Clear Sky Science · es
Predicción enmascarada topológica del movimiento del esqueleto y aprendizaje contrastivo para el reconocimiento auto-supervisado de acciones humanas
Enseñar a los ordenadores a leer el lenguaje corporal
Desde timbres inteligentes con vídeo hasta herramientas de rehabilitación inteligentes, muchos sistemas modernos deben comprender lo que hace la gente solo observando cómo se mueve. Pero entrenar a los ordenadores para reconocer acciones humanas normalmente exige enormes conjuntos de datos cuidadosamente etiquetados, donde cada saludo, patada o apretón de manos se anota manualmente. Este estudio presenta una forma de que las máquinas aprendan a partir de datos de movimiento en bruto, utilizando únicamente el esqueleto en movimiento del cuerpo: sin etiquetas, sin caras y sin vídeo en color completo, lo que hace que el reconocimiento de acciones sea más preciso, más respetuoso con la privacidad y mucho menos dependiente de costosas anotaciones humanas.
Por qué los esqueletos son suficientes
En lugar de analizar fotogramas completos de vídeo, el método trabaja con datos de esqueleto 3D: las coordenadas de articulaciones clave como hombros, codos, caderas y rodillas a lo largo del tiempo. Esta visión esencial del cuerpo tiene varias ventajas. En gran medida evita problemas de privacidad porque se eliminan las caras y la ropa, y es lo bastante compacta para procesarse de forma eficiente, incluso en grabaciones largas. Los esqueletos también son robustos frente a fondos desordenados y cambios de iluminación que pueden confundir a los sistemas basados en vídeo habituales. Sin embargo, la mayoría de los enfoques existentes basados en esqueletos todavía dependen en gran medida de ejemplos etiquetados y tienen dificultades para capturar por completo cómo se mueven conjuntamente las articulaciones en acciones complejas y coordinadas.
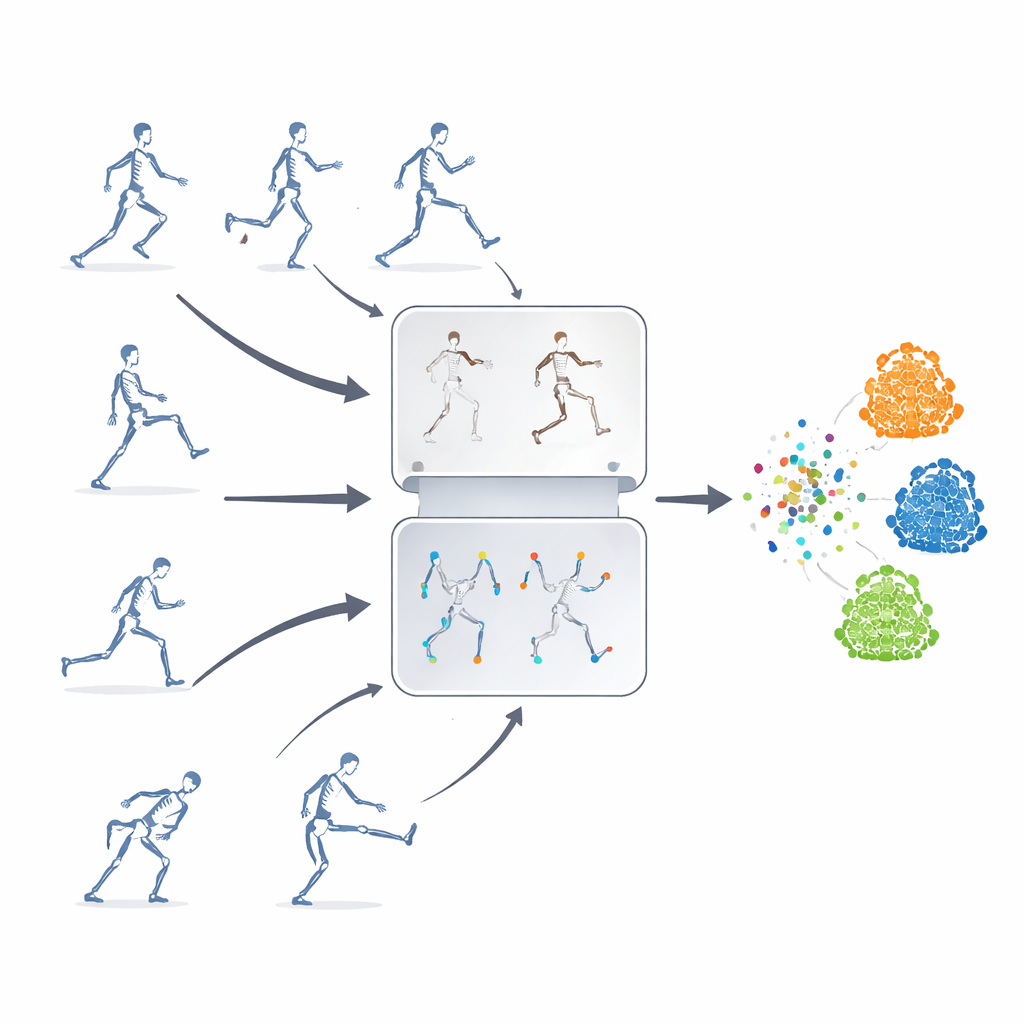
Aprender sin etiquetas
Los autores proponen un marco de aprendizaje auto-supervisado, lo que significa que el sistema se enseña a sí mismo a partir de secuencias de esqueletos no etiquetadas. Su idea clave es combinar dos estrategias potentes que suelen usarse por separado. Una es la “predicción enmascarada”, donde se ocultan deliberadamente partes de los datos del esqueleto para que el modelo tenga que adivinar el movimiento faltante a partir del contexto restante. La otra es el “aprendizaje contrastivo”, que muestra al modelo varias versiones alteradas de la misma acción y lo entrena para reconocer que esas variaciones representan un mismo movimiento subyacente. Al mezclar estos enfoques, el sistema aprende tanto los detalles finos del movimiento articular como el significado general de una acción.
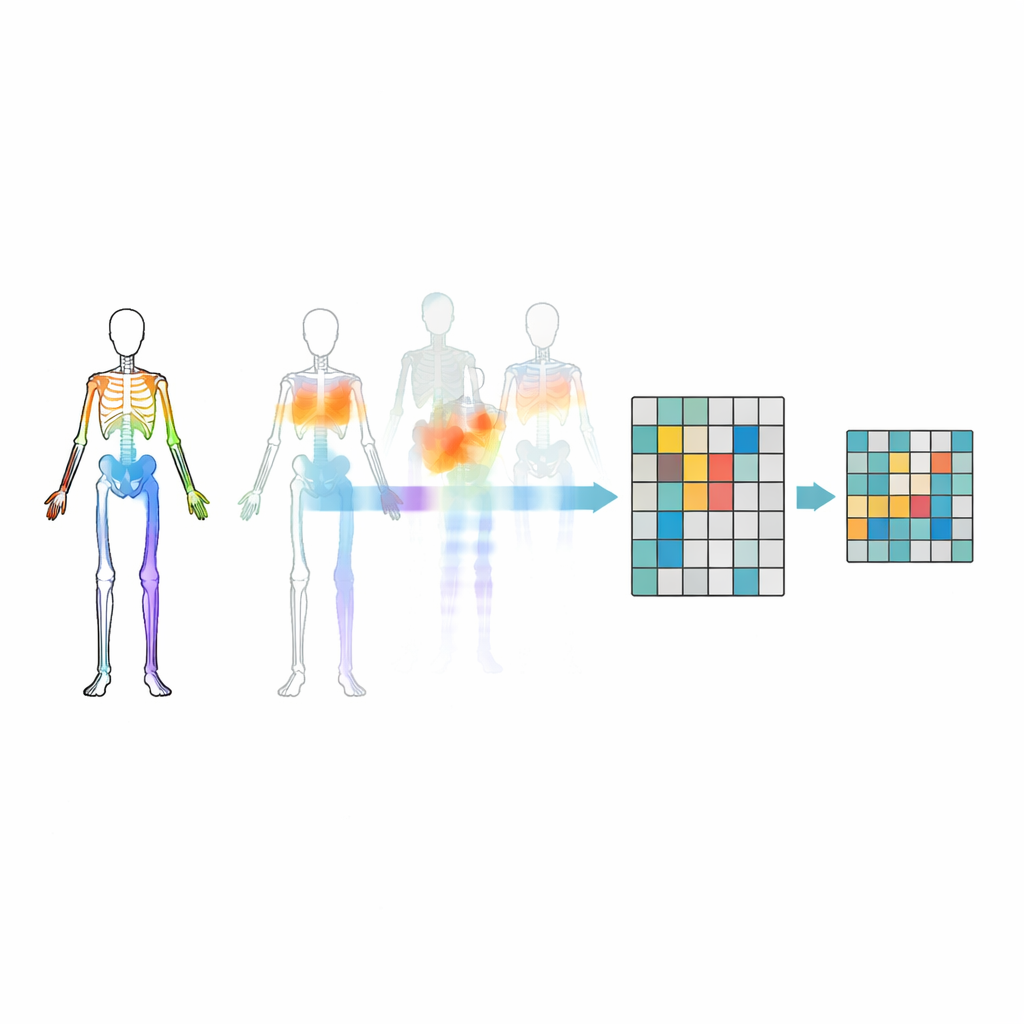
Ocultar las articulaciones adecuadas
Enmascarar articulaciones al azar no basta: el modelo podría ignorar relaciones importantes entre partes del cuerpo o fijarse en el movimiento más obvio. Para evitarlo, los investigadores introducen una estrategia de enmascaramiento basada en la topología y el movimiento. Agrupan las articulaciones en regiones corporales significativas, como brazos, piernas y tronco, y miden cuánto se mueve cada región a lo largo del tiempo. Las decisiones de enmascaramiento se guían tanto por la estructura del cuerpo como por la actividad de cada región, de modo que a veces se ocultan partes muy activas y el modelo se ve obligado a inferirlas a partir del resto del cuerpo. Este ocultamiento dirigido ayuda al sistema a aprender cómo cooperan las articulaciones durante las acciones, en lugar de limitarse a memorizar algunos movimientos llamativos.
Estirar las acciones de muchas maneras
Para entrenar la parte contrastiva del sistema, la misma secuencia original de esqueleto se transforma en muchas “vistas” diferentes. Algunos cambios son suaves, como recortar la ventana temporal o deformar ligeramente la trayectoria, mientras que otros son más extremos, incluyendo volteos, rotaciones y ruido más fuerte. Estos múltiples niveles de aumento exponen al modelo a una rica variedad de patrones de movimiento, animándolo a centrarse en la estructura esencial de una acción en lugar de en detalles superficiales. Al mismo tiempo, un módulo de supresión de características guiado por la trayectoria rastrea de qué características de movimiento depende más el modelo y las suprime intencionadamente durante el entrenamiento. Al eliminar temporalmente sus pistas favoritas, el sistema se ve empujado a descubrir claves alternativas y a aprender representaciones más generales y transferibles.
¿Qué tan bien funciona?
El marco se prueba en tres grandes benchmarks públicos de acciones humanas 3D, que abarcan comportamientos cotidianos, movimientos relacionados con la medicina e interacciones entre personas. Aun utilizando solo datos de articulaciones esqueléticas y una red neuronal recurrente relativamente ligera, el método iguala o supera a muchos sistemas de vanguardia que dependen de entradas o arquitecturas más complejas. Es particularmente fuerte cuando las anotaciones son escasas o cuando algunas partes del cuerpo están ocultas, condiciones que surgen con frecuencia en entornos del mundo real. Aunque su capacidad para transferir conocimiento entre conjuntos de datos muy diferentes todavía tiene margen de mejora, el enfoque reduce de forma significativa la brecha entre entrenamiento etiquetado y no etiquetado para el reconocimiento de acciones.
Qué significa esto para los sistemas del mundo real
Para un público no especializado, la conclusión es que este trabajo muestra cómo los ordenadores pueden mejorar mucho en la lectura del lenguaje corporal humano sin que se les diga explícitamente el significado de cada movimiento. Al ocultar y distorsionar de forma inteligente los datos del esqueleto durante el entrenamiento, el modelo aprende patrones de movimiento robustos que resisten malas condiciones de iluminación, el desorden visual o articulaciones faltantes, y lo hace con muchas menos etiquetas proporcionadas por humanos. Esto abre la puerta a sistemas de reconocimiento de acciones más privados, escalables y adaptables para aplicaciones que van desde la monitorización doméstica y el entrenamiento deportivo hasta la rehabilitación médica y la interacción humano-robot.
Cita: Hui, Y., Li, F., Hu, X. et al. Skeleton motion topology-masked prediction and contrastive learning for self-supervised human action recognition. Sci Rep 16, 8100 (2026). https://doi.org/10.1038/s41598-026-39330-9
Palabras clave: reconocimiento de acciones humanas, datos de esqueleto 3D, aprendizaje auto-supervisado, aprendizaje contrastivo, análisis del movimiento