Clear Sky Science · es
Un marco robusto de generación de SQL a partir de texto en lenguaje natural con estrategias dinámicas basadas en LLM
Convertir preguntas cotidianas en respuestas de bases de datos
Las organizaciones modernas están inundadas de datos, pero la mayoría de las personas no domina el lenguaje técnico necesario para consultarlos. Este trabajo presenta TriSQL, un sistema que permite a los usuarios formular preguntas en lenguaje natural y las transforma automáticamente en comandos precisos para bases de datos. Al gestionar con cuidado cómo los modelos de lenguaje de gran tamaño manejan la complejidad, el marco pretende hacer que el acceso a los datos sea más preciso y más fiable, incluso para las preguntas más difíciles.
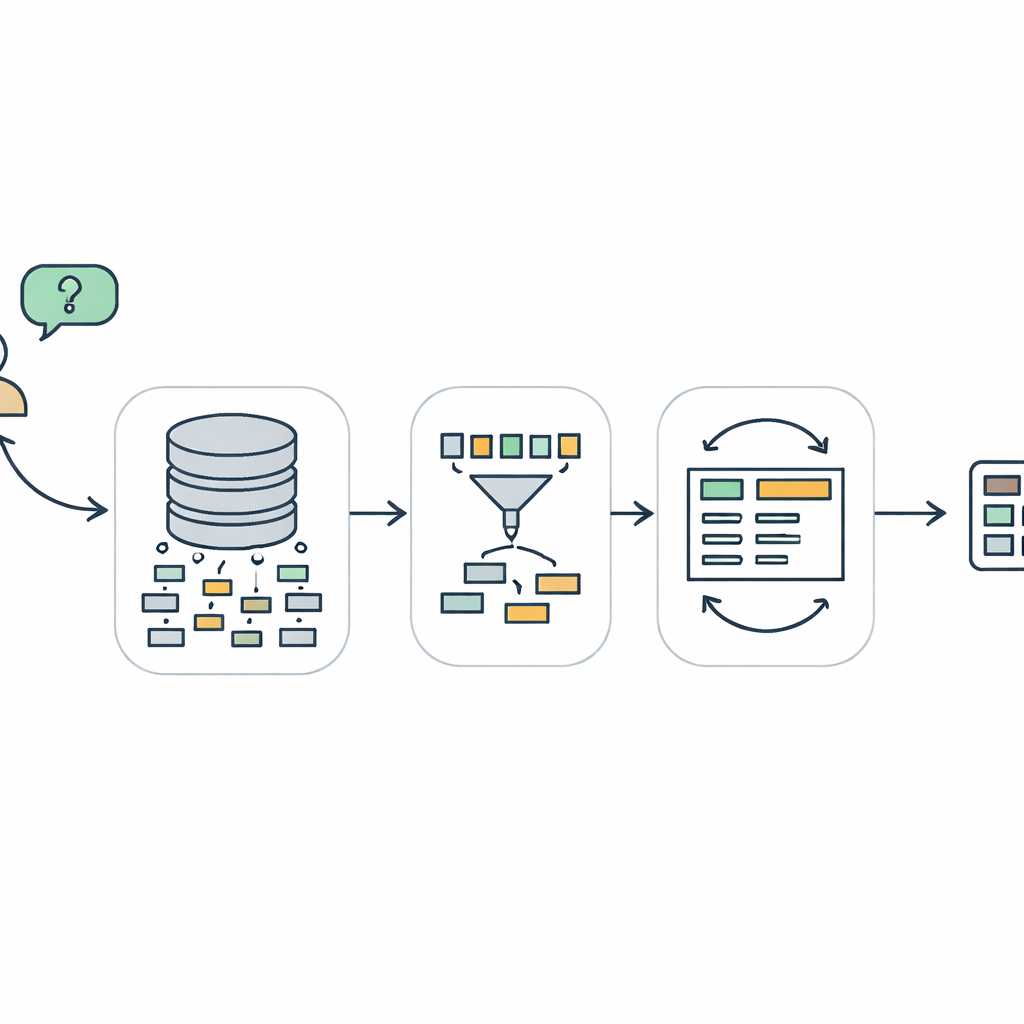
Por qué es tan difícil hablar con bases de datos
Cuando alguien escribe una pregunta como “¿Qué clientes compraron más de cinco productos el mes pasado?” un ordenador debe traducir eso a SQL, el lenguaje especializado que usan la mayoría de las bases de datos. Esta tarea, denominada text-to-SQL, parece sencilla pero es sorprendentemente compleja. El sistema debe entender lo que el usuario quiere, localizar las tablas y columnas correctas dentro de una estructura de base de datos a veces enorme y desordenada, y luego construir una consulta que sea tanto estructuralmente válida como fiel a la intención original. Los sistemas anteriores, incluidos los impulsados por grandes modelos de lenguaje, a menudo fallan cuando las preguntas involucran muchas tablas, lógicas anidadas o condiciones sutiles. Pueden generar consultas que parecen correctas pero que no se ejecutan o devuelven resultados erróneos cuando se ejecutan.
Un camino de tres pasos de la pregunta a la consulta
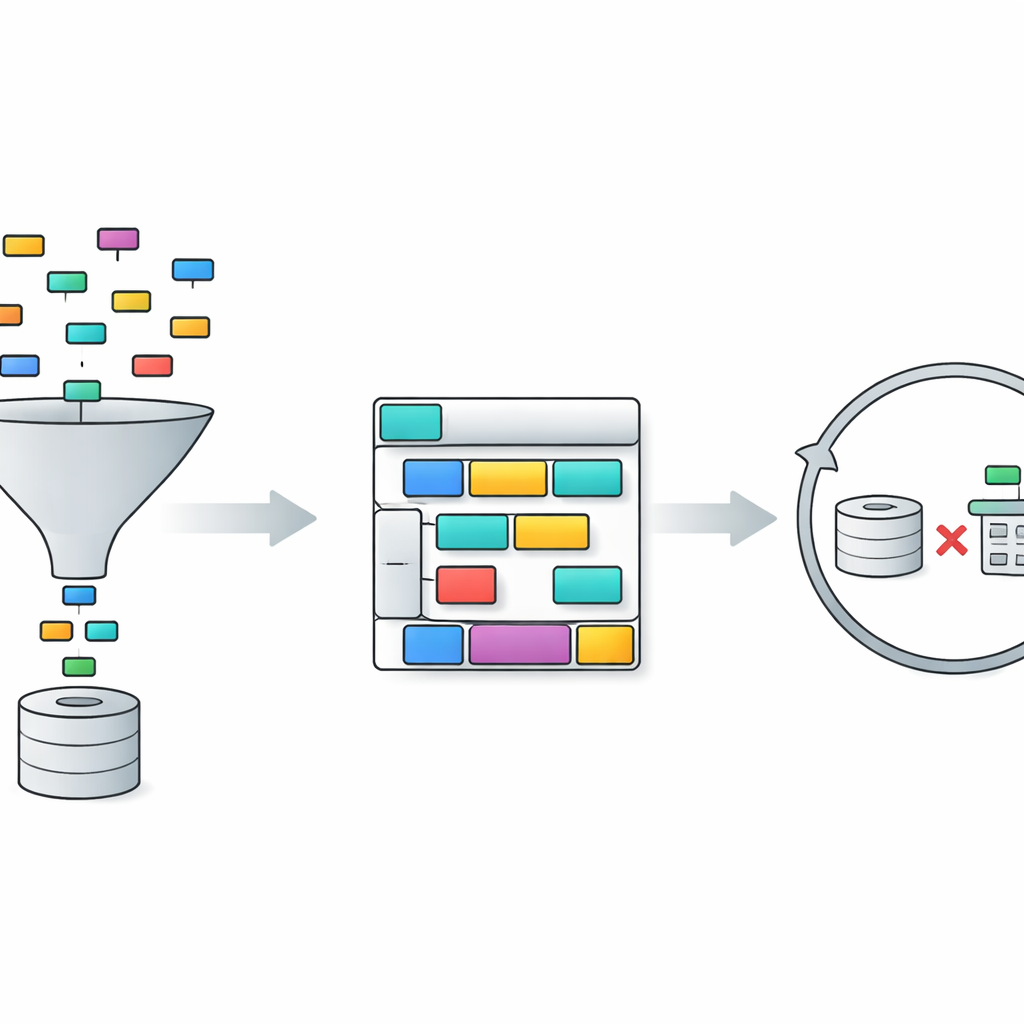
TriSQL aborda estos problemas con una canalización de tres etapas. Primero, un selector guiado por la pregunta examina las palabras del usuario y la estructura completa de la base de datos y decide qué tablas y columnas son realmente relevantes. En lugar de exponer ciegamente al modelo de lenguaje a todo el esquema, limita la vista a las piezas que importan. En segundo lugar, un generador consciente de la estructura planifica la forma de la consulta SQL antes de completar los detalles. Primero bosqueja un esqueleto de alto nivel—qué cláusulas se necesitan y cómo encajan—y luego inserta tablas concretas, JOINs y condiciones. Este enfoque de “estructura primero, contenido después” ayuda a preservar la gramática rígida de SQL, especialmente en consultas largas y enmarañadas. Finalmente, un refinador consciente de la complejidad revisa y mejora la consulta inicial, empleando distintas estrategias según la dificultad que presente la pregunta.
Adaptar el esfuerzo a la dificultad de la pregunta
La etapa de refinamiento es donde TriSQL hace un uso especialmente novedoso de los grandes modelos de lenguaje. El sistema evalúa la complejidad de cada pregunta y del borrador de consulta, considerando factores como cuántas tablas se unen, la profundidad de cualquier anidamiento y qué tipos de restricciones se usan. Para casos sencillos, aplica solo correcciones leves, como arreglar pequeñas faltas de sintaxis. Para casos intermedios, reorganiza cláusulas y asegura que la consulta coincida con el esquema seleccionado. Para las preguntas más exigentes, invoca al modelo de lenguaje para un razonamiento más profundo, a veces descomponiendo el problema en subtareas y probando consultas alternativas. De manera crucial, TriSQL ejecuta tanto la consulta original como la refinada contra la base de datos y usa su comportamiento—si se ejecutan, cuánto tardan y qué devuelven—para decidir qué versión mantener o si intentar otra ronda de refinamiento.
Poner el sistema a prueba
Para evaluar el rendimiento de TriSQL, los autores lo prueban en un punto de referencia ampliamente usado llamado Spider, junto con varias variantes más difíciles que introducen conocimiento de dominio, patrones de fraseo inusuales y estructuras de consulta más realistas. Miden dos cosas: coincidencia exacta, que verifica si la cadena SQL generada es idéntica a una referencia escrita por humanos, y exactitud de ejecución, que comprueba si realmente produce la respuesta correcta al ejecutarse. En estos conjuntos de datos, TriSQL alcanza la mayor exactitud de ejecución reportada hasta la fecha, manteniendo la coincidencia exacta competitiva con los mejores sistemas previos. También es más robusto: al pasar las preguntas de fáciles a extremadamente difíciles, el rendimiento de TriSQL cae mucho más suavemente que el de los métodos competidores. Experimentos adicionales en un conjunto de datos real sobre gestión de redes eléctricas muestran que el mismo marco puede manejar no solo consultas de recuperación de datos, sino también comandos de insertar, actualizar, borrar y creación de tablas. Adaptaciones piloto a bases de datos de grafos (Cypher) y a pipelines de MongoDB sugieren que el diseño de tres etapas puede extenderse más allá del SQL clásico.
Qué significa esto para el uso cotidiano de los datos
En términos sencillos, este trabajo nos acerca a un mundo en el que las personas puedan conversar con bases de datos complejas tan fácilmente como hoy chatean con motores de búsqueda. Al elegir cuidadosamente qué partes de la base de datos considerar, al planificar la estructura de una consulta antes de completar los detalles y al ajustar el uso de los grandes modelos de lenguaje según la dificultad de cada pregunta, TriSQL produce consultas que tienen más probabilidades de ejecutarse correctamente y devolver los resultados previstos. Aunque quedan desafíos—como tratar con preguntas ambiguas y bases de datos no vistas—el estudio demuestra que un diseño por etapas y pensado puede hacer que las interfaces en lenguaje natural para datos sean más potentes y más predecibles para los usuarios cotidianos.
Cita: Su, X., Gu, Y., Wang, P. et al. A robust natural language text-to-SQL generation framework with dynamic strategies based on LLMs. Sci Rep 16, 7892 (2026). https://doi.org/10.1038/s41598-026-39128-9
Palabras clave: text-to-SQL, interfaces en lenguaje natural, consultas a bases de datos, modelos de lenguaje de gran tamaño, robustez de consultas