Clear Sky Science · es
Mejora de la detección de fraude por suscripción mediante aprendizaje en ensamblaje: el caso de Ethio Telecom
Por qué el fraude telefónico importa a todos
Cada vez que llamamos, enviamos un mensaje o usamos datos móviles, confiamos en que la factura refleje lo que realmente consumimos. Pero los delincuentes pueden explotar las redes telefónicas abriendo líneas con identidades falsas, acumulando cargos impagados enormes e incluso empleando esas líneas para otros delitos. Este estudio se centra en Ethio Telecom, el operador nacional de Etiopía, y muestra cómo métodos avanzados basados en datos pueden detectar suscripciones sospechosas con mucha mayor precisión que las herramientas tradicionales, ayudando a mantener los servicios telefónicos asequibles y seguros para millones de usuarios.
El coste oculto de las cuentas telefónicas falsas
El fraude por suscripción ocurre cuando alguien contrata un servicio telefónico con datos falsos o robados y no tiene intención de pagar. A nivel mundial, es una de las formas más dañinas de fraude en telecomunicaciones, con pérdidas de decenas de miles de millones de dólares cada año. Solo en Ethio Telecom, se estima que el fraude drena alrededor de mil millones de dólares anuales, con las suscripciones fraudulentas responsables de aproximadamente el 40% de esa pérdida. Más allá de los ingresos perdidos, esas líneas pueden usarse para estafas, reventa de llamadas internacionales u otras actividades ilícitas, lo que representa riesgos tanto para los clientes como para la seguridad nacional.
De reglas hechas a mano al aprendizaje desde los datos
Como muchos operadores, Ethio Telecom confiaba tradicionalmente en expertos que elaboraban reglas fijas para marcar comportamientos sospechosos—por ejemplo, bloquear una línea tras demasiadas llamadas internacionales en poco tiempo. Estos sistemas basados en reglas son fáciles de entender pero fallan cuando los defraudadores cambian de tácticas o cuando los patrones de uso son complejos. Los autores sostienen que el aprendizaje automático, que aprende patrones directamente de datos históricos, puede responder más rápido y con mayor sensibilidad. En lugar de depender de un único modelo, exploran métodos de “ensamblaje” que combinan varios modelos, y métodos “adaptativos” que se actualizan continuamente a medida que llega nueva información.
Qué construyeron los investigadores a partir de registros reales de llamadas
El equipo trabajó con un gran conjunto de registros de detalle de llamadas—logs de quién llamó a quién, durante cuánto tiempo y en qué condiciones—procedentes de un periodo de dos meses conocido por intensa actividad fraudulenta. Partiendo de cerca de un millón de registros en bruto, limpiaron los datos, eliminaron errores y duplicados, equilibraron las clases fuertemente sesgadas (muchos más usuarios honestos que defraudadores) y diseñaron nuevas características que capturan mejor los comportamientos sospechosos. Fueron especialmente relevantes medidas como cuántos números internacionales marcó un suscriptor, la proporción de llamadas que eran internacionales y la relación entre números únicos marcados y el total de llamadas. Estas señales destiladas suelen distinguir el uso normal del abuso organizado mucho mejor que simples conteos o datos demográficos.
Cómo potenciar la detección combinando modelos
Los investigadores probaron tres modelos estándar—árboles de decisión, regresión logística y redes neuronales artificiales—junto con varias estrategias de ensamblaje como bagging (Random Forest), boosting (XGBoost), votación y apilamiento (stacking), además de modelos adaptativos diseñados para flujos de datos continuos (Hoeffding Tree y Adaptive Random Forest). Tras un ajuste cuidadoso de los parámetros de cada modelo, el enfoque de stacking, que aprende a combinar las fortalezas de varios modelos base, alcanzó alrededor del 99,3% de precisión en datos no vistos. El Adaptive Random Forest fue casi tan bueno, con aproximadamente 99,2% de precisión, y además puede ajustarse conforme cambian los patrones de fraude con el tiempo. Ambos enfoques redujeron drásticamente el error más peligroso—no detectar fraudes reales—en comparación con los modelos individuales.
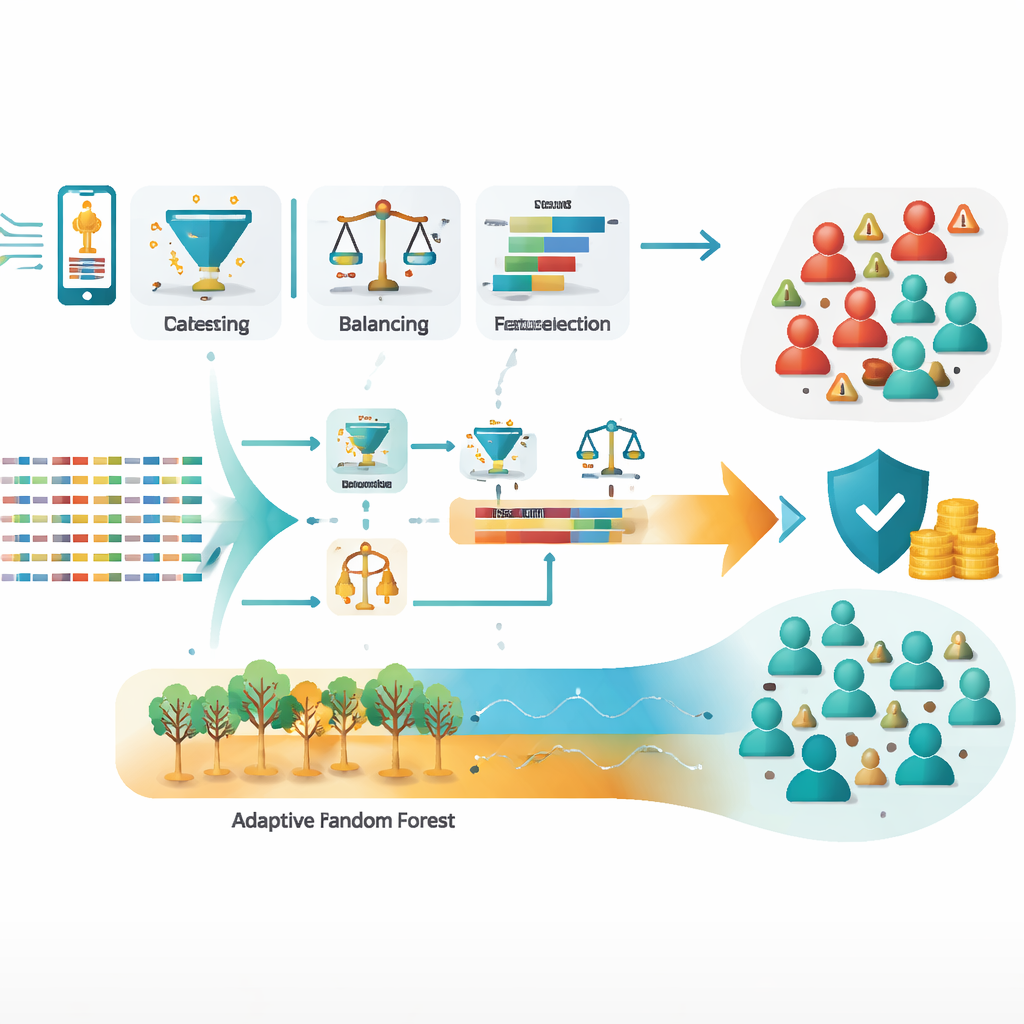
Ponerse al día con las artimañas cambiantes en tiempo real
Puesto que los defraudadores cambian constantemente sus métodos, un modelo estático puede quedar obsoleto rápidamente. Para afrontarlo, los autores usaron una técnica de selección de características en línea que reevalúa continuamente qué señales importan más, sin tener que reconstruir el sistema desde cero. También subrayan la importancia de la privacidad: todos los identificadores personales en los datos fueron anonimizados antes del análisis, y recomiendan controles de acceso estrictos y registros de auditoría. Para el despliegue práctico, el estudio describe una arquitectura en tiempo real en la que nuevos registros de llamadas fluyen a través de herramientas como Apache Kafka hacia modelos adaptativos que se actualizan al instante mientras monitorizan cambios bruscos en el comportamiento.
Qué significa esto para usuarios y proveedores telefónicos
En términos sencillos, el estudio muestra que permitir que varios modelos inteligentes “voten” en conjunto y que aprendan de forma continua puede detectar suscripciones falsas con una precisión notable, manteniendo las falsas alarmas en niveles manejables. Para Ethio Telecom, esto podría traducirse en ahorros sustanciales, precios más estables y mayor protección contra el uso delictivo de la red. Para los clientes significa que usos inusuales pero legítimos son menos propensos a ser interpretados como fraude, mientras que las líneas realmente riesgosas se detectan y cierran más rápido. Los autores concluyen que el aprendizaje en ensamblaje y adaptativo, basado en indicadores bien escogidos y específicos del contexto, ofrece un plan potente y escalable para la detección moderna de fraudes en telecomunicaciones.
Cita: Desta, E.A., Azale, K.W., Hailu, A.A. et al. Enhancing subscription fraud detection through ensemble learning the case of Ethio telecom. Sci Rep 16, 7867 (2026). https://doi.org/10.1038/s41598-026-38790-3
Palabras clave: fraude en telecomunicaciones, fraude por suscripción, aprendizaje en ensamblaje, bosque aleatorio adaptativo, registros de detalle de llamadas