Clear Sky Science · es
Un marco de aprendizaje profundo de doble flujo para el reconocimiento continuo de lengua de signos para mejorar la accesibilidad comunicativa en la región de Ha’il
Reduciendo la brecha comunicativa
Para muchas personas sordas, la lengua de signos es la principal forma de comunicarse, sin embargo la mayoría de los ordenadores, teléfonos y servicios públicos aún no la entienden. Este artículo presenta un nuevo sistema de inteligencia artificial capaz de observar la firma continua en vídeo y convertirla en texto escrito con mayor precisión. Prestando atención no solo a los movimientos de las manos, sino también a la posición de la cabeza y a las señales faciales, el sistema pretende hacer que la comunicación basada en tecnología sea más natural y accesible, especialmente para las comunidades sordas de la región de Ha’il en Arabia Saudí, donde el apoyo digital todavía es limitado. 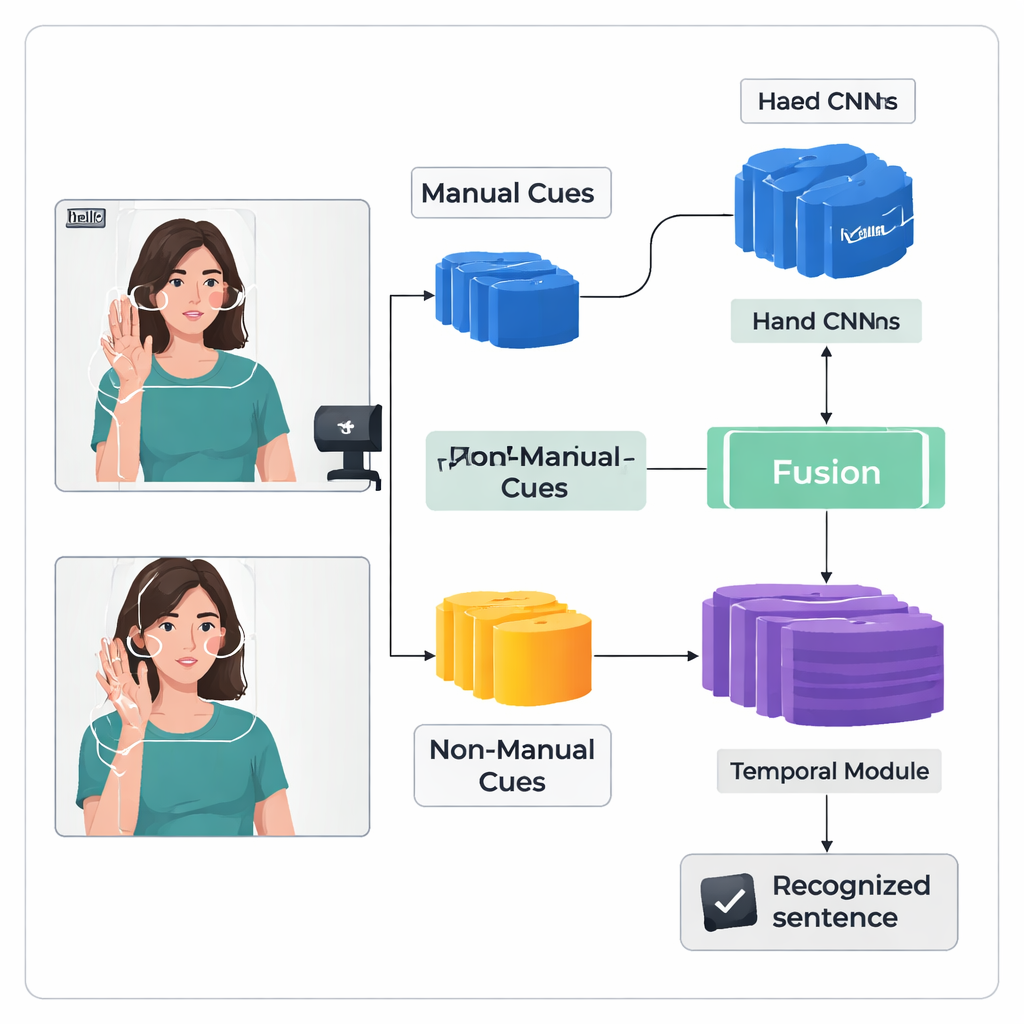
Por qué las manos no bastan
Las lenguas de signos son sistemas ricos y complejos que usan toda la parte superior del cuerpo. El significado no proviene solo de cómo se mueven las manos, sino también de las expresiones faciales, hacia dónde mira la persona que firma y cómo inclina o mueve la cabeza. Estas señales no manuales pueden marcar preguntas, negaciones, énfasis o emoción. Los humanos interpretan todo esto sin esfuerzo, pero la mayoría de los sistemas informáticos para el reconocimiento de lengua de signos se centran casi exclusivamente en las manos. Ese atajo facilita el entrenamiento, pero provoca la pérdida de pistas importantes, sobre todo cuando los signos fluyen juntos en oraciones continuas y rápidas en lugar de aparecer como palabras aisladas.
Dos flujos trabajando en paralelo
Los autores introducen un marco de aprendizaje profundo de “doble flujo” llamado TS-CNN que procesa las manos y la cabeza por separado y luego las fusiona. Un flujo se centra en imágenes recortadas de las manos del firmante, aprendiendo patrones de forma, movimiento y posición. El otro flujo recibe un mapa compacto del rostro y la cabeza, derivado de puntos de referencia y estimaciones de la pose de la cabeza. Ambos flujos usan un tipo estándar de red de visión para convertir cada fotograma de vídeo en características numéricas. El sistema fusiona estas características fotograma a fotograma, respetando que las señales de manos y cabeza ocurren simultáneamente en la firma real. Un módulo temporal posterior analiza muchos fotogramas para entender cómo se desarrollan los signos en el tiempo, y una capa recurrente produce una secuencia de unidades de signo predichas, o glosas.
Agudizando la memoria del sistema sobre los signos
Reconocer la firma continua es difícil porque los datos de entrenamiento son limitados y los signos se confunden sin etiquetas claras fotograma a fotograma. Para abordar esto, los autores añaden un Módulo de Mejora de Características que proporciona orientación adicional durante el entrenamiento. Una técnica ampliamente utilizada alinea la secuencia de glosas predicha con el vídeo, produciendo posiciones probables para cada glosa en el tiempo. El nuevo módulo toma estas sugerencias de alineación y las usa como supervisión directa para refinar la representación interna de las características de las glosas. En términos sencillos, el sistema aprende no solo a producir la secuencia correcta, sino también a construir “memorias” internas más claras y consistentes de cómo es cada signo a través de distintos vídeos.
Probando el enfoque
El equipo evalúa TS-CNN en dos conjuntos de datos de lengua de signos bien conocidos: RWTH-PHOENIX-Weather 2014 para la lengua de signos alemana y CSL Split II para la lengua de signos china. Miden el rendimiento usando la tasa de error por palabra, una métrica estándar similar a la empleada en el reconocimiento de voz. En comparación con una línea base que solo analiza los movimientos de las manos, añadir la información de la pose de la cabeza reduce los errores en aproximadamente 4 puntos porcentuales en los datos alemanes y 3–4 puntos en los datos chinos. La incorporación del módulo de mejora de características aporta ganancias aún mayores, reduciendo los errores en torno al 10–14 por ciento en ambos conjuntos de datos. El sistema también funciona de forma eficiente, alcanzando velocidades en tiempo real en una GPU moderna, lo cual es crucial si se pretende usar en interpretación en vivo o en herramientas móviles. 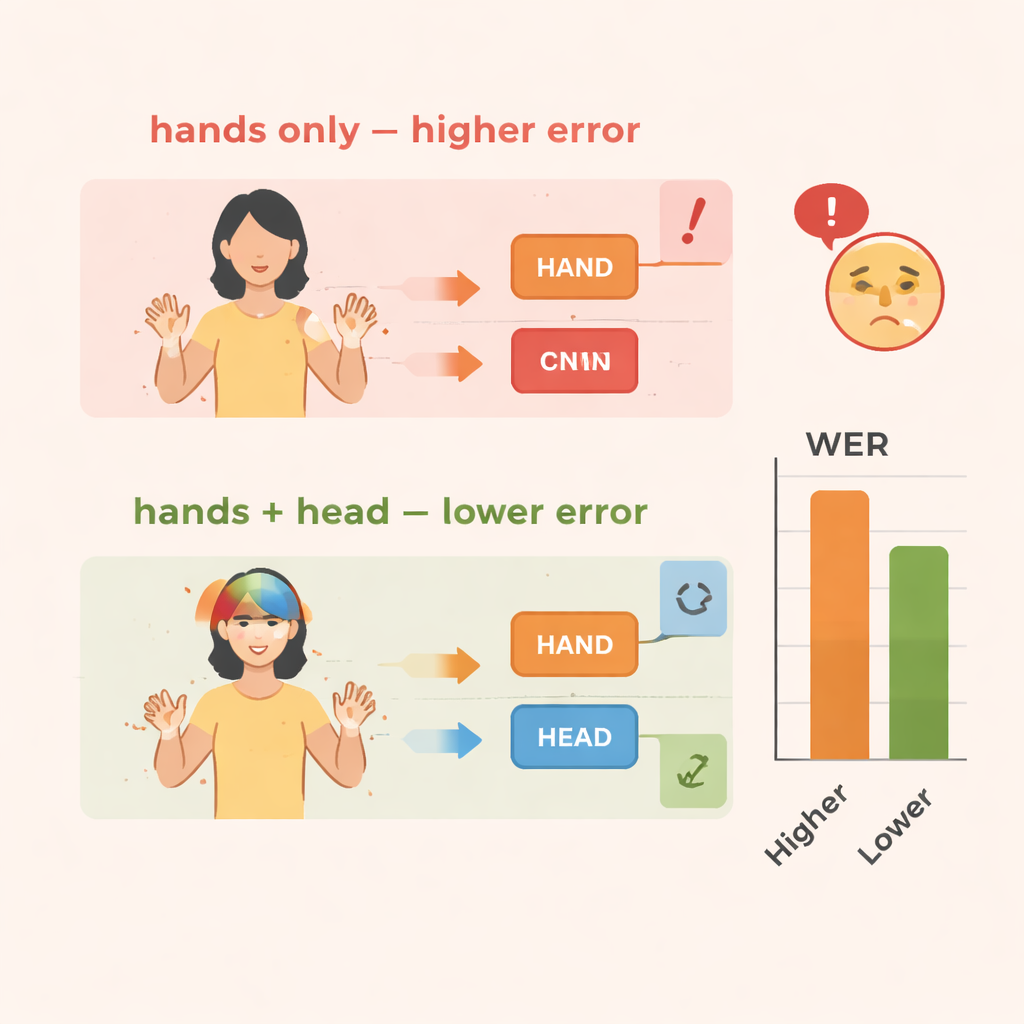
Qué significa esto para la vida cotidiana
En términos cotidianos, esta investigación demuestra que los ordenadores pueden comprender la lengua de signos de forma más fiable cuando observan al firmante en su conjunto, no solo las manos. Al modelar los movimientos de la cabeza y las señales faciales junto con los movimientos manuales, y al refinar cuidadosamente lo que aprende con datos de entrenamiento limitados, el marco TS-CNN se acerca a sistemas prácticos que podrían asistir a personas sordas en aulas, hospitales y oficinas públicas. Para regiones como Ha’il, donde los intérpretes humanos escasean y los proyectos tecnológicos están aún en desarrollo, un sistema como este podría en el futuro respaldar una comunicación más inclusiva —ayudando a cerrar la brecha entre las personas que firman y el mundo oyente sin reemplazar la rica experiencia humana de la propia firma.
Cita: Harrouch, H., Guesmi, H., Alalfy, H. et al. A dual-stream deep learning framework for continuous sign language recognition to enhance communication accessibility in the Ha’il region. Sci Rep 16, 7070 (2026). https://doi.org/10.1038/s41598-026-38912-x
Palabras clave: reconocimiento de lengua de signos, aprendizaje profundo, accesibilidad, visión por computador, interacción persona–ordenador