Clear Sky Science · es
Predicción precisa e interpretable de la demanda química de oxígeno usando algoritmos de boosting explicables con análisis SHAP
Por qué importa vigilar el oxígeno de un río
Los ríos son el sustento de ciudades y campos, pero cuando se llenan de materia orgánica procedente de fábricas, alcantarillas o tierras de cultivo, el agua puede quedarse sin oxígeno y volverse insegura para las personas y los ecosistemas. Una comprobación habitual de la salud de un río es la “demanda química de oxígeno” (DQO), una medida de cuánto oxígeno se necesita para descomponer la contaminación. Medir la DQO en el laboratorio es lento y costoso, por lo que este estudio explora si herramientas avanzadas pero explicables de aprendizaje automático pueden predecir de forma fiable la DQO a partir de datos rutinarios de sensores, y además mostrar con claridad qué está impulsando la contaminación. 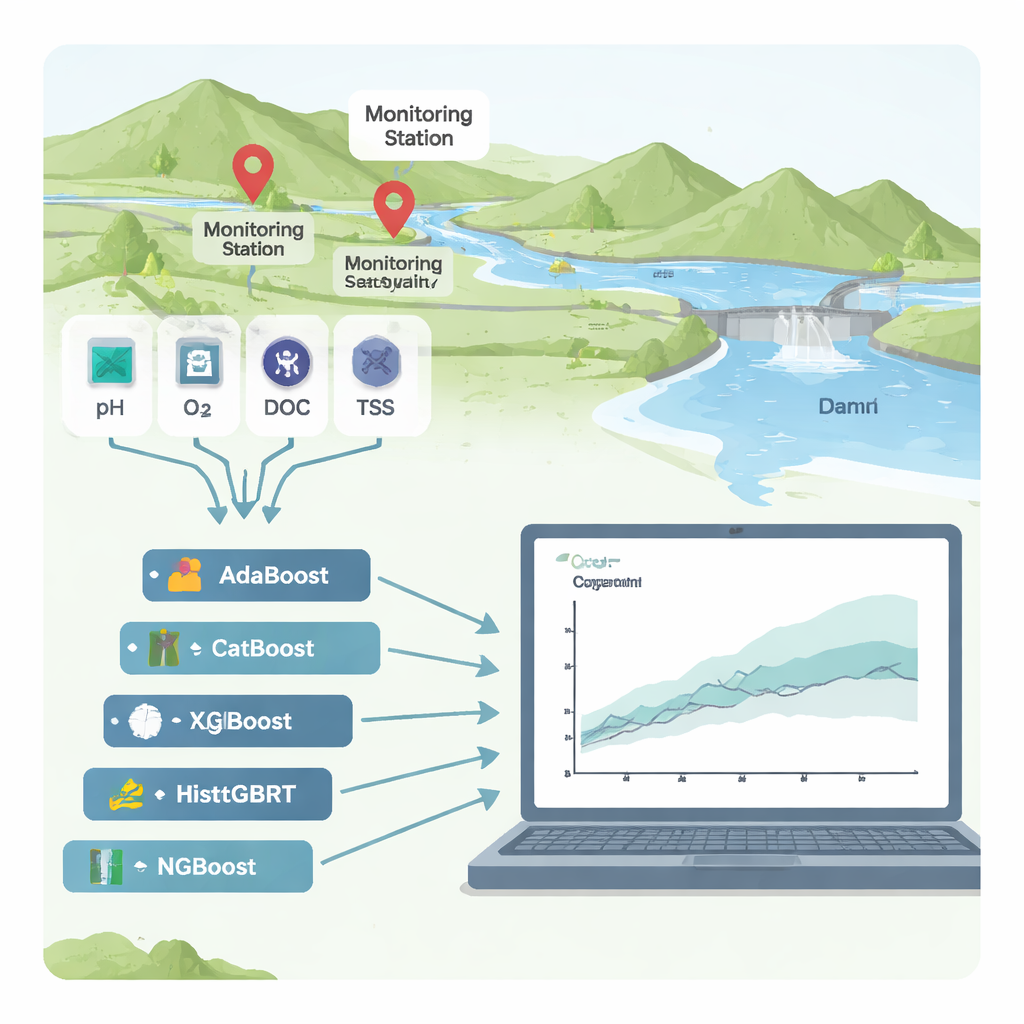
Modelos inteligentes para un mundo contaminado
Los investigadores se centraron en dos estaciones de monitorización fluvial en Corea del Sur, Hwangji y Toilchun, justo aguas arriba de la presa multipropósito Yeongju. En estas estaciones existen décadas de registros de indicadores comunes de calidad del agua: acidez (pH), oxígeno disuelto, sólidos en suspensión (partículas finas en el agua), nutrientes como nitrógeno y fósforo, carbono orgánico total (COT), demanda bioquímica de oxígeno (DBO₅), temperatura del agua, conductividad eléctrica y caudal del río. En lugar de construir un modelo tradicional basado en física —que puede ser difícil de transferir de un río a otro— evaluaron seis algoritmos de “boosting”, una potente familia de métodos de aprendizaje automático que combinan muchos árboles de decisión simples en un predictor sólido.
Encontrando al mejor “pronosticador” del río
Para comparar los seis métodos de boosting (AdaBoost, CatBoost, XGBoost, LightGBM, HistGBRT y NGBoost), el equipo entrenó los modelos con aproximadamente el 70% de los datos históricos y evaluó el rendimiento en el 30% restante. Juzgaron la precisión con varias estadísticas que capturan cuán cercanas están las predicciones a las mediciones reales de DQO y qué tan bien generalizan los modelos a condiciones no vistas. En la estación Toilchun, el modelo NGBoost —que predice no solo un único valor sino una distribución probabilística completa para la DQO— fue el claro ganador, capturando casi toda la variación de la DQO con errores muy pequeños. En Hwangji, que es un sitio más complejo, CatBoost ofreció el mejor equilibrio entre precisión y estabilidad. Algunos modelos, especialmente XGBoost, parecían casi perfectos en los datos de entrenamiento pero fallaban en los datos de prueba, un signo clásico de "sobreajuste", en el que un modelo memoriza ruido en lugar de aprender patrones reales.
Abriendo la caja negra de la IA
Un objetivo central del estudio no fue solo predecir la DQO, sino también explicar por qué los modelos hicieron sus predicciones. Para ello, los autores utilizaron SHAP (Shapley Additive Explanations), una técnica que asigna a cada variable de entrada una contribución —positiva o negativa— a cada predicción individual. En ambos ríos y en la mayoría de los algoritmos, tres variables surgieron consistentemente como los principales determinantes de la DQO: carbono orgánico total (COT), demanda bioquímica de oxígeno (DBO₅) y sólidos en suspensión (SS). En términos simples, cuanto más material orgánico y más partículas finas haya en el agua, mayor será la demanda de oxígeno. Los modelos también revelaron diferencias específicas por sitio: en Toilchun, el caudal y el fósforo total jugaron un papel más importante, lo que sugiere una mayor influencia de fuentes difusas como escorrentía agrícola; en Hwangji, los patrones en la conductividad y los sólidos en suspensión apuntaron a fuentes más localizadas o industriales. 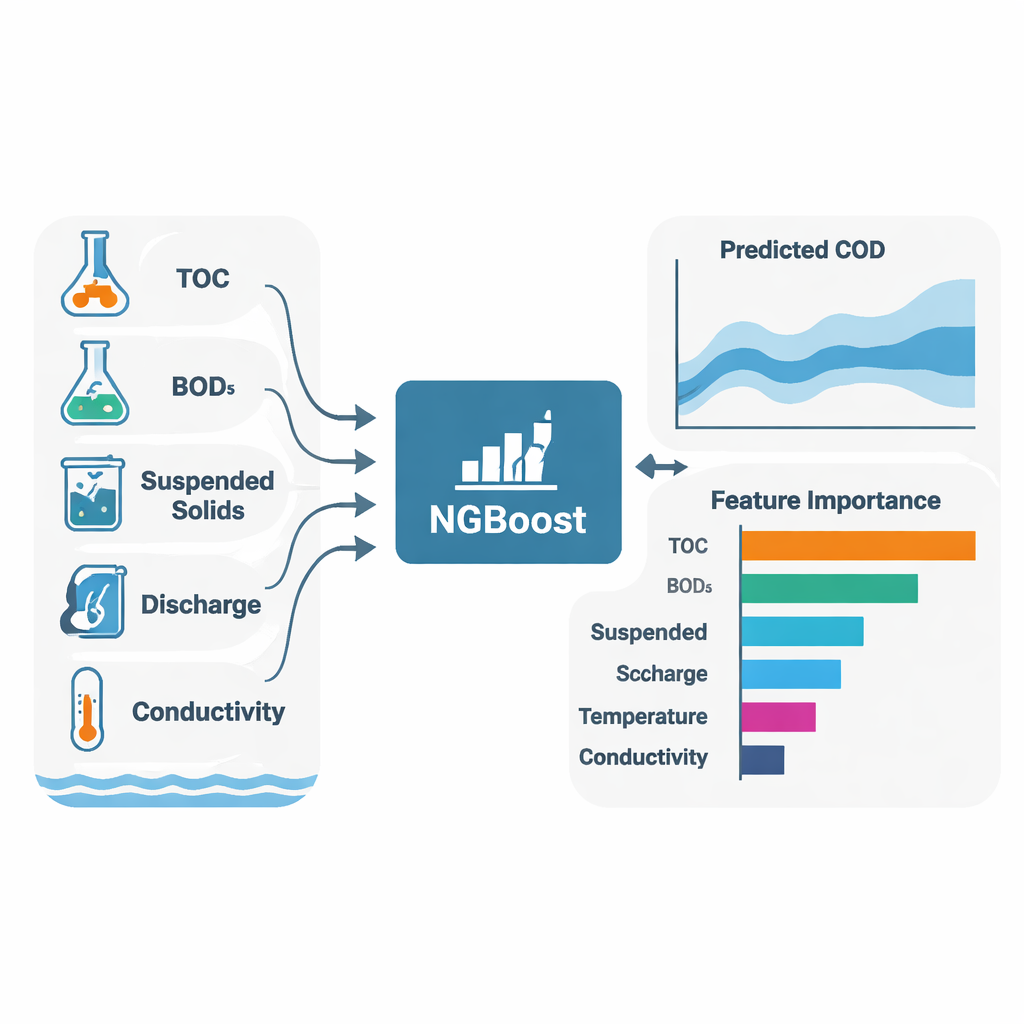
Qué significan los resultados para ríos reales
Estas conclusiones muestran que los modelos de boosting, cuando se combinan con SHAP, pueden ir más allá de ser opacas “cajas negras”. Proporcionan tanto pronósticos precisos de la demanda de oxígeno del río como una explicación físicamente coherente de qué impulsa la contaminación en cada sitio. Esto importa para los gestores de presas y cuencas fluviales que deben priorizar qué vigilar y dónde intervenir: si el COT y la DBO₅ son las palancas más fuertes, controlar las entradas de residuos orgánicos puede ofrecer la mayor mejora en la calidad del agua. Los pronósticos probabilísticos de NGBoost también aportan una idea de la incertidumbre, crucial para sistemas de alerta temprana y decisiones basadas en riesgos. En resumen, el estudio demuestra que una IA explicable y bien diseñada puede ayudar a proteger los embalses de agua potable y la vida acuática al convertir lecturas rutinarias de sensores en predicciones fiables y transparentes de la salud de los ríos.
Cita: Merabet, K., Kim, S., Heddam, S. et al. Accurate and interpretable prediction of chemical oxygen demand using explainable boosting algorithms with SHAP analysis. Sci Rep 16, 6359 (2026). https://doi.org/10.1038/s41598-026-38757-4
Palabras clave: calidad del agua, demanda química de oxígeno, aprendizaje automático, contaminación de ríos, IA explicable