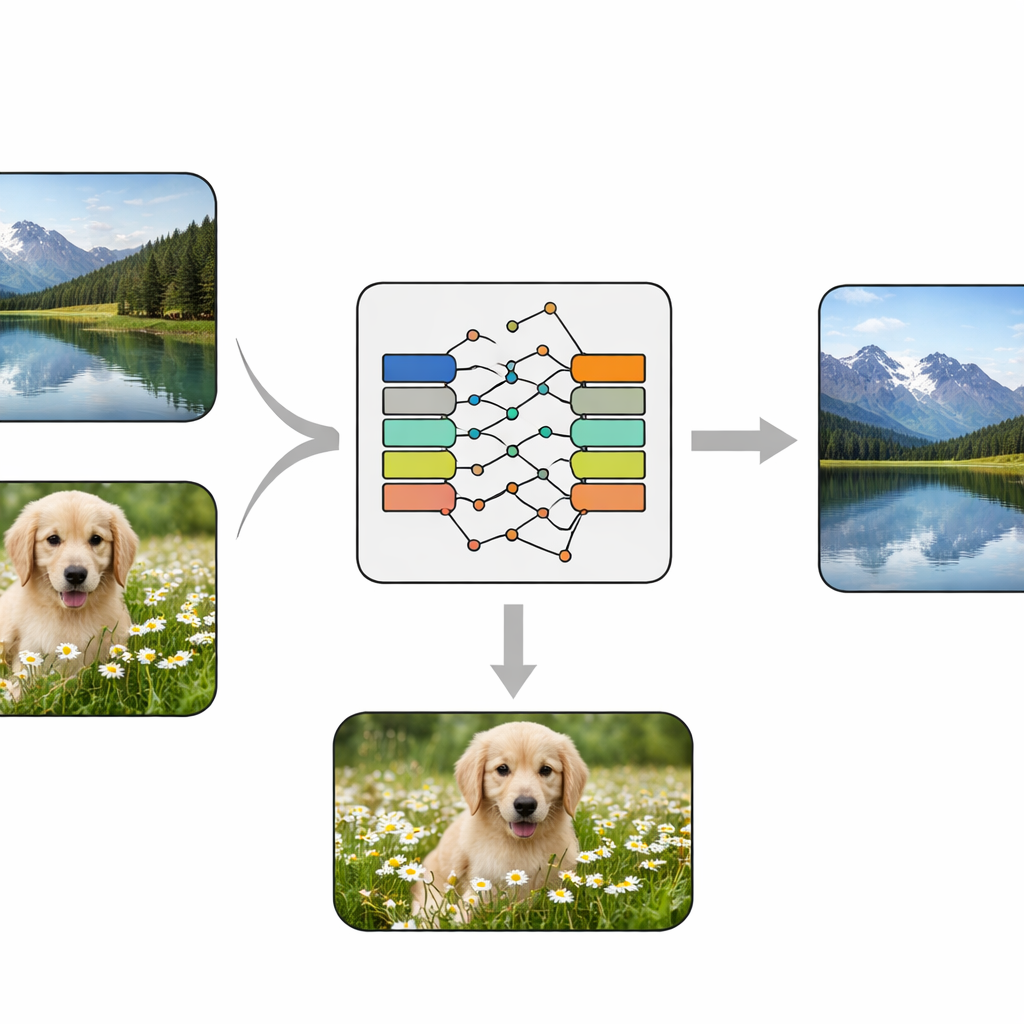
Un único «cerebro» que mezcla y oculta
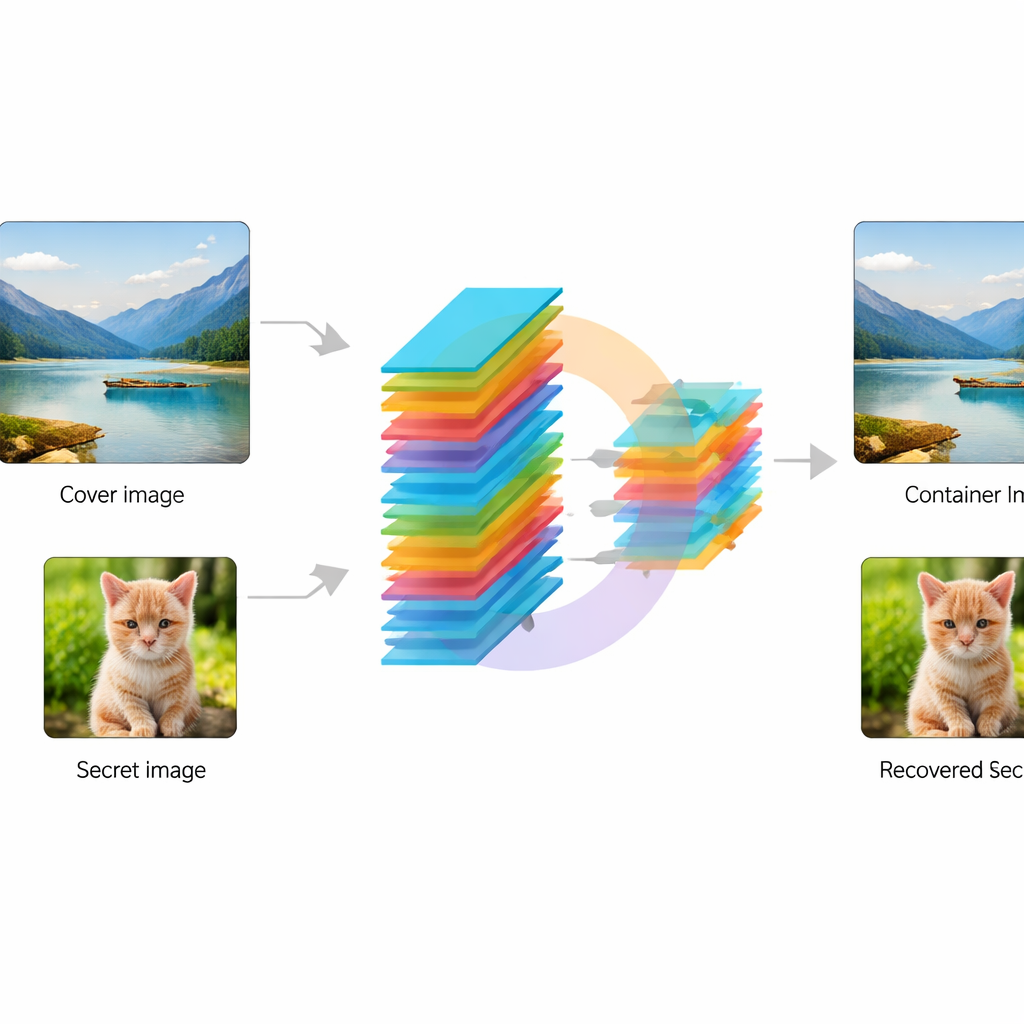
Los investigadores diseñan una red neuronal convolucional de extremo a extremo —esencialmente una tubería de procesamiento de imágenes entrenable— que recibe dos imágenes: una foto «portadora» normal y una foto «secreta» a proteger. Primero, un módulo especial llamado KeyMixer transforma la imagen secreta usando claves numéricas entrenables. A diferencia de los cifrados fijos diseñados a mano, este mezclador aprende modificaciones dependientes del contenido, que varían según texturas y formas de la imagen, introduciendo distorsiones sutiles y no evidentes. A continuación, una red Codificadora (Encoder) integra suavemente este secreto transformado en la imagen portadora, creando una imagen «contenedora» que debe seguir pareciendo natural. En el extremo receptor, una red Decodificadora (Decoder) correspondiente toma únicamente la imagen contenedora y reconstruye el secreto oculto, sin necesitar claves adicionales ni información lateral durante la recuperación.
Enseñar a la red a equilibrar secreto y apariencia
Entrenar este sistema implica pedirle que logre dos objetivos a la vez: mantener la imagen contenedora visualmente cercana a la portadora original y recuperar la imagen secreta con la máxima fidelidad posible. Los autores lo hacen con una estrategia de doble pérdida que penaliza tanto los cambios visibles en la portadora como los errores en el secreto reconstruido. Emplean una colección de referencia popular de fotos naturales, el conjunto de datos STL‑10, y aplican trucos estándar de aumento de datos como volteos y pequeñas rotaciones para que la red vea escenas variadas. Durante el entrenamiento, el modelo mejora de forma constante hasta que ambos objetivos se estabilizan, mostrando que puede encontrar un punto intermedio viable entre invisibilidad y recuperación fiel.
Qué tan bien sobreviven las imágenes ocultas
Para evaluar la calidad, el equipo mide cuán similares son las imágenes contenedoras a las portadoras y cuán cercanos están los secretos recuperados a los originales, usando puntuaciones estándar de calidad de imagen. En las imágenes de prueba, el método alcanza alta similitud estructural tanto para la portadora como para el secreto, con valores por encima de 0,90, lo que significa que las formas y los detalles se conservan en gran medida. Las imágenes secretas, en particular, alcanzan similitudes muy altas, indicando una recuperación perceptual casi perfecta. En comparación con varios sistemas modernos de esteganografía basados en aprendizaje profundo y canalizaciones híbridas, el nuevo modelo de extremo a extremo ofrece la mejor reconstrucción de la imagen secreta, aunque algunos rivales preserven ligeramente mejor la portadora. Pruebas estadísticas sobre distribuciones de píxeles, aleatoriedad y sensibilidad a cambios sugieren que las contenedoras no revelan pistas obvias de que algo está oculto.
Qué podría significar esto para la privacidad cotidiana
En términos llanos, este trabajo demuestra que un único modelo de aprendizaje profundo puede aprender a disfrazar y proteger imágenes de modo que una imagen oculta pueda recuperarse con alta claridad, mientras que la imagen compartida sigue pareciendo ordinaria. En lugar de acoplar cifrado y esteganografía en una cadena tosca, el sistema aprende un compromiso fluido entre sutileza visual y seguridad. Aunque actualmente requiere hardware potente y pruebas adicionales frente a ataques avanzados, el enfoque señala hacia herramientas futuras que podrían asegurar discretamente exploraciones médicas, fotos personales u otras imágenes sensibles en comunicaciones en línea rutinarias sin anunciar que hay algo secreto en absoluto.
Cita: Iqbal, A., Sattar, H., Shafi, U.F. et al. An end-to-end convolutional neural network for secure image transmission via joint encryption and steganography. Sci Rep 16, 8228 (2026). https://doi.org/10.1038/s41598-026-39351-4
Palabras clave: seguridad de imágenes, esteganografía, aprendizaje profundo, cifrado neuronal, protección de la privacidad