Clear Sky Science · es
Parsing de direcciones de pacientes mediante aprendizaje contrastivo con conocimiento del KG e inferencia LLM restringida en local
Por qué importa tener direcciones de pacientes ordenadas
Detrás de cada visita hospitalaria hay una humilde línea de texto: la dirección del domicilio del paciente. Lejos de ser un detalle administrativo, esas direcciones sustentan el mapeo de enfermedades, la planificación de emergencias y decisiones sobre dónde ubicar clínicas y ambulancias. Sin embargo, en muchos sistemas de registros médicos las direcciones se guardan como texto desordenado e inconsistente, lleno de abreviaturas, errores tipográficos y datos ausentes. Este artículo presenta AddrKG‑LLM, un nuevo método que convierte ese texto de direcciones indómito en registros limpios y fiables mientras mantiene la privacidad de los datos sensibles.
El problema de las direcciones domiciliarias desordenadas
Cuando las direcciones se escriben libremente, la gente omite distritos, altera el orden de las palabras o usa apelativos locales que los mapas oficiales no reconocen. Los métodos informáticos más antiguos comparan cadenas carácter a carácter o listas de palabras simples, lo que funciona solo cuando las entradas ya están limpias y completas. Los sistemas de aprendizaje profundo más recientes comprenden el contexto con mayor inteligencia, pero aún pueden fallar con formulaciones inusuales y exigen mucha potencia de cálculo. Últimamente, los grandes modelos de lenguaje han demostrado una notable capacidad para entender y generar texto. Sin embargo, cuando se les permite responder libremente, también tienden a “alucinar” detalles que no están realmente en los datos —un riesgo inaceptable en salud, donde los registros deben ser precisos y auditables.
Un camino en dos pasos del caos al orden
Los investigadores diseñaron AddrKG‑LLM como una canalización en dos etapas que añade estructura y normas alrededor del modelo de lenguaje en lugar de dejarlo actuar solo. Primero, las direcciones entrantes se limpian para eliminar datos altamente identificables como números de edificio y habitación y contactos telefónicos, lo que ayuda a proteger la privacidad. El texto restante se convierte en una representación numérica densa que captura su significado. Al mismo tiempo, el equipo construye un grafo de conocimiento —una red tipo mapa que codifica las relaciones oficiales entre ciudades, distritos, calles y comunidades residenciales. Usando una técnica llamada aprendizaje contrastivo, entrenan el sistema para que direcciones que se refieren a la misma comunidad real queden próximas en ese espacio compartido, mientras que lugares no relacionados se separan. Esto permite al sistema recuperar rápidamente una lista corta de candidatos probables de dirección para cada nuevo registro de paciente.
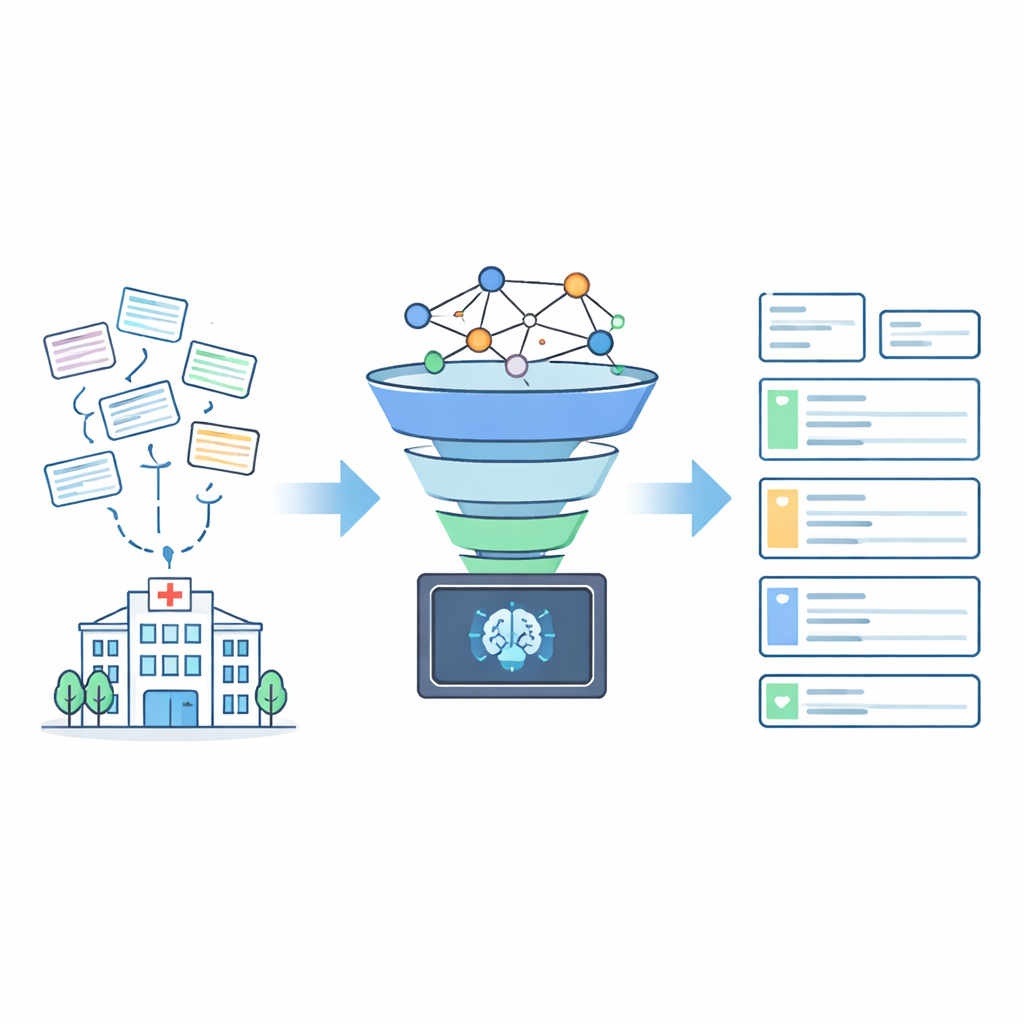
Mantener la IA con riendas cortas
En la segunda etapa, el modelo de lenguaje grande opera dentro de un espacio de búsqueda cuidadosamente acotado. En vez de inventar una dirección desde cero, el modelo recibe el texto original limpiado junto con el pequeño conjunto de comunidades candidatas sugeridas por el grafo de conocimiento. El prompt instruye explícitamente al modelo para que elija únicamente entre esos candidatos y produzca resultados en una estructura JSON fija con campos separados para ciudad, distrito, calle o municipio y comunidad. Si ninguno de los candidatos encaja —por ejemplo, cuando la comunidad real no fue recuperada—, el modelo debe devolver valores vacíos en lugar de adivinar. Este comportamiento de “rechazo primero” reduce drásticamente el riesgo de que entradas plausibles pero erróneas se filtren en los registros hospitalarios.
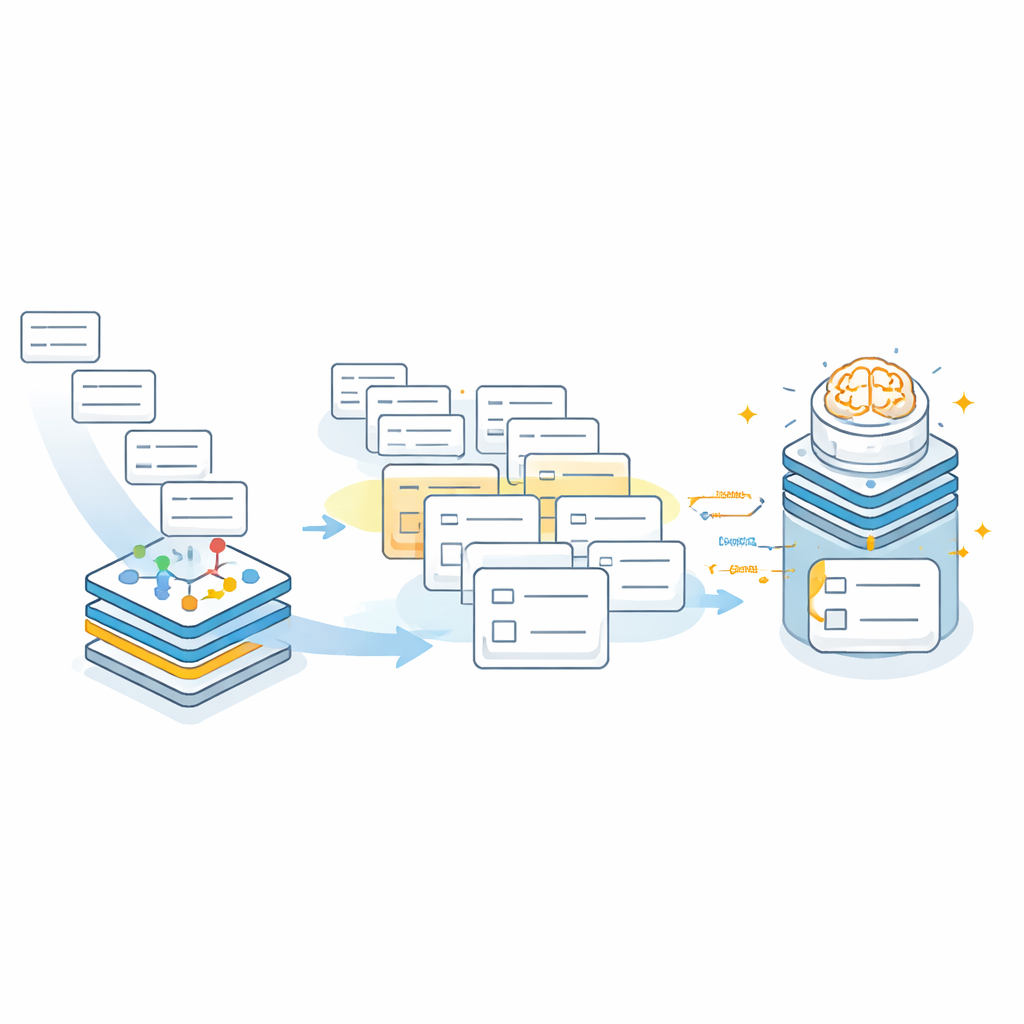
¿Qué tan bien funciona en la práctica?
El equipo evaluó AddrKG‑LLM con diez mil direcciones hospitalarias reales desidentificadas que reflejan el ruido del mundo real: abreviaturas, distritos ausentes, variantes ortográficas e incluso entradas completamente inválidas. Compararon su sistema con herramientas clásicas de emparejamiento de cadenas, modelos de etiquetado de secuencias basados en aprendizaje profundo, modelos de lenguaje de propósito general usados de forma libre y un servicio comercial de estandarización de direcciones. Según medidas estrictas que exigen que cada campo de la dirección sea correcto simultáneamente, AddrKG‑LLM superó a todas estas líneas base, aumentando la precisión global en más de doce puntos porcentuales respecto a un sólido modelo basado en BERT. Las mejoras fueron especialmente notables en direcciones abreviadas o parcialmente incompletas, donde la jerarquía incorporada del grafo de conocimiento ayuda a llenar vacíos. Los autores también exploraron cómo varía el rendimiento con distintos tamaños de modelo de lenguaje y con diferentes números de candidatos recuperados, mostrando cómo los hospitales pueden equilibrar velocidad y precisión según sus necesidades.
Qué significa esto para la atención cotidiana
Para quienes no son especialistas, el mensaje clave es que AddrKG‑LLM ofrece una manera de limpiar datos de direcciones vitales pero desordenadas manteniendo el control firmemente en manos humanas. Al acoplar un grafo de conocimiento tipo mapa con un modelo de lenguaje restringido que se ejecuta íntegramente en los servidores del hospital, el marco proporciona direcciones más precisas y consistentes sin enviar detalles sensibles a servicios en la nube externos ni permitir que la IA improvise. El resultado es una herramienta práctica que puede fortalecer la vigilancia de enfermedades, mejorar la planificación de recursos y apoyar operaciones hospitalarias más seguras y eficientes —simplemente asegurando que cada paciente esté de forma fiable en el mapa.
Cita: Li, J., Pan, X. & Jia, Y. Patient address parsing via KG-aware contrastive learning and constrained on-prem LLM inference. Sci Rep 16, 8003 (2026). https://doi.org/10.1038/s41598-026-39348-z
Palabras clave: parsing de direcciones de pacientes, calidad de datos de salud, grafo de conocimiento, modelo de lenguaje grande, informática médica