Clear Sky Science · es
Clasificación de texto de letras basada en redes profundas adaptativas híbridas en cascada serial mediante un enfoque de optimización
Por qué importan filtros de canciones más inteligentes
La música entra en nuestras vidas casi sin pausa, y gran parte de lo que escuchamos lo eligen algoritmos. Sin embargo, muchos de estos sistemas siguen teniendo dificultades con una pregunta sencilla: ¿qué dicen exactamente las palabras de una canción y para quién son apropiadas? Este artículo aborda ese problema construyendo un modelo avanzado de inteligencia artificial (IA) que lee automáticamente las letras y las clasifica por estado de ánimo, género, sentimiento e incluso tipo de intérprete. El objetivo es ayudar a crear listas de reproducción más seguras para niños, recomendaciones basadas en el estado de ánimo más precisas y mejores herramientas para investigadores musicales.
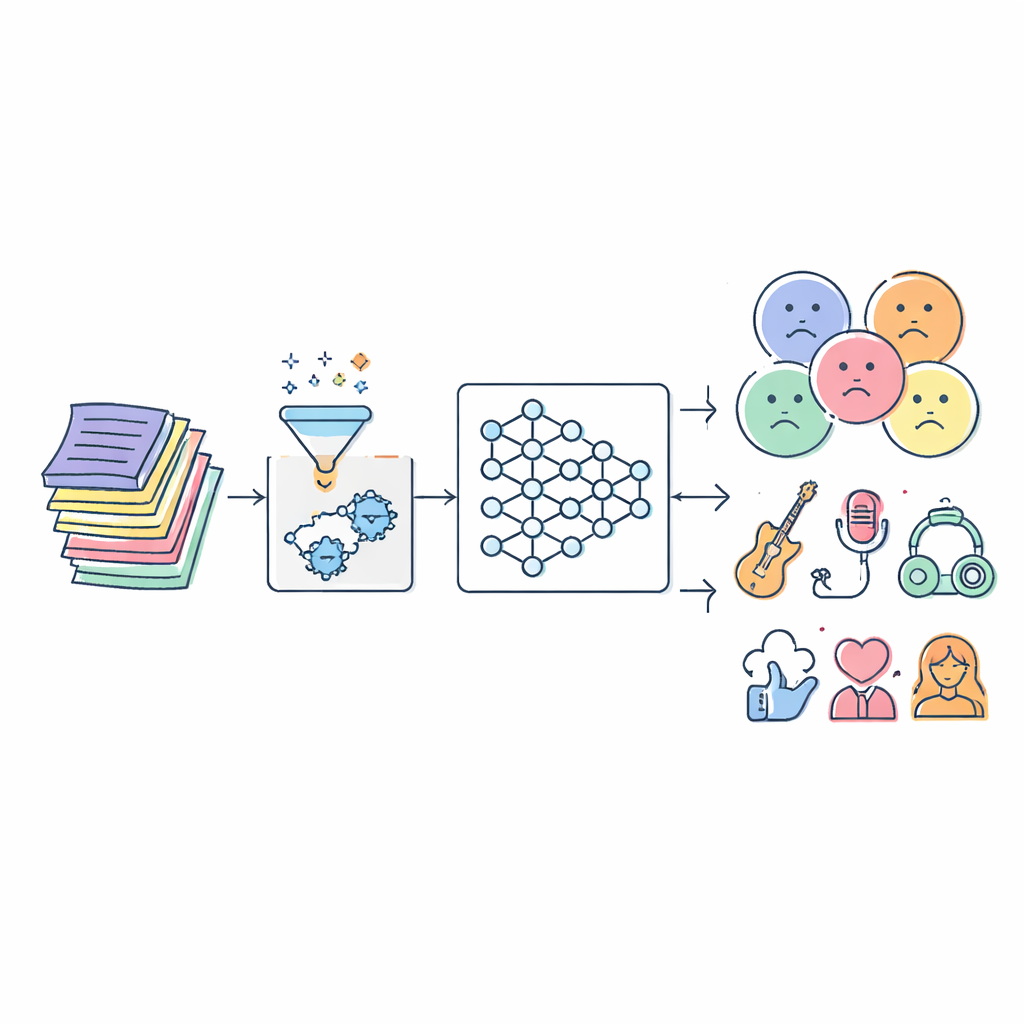
El reto oculto en las palabras de las canciones
Las letras son mucho más complicadas que una lista de palabras buenas o malas. La misma frase puede resultar tierna en una canción y amenazante en otra, y los oyentes aportan sus propias experiencias a lo que escuchan. Los filtros tradicionales suelen basarse en listas estáticas de términos ofensivos o en técnicas estadísticas sencillas. Estos enfoques pierden el contexto, no siguen el ritmo de la jerga cambiante y con frecuencia etiquetan mal las canciones. Al mismo tiempo, la explosión de la música digital significa que hay millones de pistas que analizar, en muchos idiomas y estilos, lo que desborda el etiquetado manual y los algoritmos más antiguos.
Limpiar las letras en bruto
Los autores comienzan reuniendo grandes colecciones de letras a partir de tres conjuntos de datos públicos que, en conjunto, cubren cientos de miles de canciones en múltiples géneros e idiomas. Antes de que cualquier IA pueda aprender del texto, las letras deben limpiarse. El sistema elimina puntuación, símbolos especiales y fragmentos repetidos o irrelevantes, y luego reduce formas de palabras relacionadas a una raíz común (por ejemplo, «singing», «sings» y «sang» pasan a «sing»). Este paso de preprocesado elimina el ruido manteniendo el significado, de modo que las etapas posteriores puedan centrarse en el tono emocional y el tema más que en peculiaridades de formato o variaciones ortográficas.
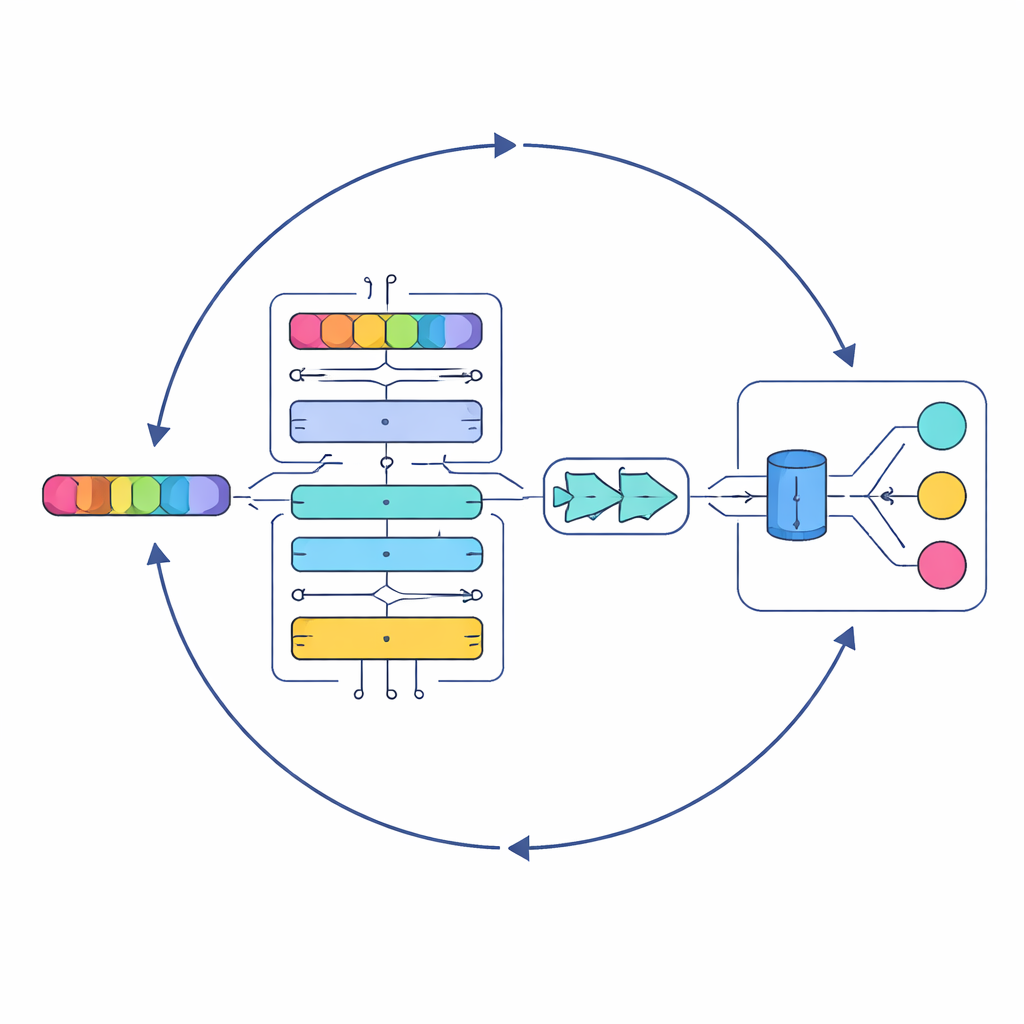
Una IA por capas que lee como un oyente atento
En el núcleo del estudio está un nuevo modelo llamado Serial Cascaded Hybrid Adaptive Deep Network, o SCHADNet. Combina tres ideas poderosas de la IA moderna para lenguaje. Primero, un codificador basado en transformadores captura cómo se relacionan las palabras en toda una letra, no solo entre vecinas inmediatas. Segundo, una capa bidireccional de Long Short-Term Memory lee la letra hacia adelante y hacia atrás en el tiempo, ayudando al sistema a entender cómo las líneas anteriores matizan el significado de las posteriores. Tercero, una capa Gated Recurrent Unit refina esa información en un resumen compacto adecuado para tomar decisiones finales. En conjunto, estos componentes actúan como un coro de lectores especializados, cada uno centrado en diferentes aspectos del texto de la canción.
Tomando prestada una estrategia del mar
Apilar capas de aprendizaje profundo no es suficiente; sus ajustes internos —como cuántas neuronas contienen y cuánto tiempo entrenan— afectan mucho al rendimiento. En lugar de afinar estas elecciones manualmente, los autores recurren a un enfoque de optimización inspirado en los patrones de caza de los depredadores marinos. Su Improved Marine Predators Algorithm (IMPA) explora muchas combinaciones de parámetros posibles, aproximándose de forma constante a las que ofrecen mejores resultados. Al recortar partes del algoritmo original que no ayudaban en este contexto, mejoran la convergencia, lo que significa que el sistema alcanza buenas soluciones más rápido y de forma más fiable.
Qué tan bien funciona el sistema
Los investigadores prueban SCHADNet con IMPA en tres conjuntos de datos de letras diferentes y lo comparan con una variedad de métodos establecidos, incluidos clasificadores clásicos de aprendizaje automático y varios modelos populares de aprendizaje profundo como LSTM simple, sistemas solo con transformadores y redes híbridas. En medidas como precisión, recall (cuántas canciones verdaderamente relevantes se encuentran) y otras métricas de calidad, el nuevo enfoque sale consistentemente por delante. En un gran conjunto de datos multilingüe, clasifica correctamente alrededor del 93% de las canciones y alcanza un valor predictivo negativo especialmente alto, lo que significa que es muy bueno reconociendo letras que no pertenecen a una categoría marcada —crucial para evitar bloqueos o etiquetas excesivas.
Qué significa esto para oyentes y creadores
Para un público no especializado, el mensaje es claro: los autores han construido un lector de letras más matizado y fiable. En lugar de depender de listas burdas de palabras, su sistema observa frases completas, contexto y patrones a través de grandes colecciones de música, y asigna automáticamente etiquetas como estado de ánimo, estilo o idoneidad para audiencias jóvenes. Aunque el modelo es complejo y exige muchos recursos computacionales, abre la puerta a controles parentales más inteligentes, listas de reproducción por estado de ánimo más ricas y nuevas formas de estudiar tendencias en la música popular. Trabajos futuros buscan reducir su apetito por los datos y acelerar el entrenamiento, pero incluso en su forma actual, SCHADNet apunta hacia un futuro en el que las plataformas musicales entiendan las letras casi con la misma atención que un oyente humano atento.
Cita: Jasmine, R.L., Mukherjee, S., Robin, C.R.R. et al. Serial cascaded hybrid adaptive deep networks-based lyrics text classification using optimization approach. Sci Rep 16, 8527 (2026). https://doi.org/10.1038/s41598-026-38813-z
Palabras clave: recomendación musical, análisis de letras, clasificación de texto, aprendizaje profundo, moderación de contenido