Clear Sky Science · es
Un marco siamés CNN-RNN con agregación multinivel para la reidentificación de personas basada en vídeo
Por qué importa seguir a personas entre cámaras
Las ciudades modernas están cubiertas por cámaras, pero esas cámaras rara vez “hablan” entre sí. Cuando una persona camina desde una esquina hasta una estación, distintas cámaras la ven desde nuevos ángulos, con iluminación diferente y a menudo entre multitudes. Reconocer automáticamente que se trata de la misma persona en distintos fragmentos de vídeo—llamado reidentificación de personas basada en vídeo—puede ayudar a los investigadores a rastrear movimientos tras un incidente, apoyar búsquedas de personas desaparecidas o alimentar análisis en espacios públicos concurridos. Pero hacerlo con precisión y eficiencia, especialmente en hardware modesto, es un desafío técnico importante.
Un cerebro más sencillo para emparejar personas en movimiento
Este estudio presenta un sistema de inteligencia artificial compacto diseñado para determinar si dos clips de vídeo cortos muestran a la misma persona. En lugar de emplear la tendencia actual de redes muy profundas o basadas en transformers, los autores se apoyan en un diseño más ligero que combina dos ingredientes clásicos: una red convolucional que analiza cada fotograma y una unidad recurrente con puertas (GRU) que sigue cómo cambia la apariencia a lo largo del tiempo. Estas dos ramas están dispuestas en una arquitectura siamés—esencialmente, copias gemelas de la misma red que comparten todos sus parámetros internos. Cada gemelo procesa una secuencia de vídeo, y el sistema aprende a producir firmas internas similares para clips de la misma persona y claramente distintas para personas diferentes.
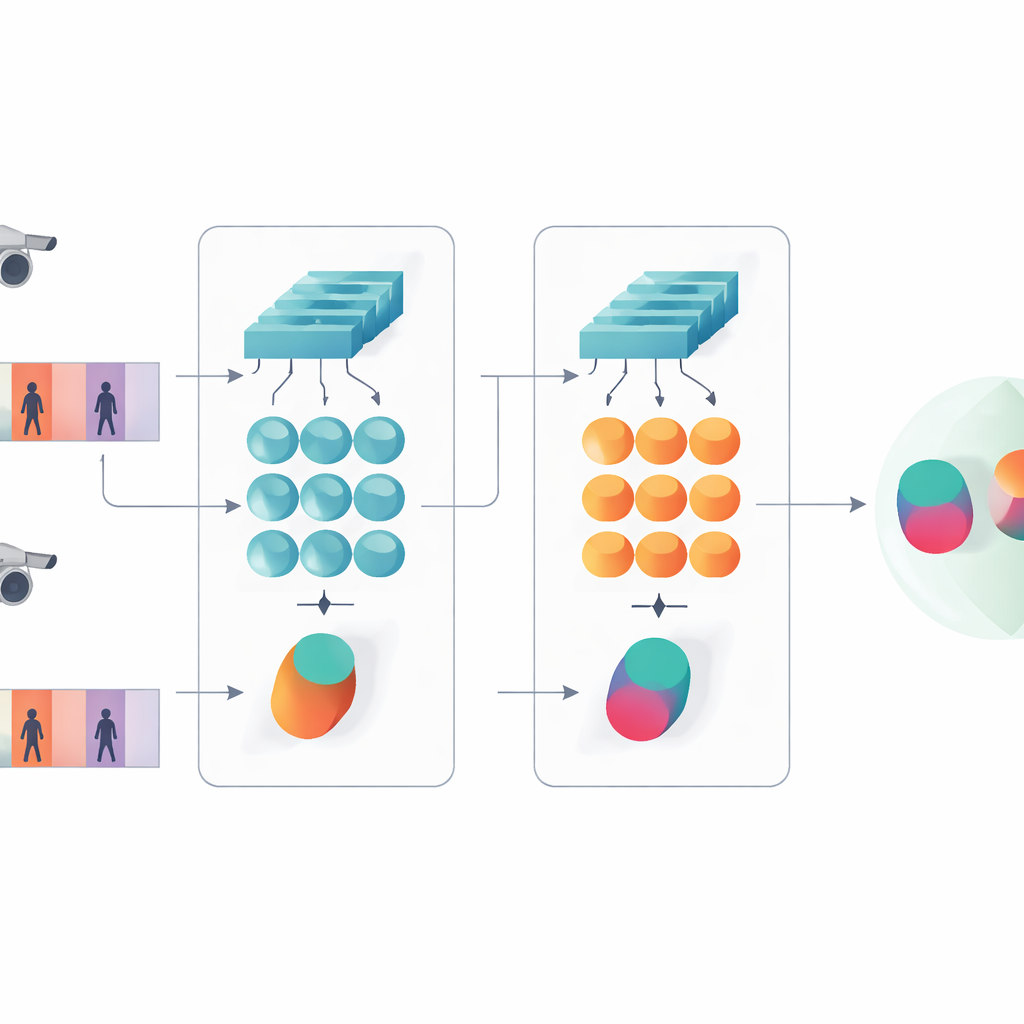
Ver tanto los detalles como los patrones a lo largo del tiempo
Una idea clave del trabajo es que el reconocimiento no debería apoyarse únicamente en las características más profundas y abstractas de una red. Las capas anteriores todavía contienen detalles visuales nítidos, como la trama de una chaqueta, las rayas de un pantalón o el contorno de una mochila—pistas que a menudo sobreviven a cambios de ángulo de cámara. El modelo propuesto conserva por tanto dos niveles de descripción. Una rama agrupa (pooling) las características de las capas tempranas a lo largo de todos los fotogramas para resumir texturas finas y patrones locales. La otra rama alimenta características más profundas a la GRU, que sigue la secuencia fotograma a fotograma y luego promedia sus estados internos en el tiempo. Este paso de promediado evita dar un peso excesivo a los últimos fotogramas y, en su lugar, captura una visión consensuada de cómo luce y se mueve la persona a lo largo de todo el clip.
Entrenar las redes gemelas para que coincidan y clasifiquen
Para enseñar al sistema qué resulta relevante, los autores combinan dos objetivos de entrenamiento. Primero, un objetivo de verificación incentiva a las ramas gemelas a producir firmas cercanas para vídeos de la misma persona y firmas lejanas para personas distintas. Segundo, un objetivo de clasificación pide a la red asignar cada clip de entrenamiento a una identidad concreta. Al optimizar ambos simultáneamente, y haciéndolo en niveles de características bajos y altos, el modelo aprende descripciones internas que no solo son distintivas entre personas, sino también robustas frente a ruido, oclusiones y fotogramas de calidad ocasionalmente pobre. El diseño sigue siendo poco profundo en términos de capas y parámetros, lo que ayuda a evitar el sobreajuste en conjuntos de datos de vídeo relativamente pequeños.
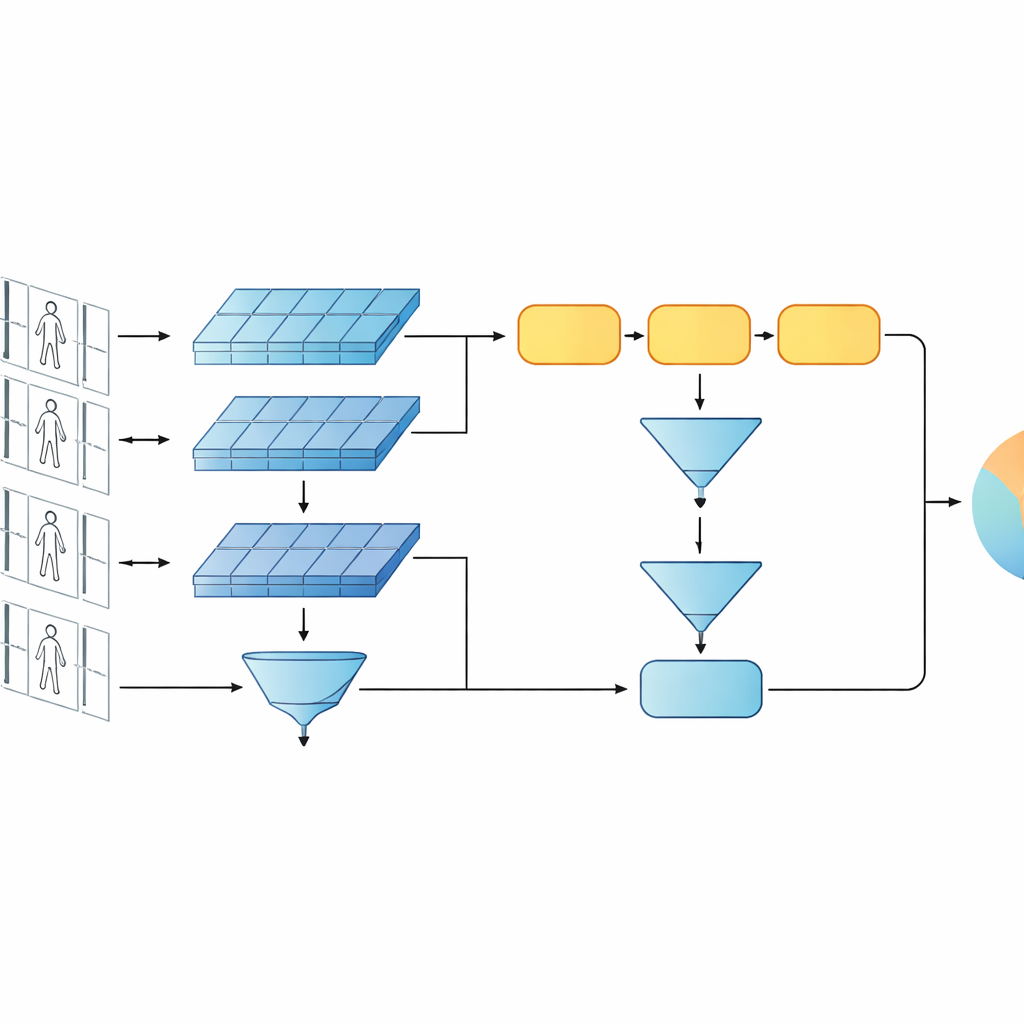
Pruebas en vídeos de estilo de vigilancia real
El marco se evalúa en dos bancos de pruebas de vídeo muy utilizados, PRID-2011 e iLIDS-VID, que contienen secuencias cortas de personas caminando capturadas desde pares de cámaras desfasadas. El estudio examina cuidadosamente distintas decisiones de diseño: sustituir la GRU por otras unidades recurrentes, cambiar el número de capas recurrentes usadas, alterar cómo se agrupan las características en el tiempo y activar o desactivar las ramas de bajo y alto nivel. A través de estas pruebas, una GRU de una sola capa con pooling por media y la configuración multinivel completa proporciona de forma consistente la mejor precisión. El modelo iguala o supera a muchos sistemas siameses y recurrentes más complejos, y compite con algunos diseños basados en atención, mientras usa muchos menos parámetros y computación.
Eficiencia para despliegues en el mundo real
Más allá de la precisión, el trabajo enfatiza la practicidad. La red completa tiene solo alrededor de uno a dos millones de parámetros entrenables—órdenes de magnitud menos que las espinas dorsales residuales profundas o basadas en transformers más populares—y requiere una fracción de su coste computacional por fotograma. Esto la hace más adecuada para desplegarse en dispositivos con memoria y potencia de procesamiento limitadas, como servidores en el borde cerca de las cámaras. Los experimentos también muestran que secuencias de galería más largas, donde el sistema ve más fotogramas de cada persona almacenada, mejoran sustancialmente el reconocimiento, aunque con un incremento lineal en el coste de procesamiento. Los autores sostienen que arquitecturas compactas y cuidadosamente diseñadas pueden ofrecer reidentificación de personas fiable sin el coste elevado de los modelos más grandes actuales.
Qué significa esto para los sistemas de vigilancia cotidianos
En términos sencillos, este artículo demuestra que un diseño inteligente puede vencer al mero tamaño: combinando análisis de imagen poco profundo, modelado de secuencias ligero y una visión de similitud visual en dos niveles, es posible rastrear quién es quién entre cámaras con alta fiabilidad manteniendo el modelo pequeño y rápido. Para sistemas futuros que deben ejecutarse en muchas cámaras, a menudo con restricciones de hardware y energía, este tipo de enfoque multinivel y eficiente podría ayudar a llevar análisis de vídeo más capaces y responsables a aplicaciones del mundo real.
Cita: Wang, YK., Pan, TM. & Sun, CP. A CNN-RNN Siamese framework with multi-level aggregation for video-based person re-identification. Sci Rep 16, 8224 (2026). https://doi.org/10.1038/s41598-026-39277-x
Palabras clave: reidentificación de personas, vigilancia por vídeo, redes neuronales siamesas, modelado temporal, aprendizaje profundo eficiente