Clear Sky Science · es
Un marco híbrido LSTM-GRU para la clasificación del cáncer de pulmón usando el algoritmo GWO-WOA para ajuste de hiperparámetros y BPSO para selección de características
Por qué esto importa para la salud cotidiana
Detectar el cáncer de pulmón de forma temprana puede salvar vidas, pero muchas personas no reciben exploraciones avanzadas hasta que ya es demasiado tarde. Este estudio explora si revisiones sencillas basadas en preguntas —sobre edad, tabaquismo, síntomas y hábitos diarios— pueden combinarse con la inteligencia artificial moderna para identificar a personas con alto riesgo mucho antes de que aparezca la enfermedad grave. Al aprovechar al máximo cuestionarios económicos y modelos informáticos inteligentes, el trabajo apunta hacia herramientas de cribado más rápidas y accesibles que en el futuro podrían apoyar a médicos y programas de salud pública en todo el mundo.
Convertir preguntas simples en señales útiles
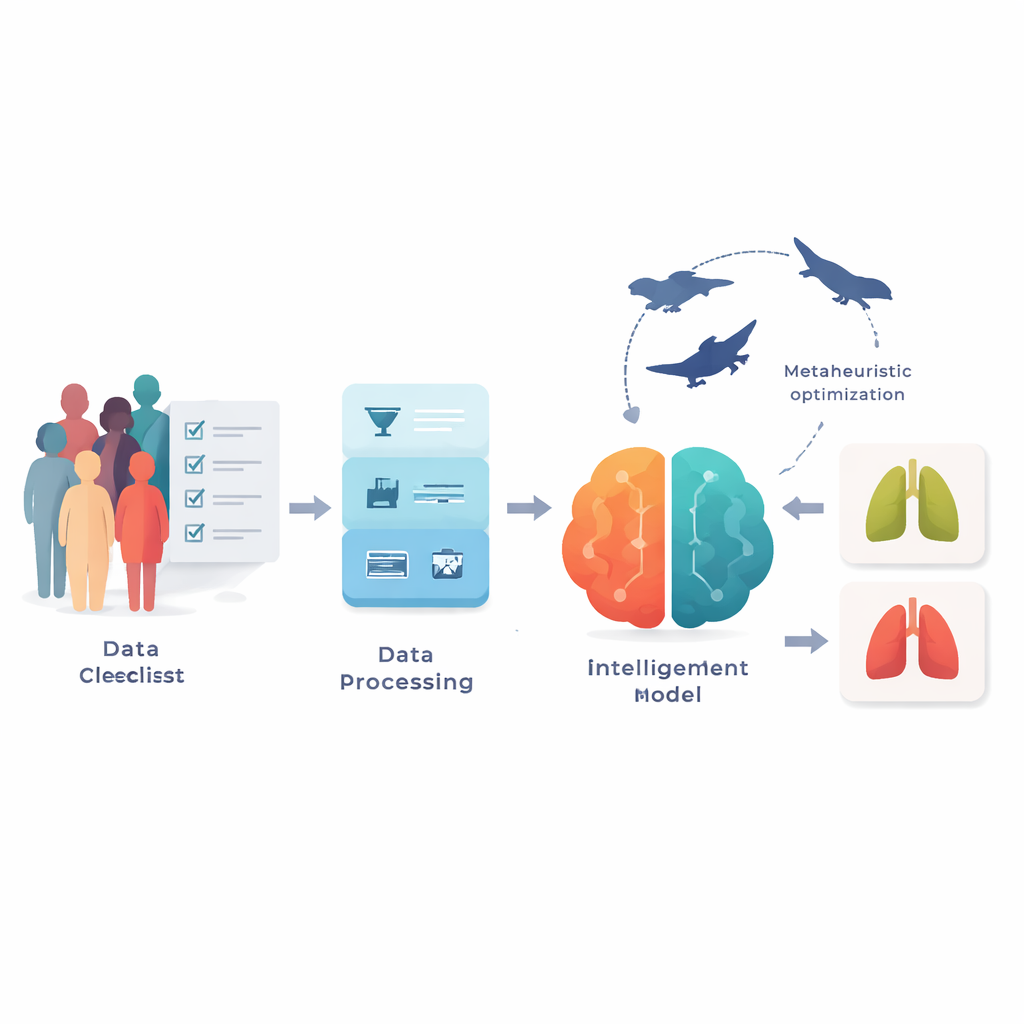
Los investigadores trabajaron con dos conjuntos de datos públicos del sitio Kaggle, que en conjunto cubren más de 3.300 personas. En lugar de imágenes médicas, cada registro contiene 15 ítems que uno podría ver en un formulario clínico: edad, sexo, hábito de fumar, dedos amarillentos, tos, dificultad para respirar, dolor torácico y factores de riesgo y síntomas similares, además de una etiqueta que indica si había cáncer de pulmón. Dado que los datos de encuestas del mundo real son desordenados, el equipo primero limpió la información corrigiendo entradas faltantes, eliminando duplicados y alineando cómo se codificaban las respuestas entre ambos conjuntos. También ajustaron las variables para que todas las características quedaran en una escala similar y emplearon un método de balanceo para corregir una fuerte inclinación hacia casos de cáncer en el conjunto de datos más pequeño, ayudando al modelo a evitar un sesgo que le hiciera predecir solo la clase mayoritaria.
Dejar que el ordenador elija las preguntas más reveladoras
No todas las preguntas de un formulario son igualmente útiles para detectar la enfermedad, y usar demasiadas puede confundir a un modelo. Para centrarse en lo que más importa, los autores emplearon una estrategia de búsqueda inspirada en enjambres llamada Optimización por Enjambre de Partículas Binaria (BPSO). En términos sencillos, se prueban en paralelo muchos “conjuntos de preguntas” candidatos, que se desplazan por el espacio de posibilidades copiando y mejorando a los mejores intérpretes. Con el tiempo, este proceso se fijó en conjuntos compactos de aproximadamente siete preguntas clave, destacando de forma repetida características como tabaquismo, dedos amarillentos, tos, dolor torácico, sibilancias, dificultad para respirar y enfermedad crónica. Estos conjuntos focalizados mejoraron la precisión en varios puntos porcentuales frente al uso de las 15 preguntas, además de hacer el modelo final más fácil de interpretar y más rápido de ejecutar.

Un motor más inteligente para leer patrones en las respuestas
Para convertir las respuestas del cuestionario en una predicción binaria de cáncer, el equipo construyó un modelo híbrido que combina dos unidades de aprendizaje profundo relacionadas y a menudo usadas para secuencias: Long Short-Term Memory (LSTM) y Gated Recurrent Unit (GRU). Aunque las respuestas de una encuesta no son series temporales como el habla o el vídeo, los grupos de síntomas y hábitos aún forman patrones que pueden tratarse como secuencias cortas. El modelo alimenta primero las preguntas seleccionadas a través de capas LSTM que pueden almacenar y olvidar información de forma selectiva, y luego a través de capas GRU que refinan esos patrones con menos pasos internos y menor coste computacional. Para evitar el diseño por ensayo y error, los autores ajustaron parámetros cruciales —como la tasa de aprendizaje, el número de unidades ocultas, el tamaño de lote y el dropout— usando una segunda capa de búsqueda inspirada en la naturaleza que mezcla la exploración amplia de los “lobos grises” con los ajustes finos de las “ballenas”. Este optimizador conjunto busca combinaciones de hiperparámetros que ofrezcan consistentemente alta precisión durante la validación cruzada.
Qué tan bien funcionó el sistema
Tras el entrenamiento, el modelo híbrido LSTM–GRU se probó frente a varias líneas base sólidas, incluidas redes LSTM y GRU independientes, una red neuronal convolucional, máquinas de vectores de soporte tradicionales y métodos basados en árboles como bosques aleatorios y gradient boosting. En el conjunto de datos más pequeño, de 309 personas, el sistema propuesto clasificó correctamente todos los casos en la partición de prueba retenida, alcanzando un 100 % de precisión, precisión (precision), recall y F1-score. En el conjunto mayor, de 3.000 personas, se mantuvo casi perfecto, con alrededor de 99,3 % de precisión y puntuaciones igualmente altas en las demás medidas, superando a todos los modelos rivales de aprendizaje profundo y clásicos. Los autores también mostraron que su estrategia en dos etapas —primero seleccionar preguntas con la búsqueda en enjambre y luego afinar la red híbrida con el optimizador de lobos y ballenas— ofrecía resultados más estables a lo largo de repeticiones de validación cruzada que configuraciones más simples.
Qué significa esto para el cribado futuro del pulmón
En términos prácticos, este trabajo muestra que un sistema de IA bien diseñado puede leer respuestas ordinarias de un cuestionario y separar con gran precisión a personas con y sin cáncer de pulmón en conjuntos de datos de referencia. No sustituye a las exploraciones, a los médicos ni a los ensayos clínicos, y los autores subrayan que sus datos son limitados y aún no están listos para uso directo en hospitales. Aun así, el enfoque demuestra que combinar una selección inteligente de preguntas con motores de aprendizaje profundo finamente ajustados puede convertir formularios de bajo coste en potentes herramientas de alerta temprana. Con pruebas adicionales en poblaciones más grandes y clínicamente curadas y mejores métodos de explicación que muestren por qué el modelo señala a una persona como de alto riesgo, sistemas similares podrían en el futuro ayudar a decidir quién debe ser referido para pruebas de imagen más detalladas, apoyando diagnósticos más tempranos mientras se mantiene el cribado asequible y no invasivo.
Cita: Amrir, M.M.S., Ayid, Y.M., Elshewey, A.M. et al. A hybrid LSTM-GRU framework for lung cancer classification using GWO-WOA algorithm for hyperparameter tuning and BPSO for feature selection. Sci Rep 16, 8600 (2026). https://doi.org/10.1038/s41598-026-39020-6
Palabras clave: cribado del cáncer de pulmón, datos de cuestionarios, aprendizaje profundo, selección de características, IA médica