Clear Sky Science · es
Un método para compilar objetos geográficos de mapas en imágenes satelitales basado en datos de mapas vectoriales mediante aprendizaje profundo
Por qué importa cambiar lo que muestran los mapas
Los mapas en línea a menudo parecen ventanas al mundo real, pero lo que se ve desde arriba está cuidadosamente diseñado. Las imágenes satelitales en mapas se valoran porque se parecen a lugares reales; sin embargo, a veces necesitamos ocultar instalaciones sensibles, limpiar escenas desordenadas o asegurar que distintos tipos de mapas concuerden entre sí. Este artículo presenta una nueva forma de “editar” automáticamente imágenes satelitales usando inteligencia artificial, de modo que edificios y carreteras puedan eliminarse, añadirse, desplazarse o remodelarse mientras la imagen continúa pareciendo natural y creíble. 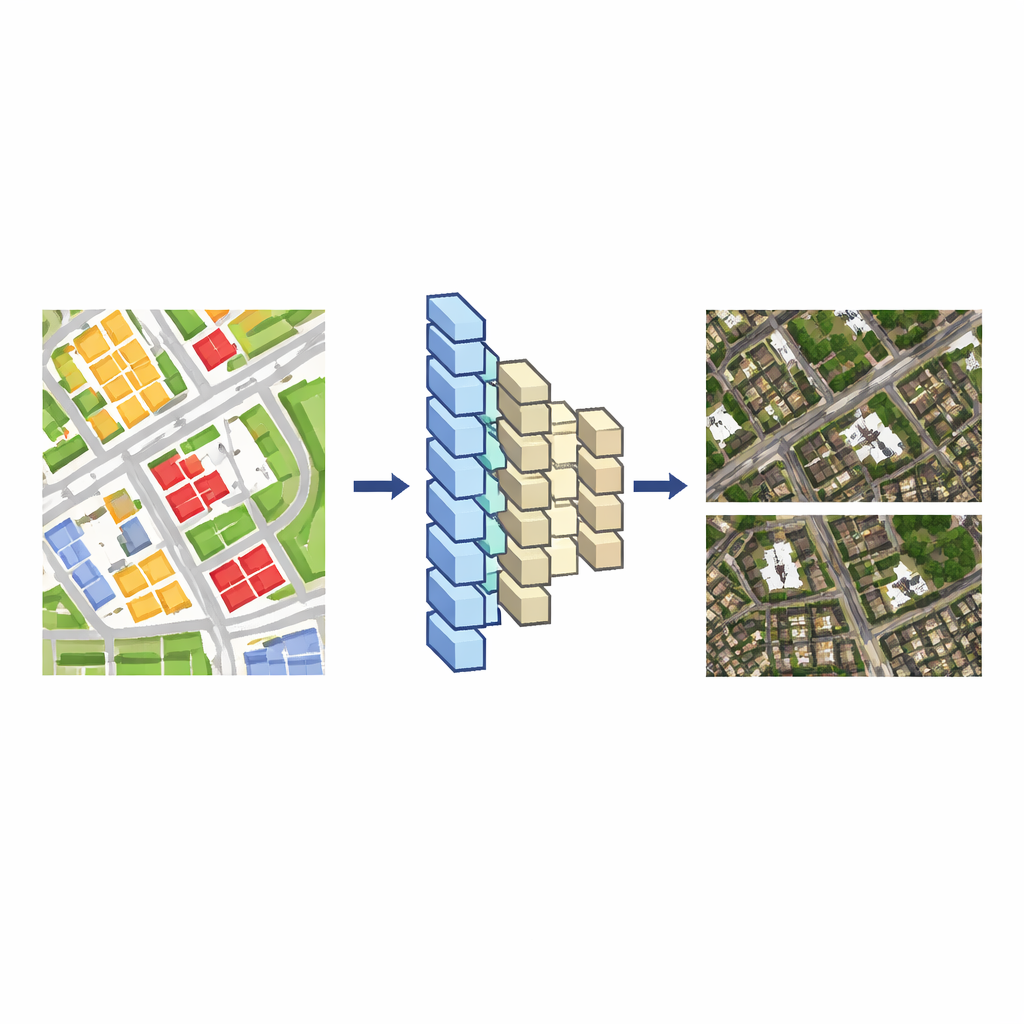
De dibujos simples a vistas realistas
Los sistemas de mapas modernos suelen manejar dos tipos de datos geográficos. Uno es la propia imagen satelital, un mosaico denso de píxeles. El otro es un mapa vectorial, un dibujo más limpio hecho de líneas y formas que señalan carreteras, edificios, ríos y más. Editar el mapa vectorial es relativamente fácil, pero cambiar manualmente la imagen satelital correspondiente es lento y laborioso, porque los píxeles de cada edificio se mezclan con sombras, árboles y estructuras cercanas. La idea clave de los autores es enseñar a un modelo de aprendizaje profundo a traducir esos dibujos vectoriales en imágenes satelitales realistas. Una vez que el modelo ha aprendido este enlace, cualquier cambio realizado en el mapa vectorial puede transformarse automáticamente en un cambio coherente en la vista satelital.
Enseñar a una IA a imaginar ciudades
Para construir este traductor, los investigadores empiezan con áreas donde un mapa vectorial y una imagen satelital cubren la misma región a una escala similar. Cortan ambos en muchas pequeñas teselas, emparejando cada tesela vectorial con su tesela de imagen correspondiente, y usan estos pares como datos de entrenamiento. Una red neuronal codificador–decodificador—similar a herramientas empleadas para traducción de imagen a imagen—aprende cómo la disposición de bloques y líneas coloreadas en la tesela vectorial se relaciona con tejados, calles y vegetación en la tesela satelital. Comparan dos diseños de red populares, UNet++ y Pix2Pix, y encuentran que Pix2Pix produce imágenes tipo satélite que se ajustan más a la realidad y entrena de forma fiable, por lo que se convierte en su modelo base.
Enfocar el modelo en los lugares a cambiar
Aprender simplemente de toda la ciudad no es suficiente cuando se quiere ajustar objetos concretos con limpieza. Para agudizar la habilidad del modelo alrededor de las áreas objetivo, los autores usan transferencia de aprendizaje. Extraen teselas de entrenamiento adicionales que rodean los edificios o carreteras que piensan editar y ejecutan una fase corta de entrenamiento adicional usando solo estos ejemplos locales. Este ajuste fino mejora mucho la capacidad del modelo para reproducir esos barrios, haciendo que las ediciones posteriores se vean más nítidas y precisas. 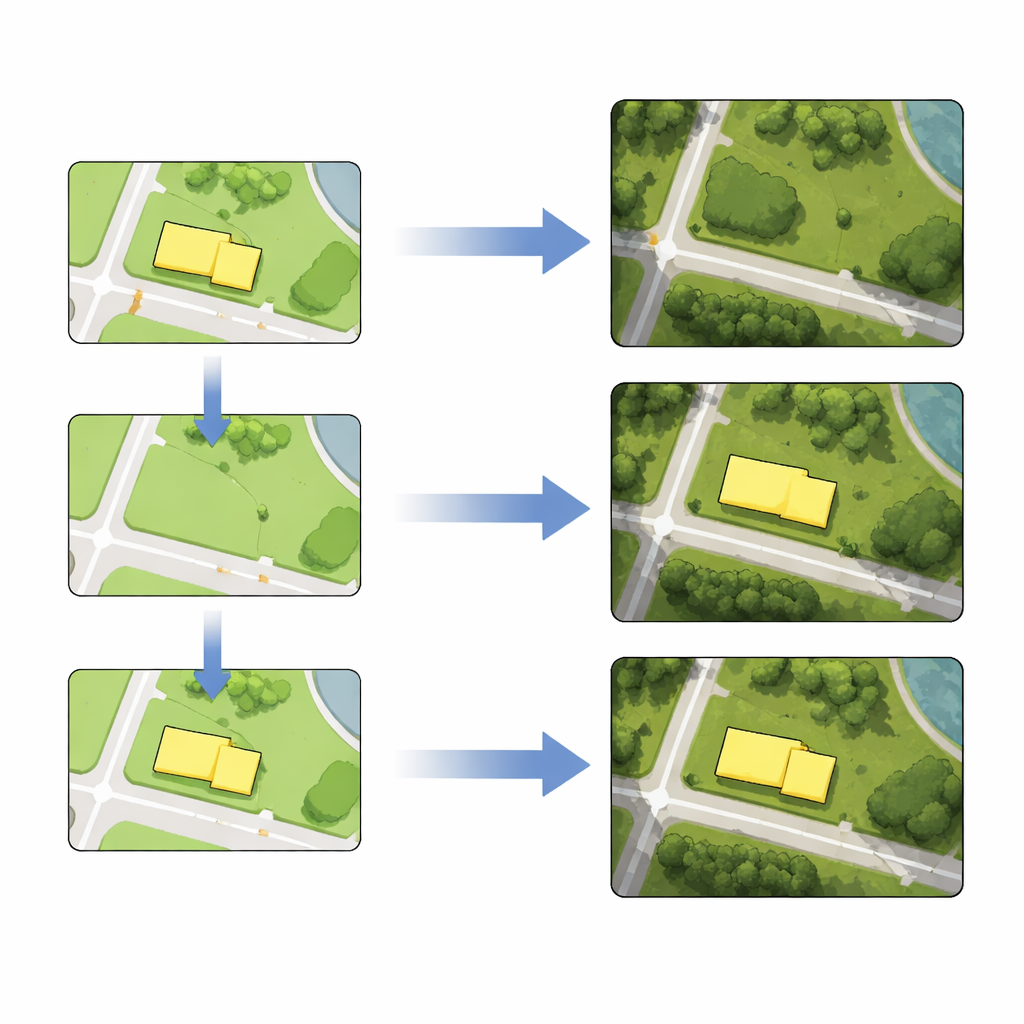
Editar edificios y carreteras como capas de mapa
Con el modelo afinado, compilar mapas de imágenes satelitales se convierte en una receta de tres pasos. Primero, un cartógrafo edita el mapa vectorial: borrar un edificio, dibujar una nueva carretera, remodelar una manzana o mover un objeto a una nueva posición. Segundo, las teselas editadas del mapa vectorial se introducen en la red entrenada, que genera nuevas teselas satelitales que reflejan el cambio deseado preservando el detalle y la textura circundantes. Tercero, estas teselas generadas reemplazan las teselas de imagen originales. Usando datos reales de Berlín, los autores demuestran las cuatro operaciones—eliminación, inserción, distorsión y desplazamiento—tanto para huellas de edificios como para líneas de carretera, ya sea de una en una o en lotes. Las mediciones muestran que las posiciones de los objetos editados en las imágenes generadas difieren de sus contrapartes vectoriales por solo unos pocos píxeles, una precisión aceptable para muchas tareas cartográficas.
Lo que esto significa para los mapas del futuro
En términos sencillos, el estudio muestra que una vez que una IA ha aprendido cómo se corresponden los mapas vectoriales y las imágenes satelitales, se puede editar el dibujo simple y dejar que el modelo repinte una vista aérea creíble para que coincida. Esto abre la puerta a mapas de imágenes satelitales que pueden personalizarse: ocultar sitios sensibles, aclarar escenas complejas o fusionar espacios reales e imaginados, como mundos de juego y entornos virtuales. Al mismo tiempo, pone de relieve el poder—y el riesgo—de la geografía “deepfake”, donde imágenes aéreas con apariencia realista pueden dejar de ser fotografías directas del mundo tal como es.
Cita: Du, J., Zeng, D., Cai, K. et al. A method for compiling satellite image map geographic objects based on vector map data via deep learning. Sci Rep 16, 9295 (2026). https://doi.org/10.1038/s41598-026-39096-0
Palabras clave: imágenes satelitales, aprendizaje profundo, edición de mapas, teledetección, cartografía deepfake