Clear Sky Science · es
Estimación de la abundancia y la prevalencia de especies mediante métodos no supervisados
Por qué importa contar las especies comunes y las raras
Cuando imaginamos la naturaleza en riesgo, a menudo pensamos en animales raros al borde de la extinción. Sin embargo, la mayor parte del tejido vivo que nos rodea está formada por criaturas muy corrientes que son abundantes o que están desapareciendo silenciosamente antes de que nadie lo note. Poder determinar qué tan extendida está una especie en un lugar concreto es esencial para prever cómo responderán los ecosistemas a la contaminación, al uso del suelo o al cambio climático. Este artículo presenta una forma de estimar cuán comunes o raras son muchas especies a la vez, usando únicamente registros de avistamientos existentes y técnicas modernas de análisis de datos. El objetivo es proporcionar entradas más objetivas para los modelos informáticos que predicen dónde pueden vivir las especies ahora y en el futuro.
De simples avistamientos a grandes preguntas ecológicas
Los ecólogos usan de forma rutinaria modelos computacionales, llamados modelos de nicho ecológico, para determinar qué ambientes son adecuados para una especie. Estos modelos ayudan a prever dónde podría aparecer una especie ante cambios climáticos o en nuevas regiones. Un ingrediente crucial es la “prevalencia”: a grandes rasgos, la proporción de sitios muestreados en los que está presente una especie. Esta medida refleja si se espera que una especie sea común o rara antes de realizar nuevos muestreos. Esa expectativa previa influye fuertemente en cómo los modelos convierten las puntuaciones de idoneidad en probabilidades de presencia y en cómo trazan las fronteras entre “presente” y “ausente” en un mapa. Si la prevalencia se estima mal, sobre todo para especies raras, las predicciones pueden resultar engañosas y los planes de conservación pueden centrarse en lugares equivocados.
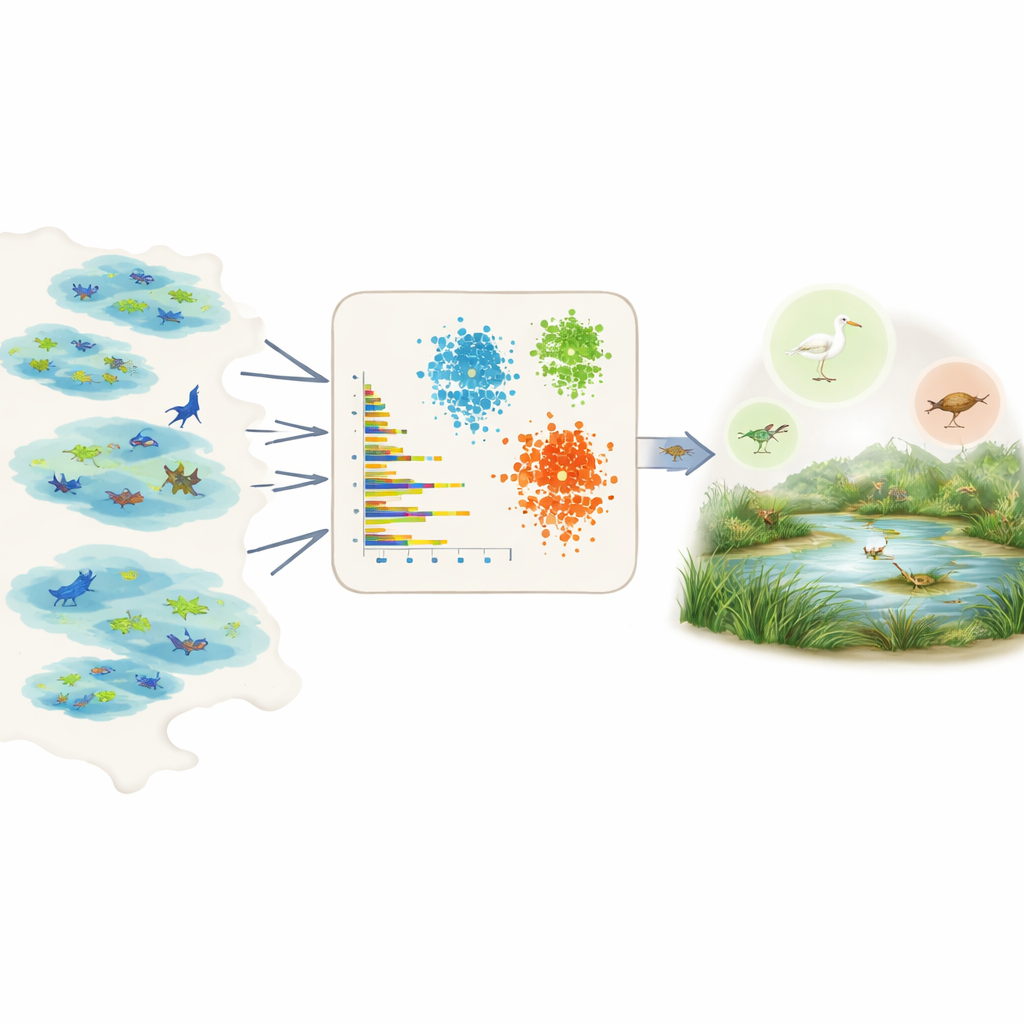
Dejar que los datos hablen por cientos de especies
Medir la prevalencia de forma directa es difícil porque los datos de campo son parciales y sesgados. Algunas áreas se muestrean mucho, algunas especies se ven con más facilidad y muchos registros provienen de proyectos de ciencia ciudadana con esfuerzo desigual. En lugar de basarse en la opinión de expertos o en conocimientos detallados por especie, los autores explotan la Global Biodiversity Information Facility, una enorme base de datos abierta de observaciones de especies. Para cada especie en una región elegida, resumen los registros en unos pocos números simples y comparables: cuántos individuos se informan habitualmente por avistamiento, en cuántos conjuntos de datos o humedales aparece la especie, qué tan extendida está dentro de esos humedales y con qué frecuencia se observa a lo largo del tiempo, incluyendo episodios con muchos registros concentrados.
Enseñar a las máquinas a clasificar especies comunes y raras
Con estas características resumen en mano, el equipo aplica tres herramientas de aprendizaje no supervisado —dos métodos de agrupamiento y un modelo de aprendizaje profundo conocido como autoencoder variacional— que buscan patrones sin recibir previamente la etiqueta de si una especie es común o rara. Los métodos de agrupamiento agrupan especies que comparten similares niveles de abundancia, extensión y frecuencia de observación. El autoencoder aprende cómo es un registro “típico” de especie y detecta patrones inusuales como anomalías, que a menudo corresponden a especies raras o poco observadas. Los modelos asignan entonces a cada especie tres clases intuitivas —muy común, bastante común o rara— y convierten esas clases en valores numéricos de prevalencia que pueden integrarse directamente en los modelos de nicho ecológico como probabilidades a priori.
Probar el enfoque en un humedal vulnerable
Para evaluar cómo funciona este marco en la práctica, los autores se centran en la cuenca del lago Massaciuccoli en la Toscana, Italia, un humedal de baja altitud rico en aves, peces, insectos y otros animales. Este paisaje es a la vez un punto caliente de biodiversidad y un imán turístico, pero también es vulnerable al cambio climático, a la escasez de agua y a la contaminación. Para 161 especies animales vinculadas al lago, los modelos se entrenaron usando registros de otros humedales italianos y luego se pidió que inferieran cuán comunes deberían ser en Massaciuccoli. Dos expertos locales, con amplia experiencia de campo en la zona, valoraron de forma independiente las mismas especies. Al comparar ambos enfoques, el modelo de aprendizaje profundo coincidió con la visión conjunta de los expertos en aproximadamente el 81–90 % de las especies, mientras que los métodos de agrupamiento y un ensamblado de los tres también mostraron buen rendimiento.
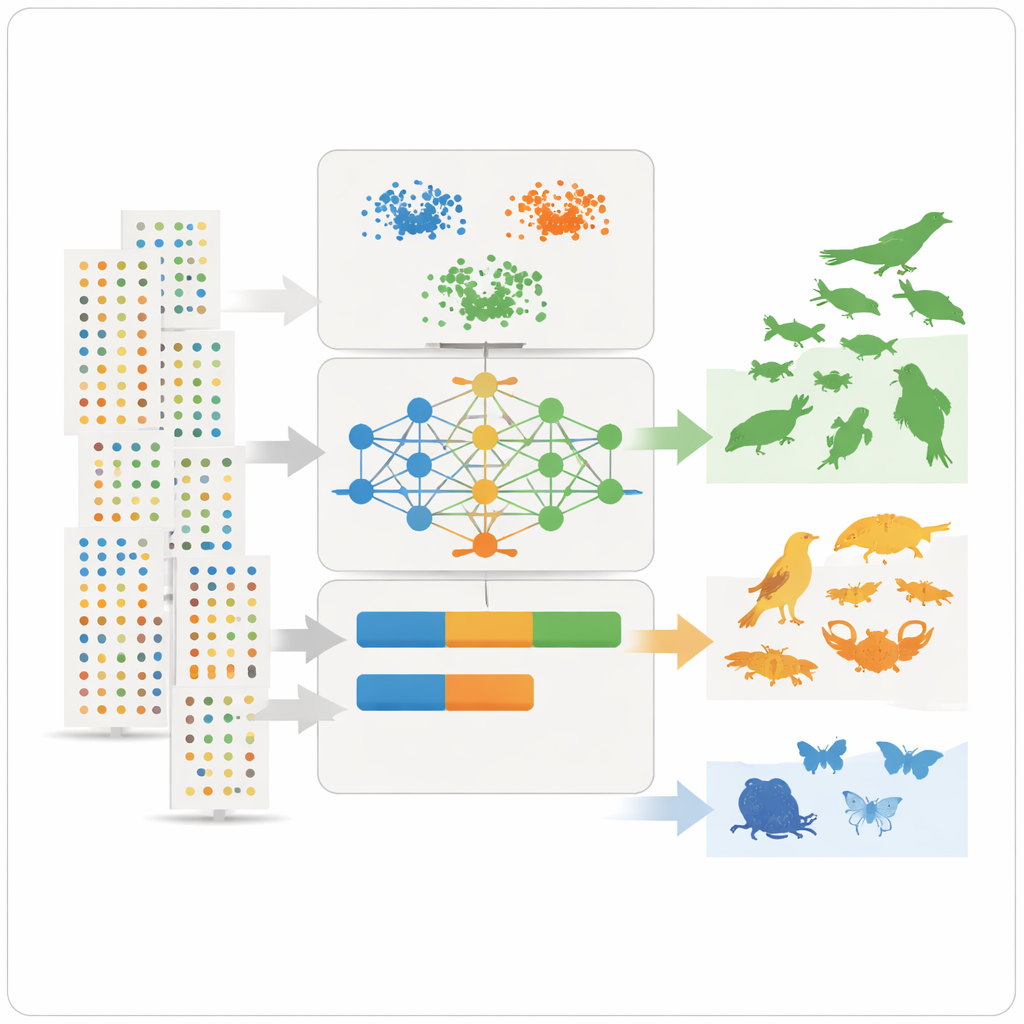
Aprender de los desacuerdos y de los sesgos ocultos
No todos los casos coincidieron perfectamente. Algunas especies bien conocidas por los expertos como abundantes en torno al lago aparecían como raras en los datos, a menudo porque son esquivas, están infraregistradas o reciben más atención en ciertos humedales que en otros. Esto puso de manifiesto una limitación clave: las grandes bases de datos reflejan dónde y cómo la gente busca la naturaleza, no sólo dónde ocurren realmente las especies. Un análisis de sensibilidad mostró qué características fueron más importantes para las clasificaciones, destacando el número medio de registros por conjunto de datos, la abundancia por avistamiento y la consistencia de las observaciones a lo largo de los años como especialmente informativas. A pesar de los sesgos persistentes, el método produjo estimaciones de prevalencia claras y reproducibles y puede ajustarse para usar clases más finas o más generales según las necesidades del modelado.
Qué significa esto para las previsiones futuras de la naturaleza
Para el público general, el mensaje principal es que ahora podemos usar los datos de biodiversidad existentes de forma más inteligente para evaluar qué especies probablemente serán comunes, intermedias o raras en un determinado entorno, sin tener que ajustar cada caso manualmente. Al transformar registros de observación ruidosos en estimaciones de prevalencia transparentes y basadas en datos, el marco ayuda a que los modelos ecológicos realicen predicciones de idoneidad de hábitat y de tendencias futuras de biodiversidad más realistas. Eso, a su vez, puede apoyar una mejor planificación para humedales como Massaciuccoli y muchos otros ecosistemas en todo el mundo, incluso cuando los datos de campo son incompletos y el tiempo de los expertos es limitado.
Cita: Bove, P., Bertini, A. & Coro, G. Estimating species commonness and prevalence through unsupervised methods. Sci Rep 16, 8331 (2026). https://doi.org/10.1038/s41598-026-38900-1
Palabras clave: prevalencia de especies, modelización de la biodiversidad, ecosistemas de humedales, ecología y aprendizaje automático, abundancia de especies