Clear Sky Science · es
Una estrategia de control humanoide basada en aprendizaje profundo por refuerzo para mejorar la comodidad en robots de rehabilitación de miembros inferiores
Robots que ayudan a las personas a volver a caminar
Cuando alguien tiene dificultades para caminar tras un ictus o una lesión medular, la terapia puede ser lenta, fatigosa y molesta. Los robots de rehabilitación de miembros inferiores están diseñados para soportar y guiar las piernas del paciente durante la práctica, pero las máquinas actuales a menudo resultan rígidas y “robóticas”. Este estudio explora cómo dotar a estos robots de un comportamiento más humano —mediante algoritmos de aprendizaje avanzados— puede hacer que el entrenamiento sea más suave, más natural y, en última instancia, más eficaz para los pacientes.
Por qué la práctica de la marcha debe sentirse natural
Con el envejecimiento de la población, más personas viven con problemas serios para caminar y muchas recurren a la rehabilitación asistida por robot. Los robots tradicionales siguen trayectorias de pierna preprogramadas y usan reglas de control sencillas para mover las articulaciones. Aunque fiables, estos métodos se baten en el mundo desordenado del movimiento humano: la marcha de cada persona es algo distinta y un robot rígido puede tirar o empujar de formas que resultan incómodas o incluso dolorosas. Los autores sostienen que, para que la rehabilitación funcione bien, el robot no solo debe mantener al paciente erguido y en movimiento, sino también adaptarse a patrones de marcha naturales y minimizar las fuerzas que ejerce sobre el cuerpo.
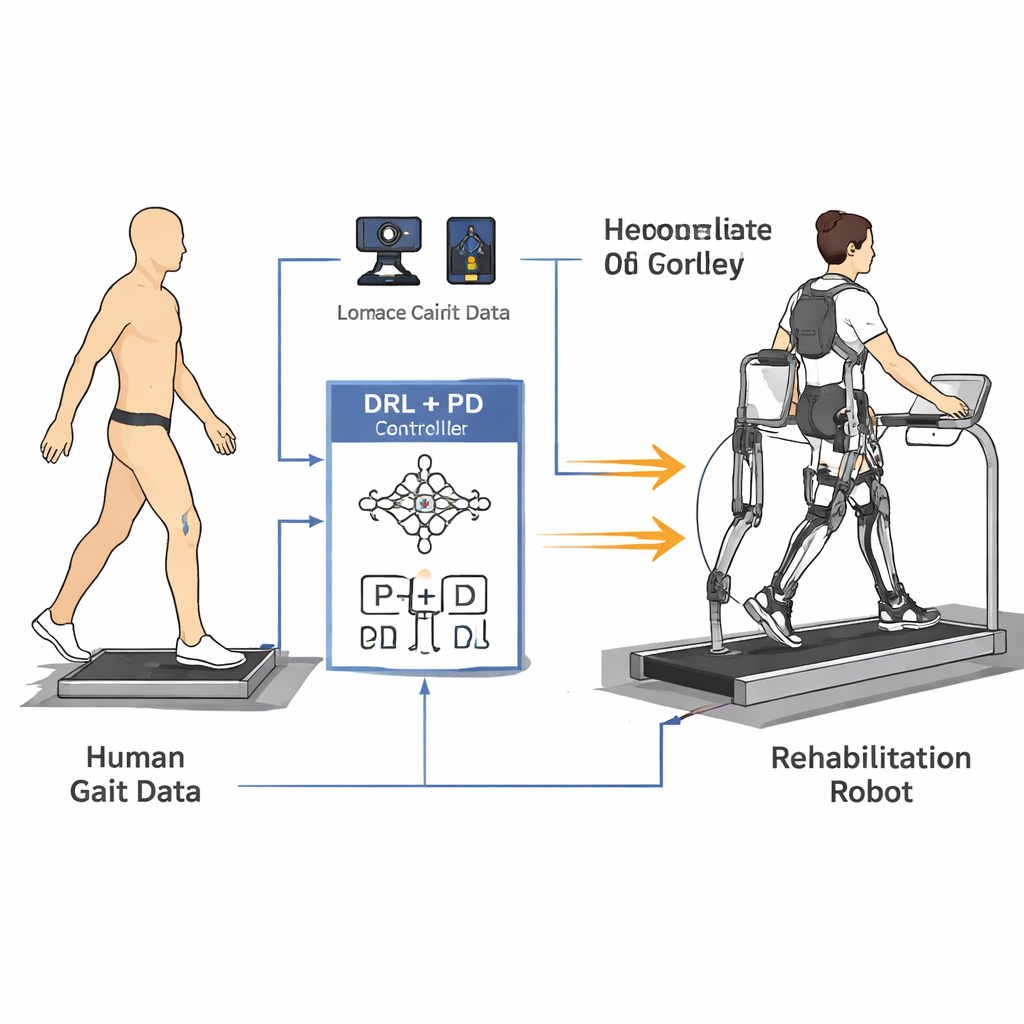
Aprender de pasos humanos reales
Para enseñar al robot cómo caminan realmente las personas, los investigadores primero construyeron un modelo matemático simplificado de las piernas y el tronco. Luego registraron datos de la marcha de cinco voluntarios sanos usando un sistema de captura de movimiento 3D de alta precisión y plataformas de fuerza en el suelo. Marcadores reflectantes en caderas, rodillas, tobillos y el tronco les permitieron calcular cómo se movía cada articulación a través de un paso completo, mientras que los sensores bajo los pies midieron la presión que cada pierna ejercía contra el suelo. A partir de estas mediciones, crearon curvas de referencia suaves para los ángulos de cadera y rodilla y siguieron cómo cambiaban las fuerzas articulares en el tiempo, capturando tanto la forma como el ritmo de la marcha normal.
Un controlador más inteligente que sigue siendo seguro
El núcleo del artículo es una nueva estrategia de control “humanoide” que combina aprendizaje profundo por refuerzo (DRL) con un controlador clásico proporcional-derivativo (PD). El DRL es un tipo de inteligencia artificial en el que un agente virtual prueba acciones, observa los resultados y descubre gradualmente qué funciona mejor maximizando una señal de recompensa. En este caso, el agente se sitúa encima del controlador PD: percibe los ángulos y las velocidades de las articulaciones del robot y decide qué pares aplicar, mientras que la capa PD se asegura de que las articulaciones no se desvíen demasiado de ángulos objetivo seguros y de tipo humano. La función de recompensa está cuidadosamente diseñada para fomentar una marcha estable hacia adelante penalizando todo lo que podría resultar molesto para un paciente—como movimientos bruscos, fuerzas grandes en las articulaciones o posturas inseguras como inclinaciones excesivas o poca elevación del pie.
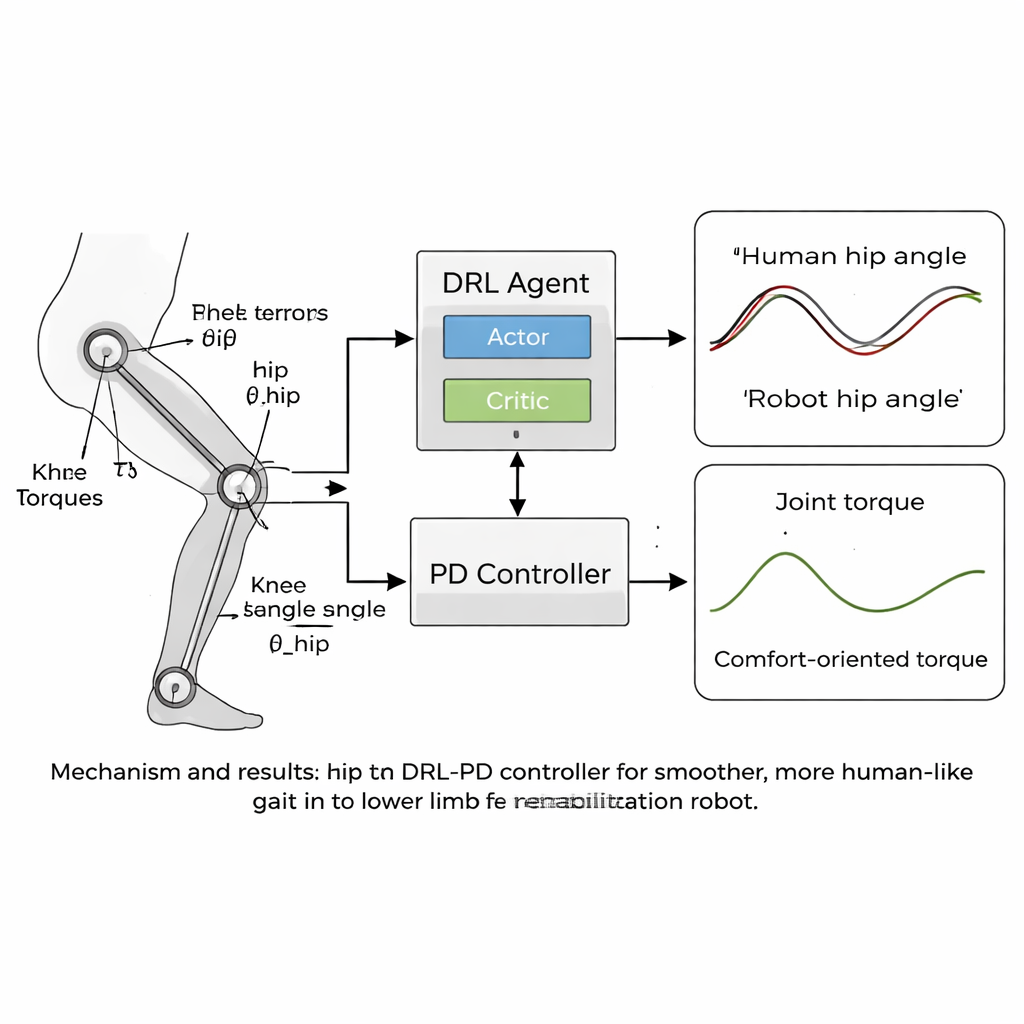
Movimiento más suave, más cercano a una marcha humana
El equipo probó su enfoque en simulaciones por ordenador usando un modelo de robot de rehabilitación de miembros inferiores con articulaciones de cadera y rodilla que coincidían con sus datos de marcha. A lo largo de miles de episodios de entrenamiento, el controlador DRL-PD aprendió a producir un ciclo repetitivo de marcha en el que los ángulos articulares seguían de cerca los patrones de referencia humanos. Las caderas y las rodillas del robot se movieron en bucles regulares y estables, señal de una marcha fiable y repetible. De forma crucial, los pares necesarios para mover las articulaciones se hicieron más suaves y menores en comparación con un controlador PD estándar. Las medidas cuantitativas mostraron que los errores de seguimiento se redujeron a solo unas centésimas de radián, y la tasa a la que cambiaban los pares articulares —un indicador de lo “bruscas” que sentirían las fuerzas los pacientes— se redujo en más de la mitad. El controlador también se mantuvo estable incluso cuando las masas de las piernas del modelo variaron varios porcentajes, lo que sugiere que podría tolerar diferencias del mundo real entre usuarios.
Qué significa esto para los robots de rehabilitación futuros
Para los no especialistas, la conclusión es clara: al permitir que un robot aprenda los ritmos y límites de la marcha humana a partir de datos reales, y recompensarlo por ser suave y gentil, podemos diseñar máquinas que ayuden a practicar la marcha de una manera que se sienta más natural y menos estresante. Los pacientes podrían mostrarse más dispuestos a participar en sesiones más largas y frecuentes si el robot se mueve con ellos en lugar de contra ellos. Aunque los resultados actuales provienen de simulaciones y requieren ordenadores potentes para el entrenamiento, una vez completado el aprendizaje el controlador puede ejecutarse de forma eficiente en dispositivos reales. Los autores consideran este trabajo como un paso hacia robots de rehabilitación personalizados y adaptativos que se ajusten a la marcha y a las necesidades de comodidad de cada paciente, mejorando potencialmente tanto la recuperación como la calidad de vida.
Cita: Jin, Y., Zhang, J., Li, W. et al. A humanoid control strategy based on deep reinforcement learning for enhanced comfort in lower limb rehabilitation robots. Sci Rep 16, 7370 (2026). https://doi.org/10.1038/s41598-026-39011-7
Palabras clave: robots de rehabilitación, entrenamiento de la marcha, aprendizaje profundo por refuerzo, exoesqueleto, comodidad del paciente