Clear Sky Science · es
Los grandes modelos de lenguaje muestran efectos parecidos al Dunning-Kruger en la verificación de hechos multilingüe
Por qué la verificación inteligente de hechos importa para todos
La desinformación ahora se propaga más rápido que nunca, moldeando lo que la gente cree sobre salud, política, ciencia y la vida cotidiana. Muchas plataformas y redacciones están empezando a apoyarse en la inteligencia artificial—especialmente en grandes modelos de lenguaje, o LLM—para ayudar a comprobar si afirmaciones virales son verdaderas o falsas. Este estudio plantea una pregunta engañosamente simple pero crucial: cuando dejamos que estos sistemas juzguen hechos, ¿con qué frecuencia aciertan, cuánto muestran seguridad y cambia esto según los distintos idiomas y regiones del mundo?
Cómo los investigadores pusieron a prueba a la IA con rumores del mundo real
En lugar de inventar ejemplos artificiales, los autores construyeron sus pruebas a partir de 5.000 afirmaciones genuinas que organizaciones profesionales de verificación de hechos de todo el mundo ya habían investigado. Estas afirmaciones cubrían 47 idiomas y procedían tanto del Norte Global como del Sur Global, reflejando la realidad desordenada y multicultural de los rumores en línea. Solo se incluyeron enunciados con veredictos claros de “verdadero” o “falso”—acordados por múltiples verificadores—creando así una sólida verdad de referencia para la comparación.
Después ejecutaron nueve modelos de lenguaje ampliamente usados, desde sistemas abiertos más pequeños hasta comerciales avanzados, sobre cada afirmación. Para reproducir cómo la gente realmente habla con chatbots, la mayoría de los prompts fueron preguntas sencillas como “¿Esto es verdad?” o “¿Esto es falso?”, redactadas en el mismo idioma que la afirmación. Una cuarta configuración, de estilo más profesional, usó una instrucción detallada en inglés que convertía al modelo en un verificador virtual y pedía salidas estructuradas. Anotadores humanos leyeron con cuidado las respuestas de los modelos y las etiquetaron como que decían que la afirmación era verdadera, falsa o se negaban a dar un veredicto claro.
Medir no solo el acierto o el error, sino también cuándo decir “no lo sé”
El equipo hizo algo más que contabilizar aciertos y errores. Usaron tres medidas clave para capturar el comportamiento de los modelos. Primero, la “precisión selectiva” observó con qué frecuencia un modelo acertaba cuando realmente tomaba posición y declaraba una afirmación verdadera o falsa. Segundo, la “precisión con abstención favorable” trató como aceptable, e incluso deseable, que el modelo admitiera incertidumbre en lugar de adivinar, algo vital en áreas sensibles como la medicina o las elecciones. Tercero, la “tasa de certeza” siguió con qué frecuencia un modelo daba una respuesta definitiva, sirviendo como un sustituto aproximado de cuán confiado se comportaba.
El prompt de estilo profesional, con su guía paso a paso, elevó consistentemente la precisión en todos los modelos. Pero también expuso una compensación: los modelos más pequeños a menudo se volvían más decididos sin volverse más fiables, mientras que los modelos más grandes usaron la estructura para dar menos respuestas, pero mejores. Los prompts cotidianos, tipo chat, produjeron comportamientos más cautelosos, especialmente en modelos más débiles, pero también redujeron algo su precisión.
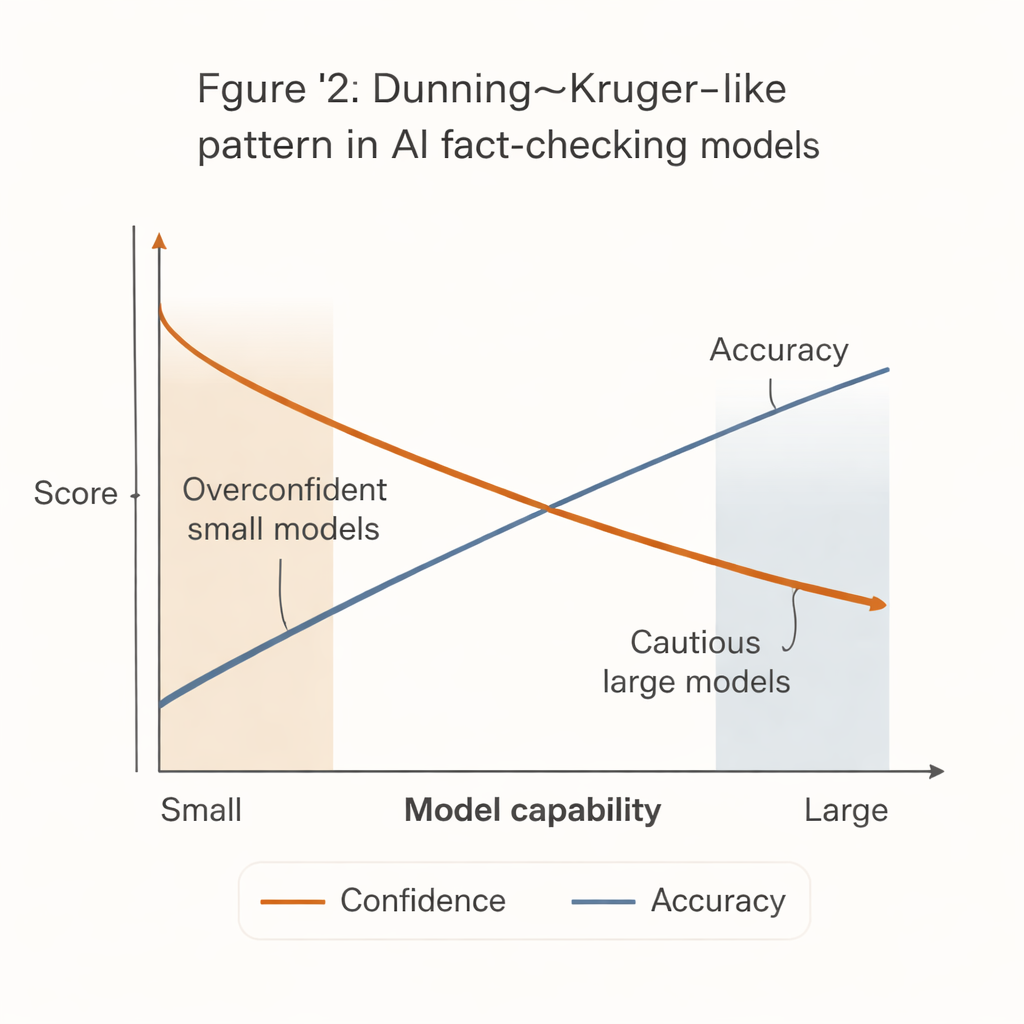
Cuando los sistemas menos capaces actúan con más seguridad
Surgió un patrón llamativo que refleja el conocido efecto Dunning–Kruger en la psicología humana: los sistemas menos capaces actuaban con mayor confianza. Los modelos pequeños y económicos tendían a emitir veredictos firmes sobre la gran mayoría de las afirmaciones, pero con una precisión notablemente menor. En contraste, los modelos más potentes—como versiones avanzadas de GPT—eran mucho más precisos cuando se comprometían, pero mucho más propensos a abstenerse, especialmente ante enunciados difíciles o ambiguos.
Esta “brecha confianza-competencia” tiene consecuencias en el mundo real. Muchas redacciones con presupuestos ajustados, organizaciones de la sociedad civil y medios locales no pueden permitirse los sistemas de IA más potentes. Son más propensos a adoptar modelos más pequeños y baratos que parecen decisivos pero fallan con más frecuencia. Si estas herramientas se integran en flujos de trabajo o sistemas de moderación comunitaria sin salvaguardas cuidadosas, podrían, en realidad, amplificar la desinformación al producir verificaciones de hechos confidentes pero incorrectas.
Desempeño desigual según idiomas y regiones
El estudio también revela que estos sistemas no rinden igual para todos. En varios idiomas principales, los modelos en general lo hicieron mejor con afirmaciones en inglés y algo peor con portugués e hindi. Los modelos más grandes tendieron a responder con más cautela en idiomas no ingleses, pero aun así superaron en precisión a los más pequeños. Cuando los autores compararon afirmaciones vinculadas al Norte Global y al Sur Global, la mayoría de los modelos tropezaron más con estas últimas. Los sistemas pequeños con frecuencia seguían mostrándose confiados mientras perdían precisión, mientras que los modelos grandes mostraron caídas mayores en la certeza pero reducciones menores en la corrección, lo que sugiere que percibían su propia incertidumbre y se contenían.
Qué significa esto para el futuro de las herramientas de IA confiables
Para un público no especializado, el mensaje central es claro: los verificadores de hechos por IA de hoy están lejos de ser iguales, y los más accesibles pueden ser los más engañosos. Los modelos potentes pueden ser cautelosos y precisos, pero son caros y a veces demasiado reticentes. Los modelos más débiles son audaces pero más propensos a equivocarse, especialmente fuera del inglés y en historias del Sur Global. Los autores sostienen que la IA debería apoyar, no reemplazar, a los verificadores humanos, y que las decisiones de política y diseño deben impulsar una mejor calibración—enseñar a los sistemas cuándo mantenerse en silencio—y un acceso más equitativo a herramientas de alta calidad. De lo contrario, la misma tecnología creada para combatir la desinformación podría profundizar las desigualdades informativas que pretende resolver.
Cita: Qazi, I.A., Khan, Z., Ghani, A. et al. Large language models show Dunning-Kruger-like effects in multilingual fact-checking. Sci Rep 16, 7594 (2026). https://doi.org/10.1038/s41598-026-39046-w
Palabras clave: desinformación, verificación de hechos, grandes modelos de lenguaje, confianza de la IA, sesgo multilingüe