Clear Sky Science · es
Un enfoque para tratar conjuntos de datos desequilibrados mediante el desplazamiento de la frontera
Por qué los casos raros importan en los datos cotidianos
Desde el fraude bancario y el diagnóstico médico hasta la predicción de la pérdida de clientes, muchas de las decisiones que pedimos a los ordenadores dependen de detectar eventos raros pero cruciales. En la mayoría de los conjuntos de datos reales, estos casos importantes están ampliamente superados en número por los ordinarios. Un modelo que ve mayoritariamente “el negocio habitual” puede volverse insensible a las situaciones que más nos importan. Este artículo presenta una nueva forma de reequilibrar esos datos sesgados para que los algoritmos de aprendizaje presten la atención adecuada a los casos raros y de alto impacto.
La trampa oculta de los datos descompensados
Cuando un tipo de ejemplo supera largamente a otro, los métodos estándar de aprendizaje automático tienden a centrarse en la mayoría y a descuidar de forma silenciosa la minoría. Un sistema de predicción de abandono, por ejemplo, puede etiquetar a casi todos como clientes leales y aun así presumir de alta precisión, simplemente porque los que realmente abandonan son muy pocos. Problemas similares aparecen en la detección de accidentes, la monitorización del fraude y el cribado médico, donde los casos positivos son raros pero costosos de pasar por alto. Las formas tradicionales de arreglar esto caen en dos grupos: ajustar el algoritmo de aprendizaje para que «se preocupe» más por la minoría, o remodelar los datos eliminando algunos casos de la mayoría (submuestreo) o creando casos adicionales de la minoría (sobremuestreo). Herramientas de sobremuestreo populares como SMOTE generan ejemplos sintéticos de la minoría, pero pueden, sin querer, saturar la delicada región fronteriza donde se encuentran ambas clases.
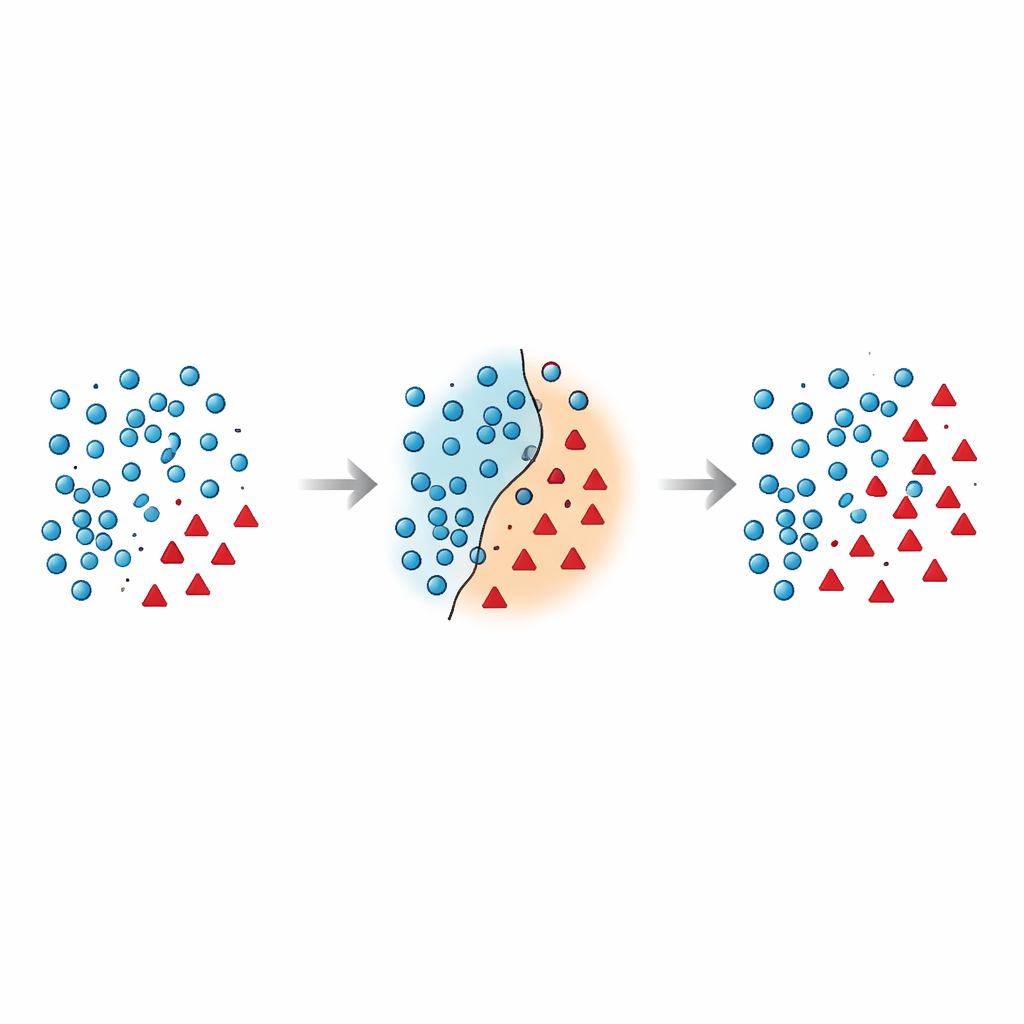
Por qué la frontera entre grupos es tan frágil
Los autores sostienen que los errores más peligrosos ocurren cerca de la frontera de decisión: la zona donde mayoritarios y minoritarios se solapan en el espacio de características. Muchas técnicas existentes añaden puntos sintéticos en esta región arriesgada sin limpiarla, o eliminan datos de forma agresiva y con ello suprimen ejemplos informativos. Investigaciones recientes han intentado domar esto mediante restricciones geométricas, estimaciones de densidad local o filtros de ruido, pero la mayoría de los métodos siguen tratando los puntos minoritarios in situ y rara vez replantean cómo deben manejarse los puntos mayoritarios cercanos a esa frontera. Esto deja un problema persistente: muestras superpuestas y ruidosas que confunden al clasificador y conducen a predicciones inestables, especialmente en datos nuevos.
Un método en dos pasos para ordenar la frontera
El artículo introduce Borderline Shifting Oversampling (BSO), un método de remodelado de datos en dos fases que apunta explícitamente a esta región fronteriza problemática. Primero, explora el vecindario de cada ejemplo mayoritario para decidir si se encuentra en una zona segura, en la frontera o en un lugar claramente erróneo (ruido). Los puntos mayoritarios rodeados por vecinos minoritarios se reclasifican hacia el lado minoritario o se marcan como ruido y se eliminan, limpiando y desplazando la frontera para que refleje mejor el patrón subyacente. En la segunda fase, el método genera nuevos puntos sintéticos de la minoría usando una interpolación similar a SMOTE, pero solo alrededor de muestras minoritarias próximas a la frontera refinada. Al concentrar nuevos datos donde son más informativos y evitar puntos claramente ruidosos, BSO construye un conjunto de entrenamiento que es tanto más equilibrado en tamaño como más limpio en su estructura.
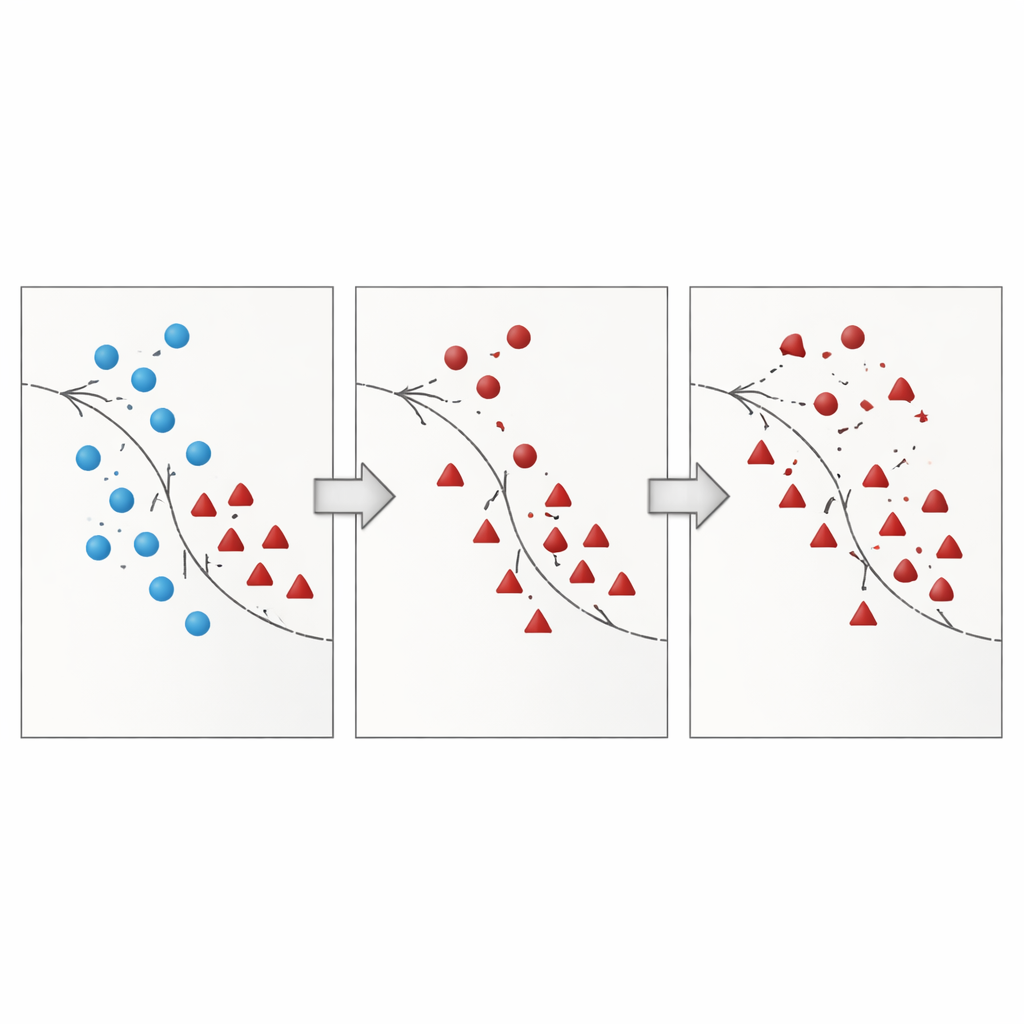
Poner el método a prueba
Para evaluar su eficacia en la práctica, los investigadores probaron BSO en 30 conjuntos de referencia con distintos grados de desequilibrio y solapamiento. Lo compararon con siete alternativas de uso extendido, incluyendo sobremuestreo y submuestreo aleatorio, SMOTE, Borderline‑SMOTE, NearMiss y dos métodos híbridos que combinan sobremuestreo con limpieza de ruido (SMOTE‑Tomek y SMOTE‑ENN). Tres clasificadores comunes —máquinas de vectores de soporte, Naïve Bayes y bosques aleatorios— se entrenaron con cada conjunto re‑muestreado. En lugar de depender de la precisión bruta, el estudio empleó métricas más informativas bajo desequilibrio, como F1, G‑mean, recall, precisión y el área bajo la curva ROC (AUC). En casi todos los conjuntos y clasificadores, BSO obtuvo puntuaciones superiores o comparables mostrando además menos variación, lo que indica que sus beneficios fueron consistentes y no dependientes de un modelo o configuración particulares.
Qué significa esto para las decisiones del mundo real
En términos cotidianos, el enfoque Borderline Shifting actúa como un editor cuidadoso para datos desordenados: limpia ejemplos confusos cerca de la línea divisoria entre clases y luego añade la cantidad justa de casos minoritarios realistas en los lugares adecuados. El resultado es que los algoritmos de aprendizaje mejoran en reconocer eventos raros pero importantes sin dejarse engañar por solapamientos ruidosos. Para aplicaciones como la detección de fraude, la predicción de accidentes o la triaje médica —donde pasar por alto un caso minoritario puede ser costoso— este método ofrece una vía práctica para que los modelos sean más justos, más sensibles y más fiables, todo ello añadiendo solo una sobrecarga computacional moderada.
Cita: Malhat, M.G., Elsobky, A.M., Keshk, A.E. et al. An approach for handling imbalanced datasets using borderline shifting. Sci Rep 16, 8264 (2026). https://doi.org/10.1038/s41598-026-39118-x
Palabras clave: desequilibrio de clases, sobremuestreo, frontera de decisión, detección de anomalías, robustez en aprendizaje automático