Clear Sky Science · es
Reconocimiento de expresiones faciales mediante inferencia variacional
Leer los sentimientos en los rostros
Nuestros rostros transmiten constantemente cómo nos sentimos, pero esas señales rara vez son simples. Una sonrisa puede ocultar nerviosismo, y una mirada “neutral” puede mezclar aburrimiento con irritación. Este estudio presenta POSTER-Var, un nuevo sistema de inteligencia artificial (IA) que pretende leer emociones sutiles y mixtas con mayor precisión que las herramientas actuales de reconocimiento facial, lo que podría mejorar desde la interacción humano–computadora hasta el seguimiento de la salud mental.
Por qué las emociones no son solo encendidas o apagadas
La mayoría de los sistemas actuales de reconocimiento de expresiones faciales tratan las emociones como casillas limpias y separadas: feliz, triste, enfadado, etc. En la práctica, la psicología muestra que las expresiones son mezclas de emociones básicas, con distintas intensidades apareciendo a la vez en un mismo rostro. Los modelos tradicionales de IA suelen forzar cada imagen en una etiqueta única y rígida, ignorando la incertidumbre y la naturaleza continua y graduada de los sentimientos. Esto los hace frágiles en entornos del mundo real, donde la iluminación, la pose e incluso etiquetas humanas inconsistentes añaden ruido. Los autores sostienen que los sistemas futuros deben reconocer que un rostro puede insinuar varias emociones con distintas intensidades y que los ordenadores deberían razonar en términos de probabilidades en lugar de decisiones de sí o no.
Permitir que el modelo acepte la incertidumbre
Para ajustarse mejor a esta realidad desordenada, el equipo se basa en una técnica del modelado probabilístico moderno llamada inferencia variacional. En lugar de producir un único valor fijo para cada emoción, su sistema POSTER-Var mapea rasgos faciales a un “espacio latente” donde cada emoción está representada por una distribución de probabilidad, típicamente con forma de campana. Durante el entrenamiento, el sistema extrae muestras de estas distribuciones aprendidas, incentivándolo a explorar una gama de posibles interpretaciones de cada rostro. En tiempo de prueba, sin embargo, emplea simplemente los centros de esas distribuciones para emitir predicciones estables. De forma crucial, POSTER-Var elimina la decodificación adicional y las capas totalmente conectadas usadas en diseños variacionales anteriores, tratando la representación probabilística en sí como la señal de decisión final. Esta cabeza de clasificación basada en inferencia variacional, o VICH, permite al modelo cuantificar la incertidumbre manteniéndose eficiente y preciso.
Ver el rostro a múltiples escalas
Reconocer expresiones también requiere observar distintas partes del rostro y distintos niveles de detalle: la curva de la boca, la forma de los ojos y la configuración general importan. POSTER-Var amplía un sistema previo potente (POSTER++) mejorando cómo se combinan estas características multiescala. Utiliza varios mecanismos de atención para fusionar información de una columna vertebral de imagen estándar y de un detector de puntos faciales, que rastrea puntos clave como las comisuras de los ojos y los bordes de la boca. Un “embebido de capa” marca cada mapa de características con su posición y nivel semántico en la pirámide de procesamiento, ayudando a la red a entender de dónde provienen los detalles. Transformaciones no lineales y un bloque de atención por canal mejorado vuelven a equilibrar estas características, potenciando las más informativas para las expresiones y suprimiendo distracciones como el desorden del fondo o peculiaridades específicas de la identidad.
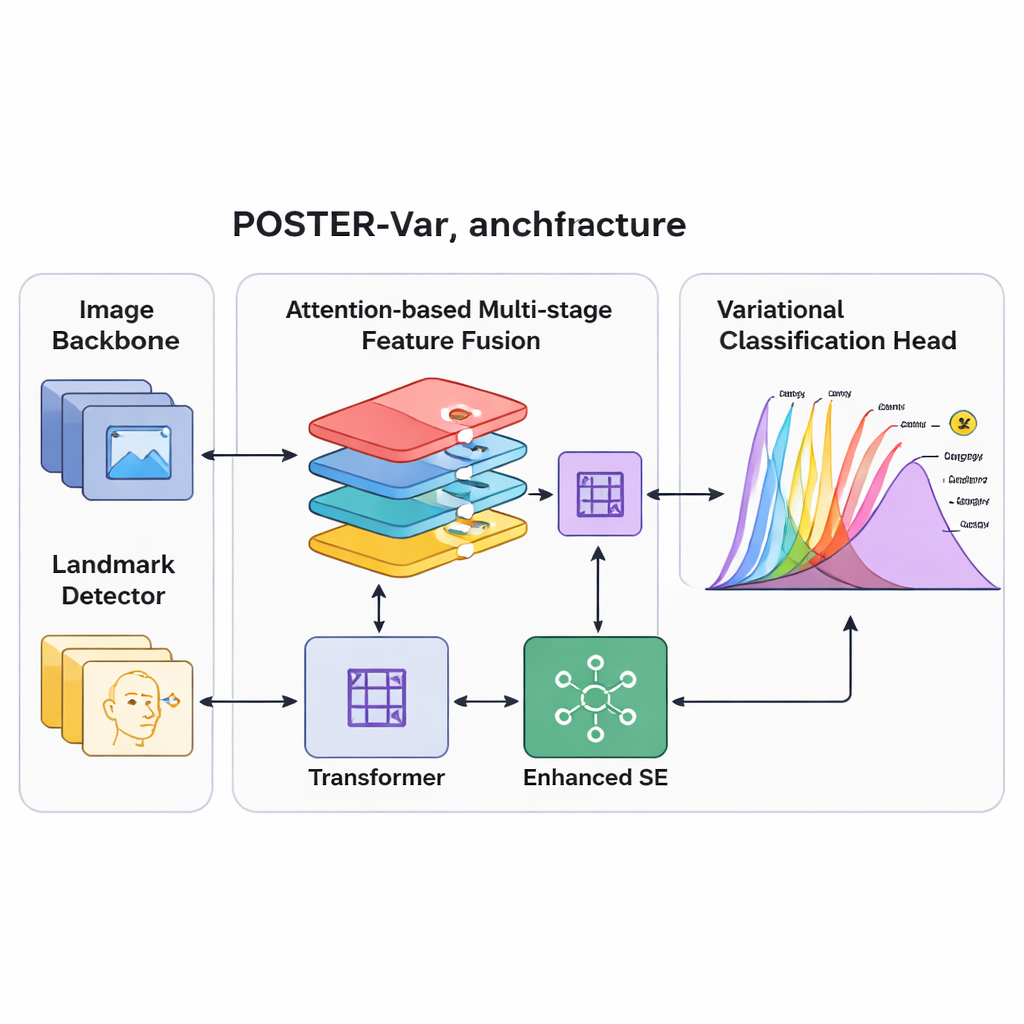
Poner el sistema a prueba
Los investigadores evaluaron POSTER-Var en tres conjuntos de datos del mundo real ampliamente usados: RAF-DB, AffectNet y FER+. Estas colecciones incluyen cientos de miles de rostros capturados en condiciones no controladas, cada uno etiquetado con una de varias emociones básicas. En todos los benchmarks, POSTER-Var igualó o superó a los métodos de última generación. Por ejemplo, alcanzó alrededor del 93 % de precisión en RAF-DB y aproximadamente el 92 % en FER+, y mejoró ligeramente los resultados en versiones de 7 y 8 clases de AffectNet. Experimentos de ablación, en los que se eliminaron componentes individuales, mostraron que tanto el embebido de capa como la cabeza variacional contribuyeron de forma notable al rendimiento, siendo el componente variacional especialmente útil en conjuntos de datos más difíciles y desequilibrados. Visualizaciones de los mapas de atención revelaron que POSTER-Var se centra en regiones faciales más amplias y con mayor significado que la línea base, y los gráficos de sus distribuciones de emoción aprendidas ilustraron cómo separa mejor, por ejemplo, “triste” de “neutral” en casos ambiguos.
Qué significa esto para aplicaciones del mundo real
En términos sencillos, POSTER-Var enseña a las máquinas a tratar las expresiones faciales menos como semáforos y más como previsiones meteorológicas: puede haber un estado principal “soleado” con indicios dispersos de “nublado”, y el pronóstico debe reconocer la incertidumbre. Al modelar distribuciones completas sobre las emociones en lugar de una única conjetura, el sistema se vuelve más resistente a etiquetas ruidosas y a expresiones sutiles y mezcladas. El estudio sugiere que enfoques probabilísticos de este tipo podrían sustentar la próxima generación de tecnologías conscientes del afecto, haciendo que asistentes virtuales, robots sociales y herramientas de investigación del comportamiento capten mejor la compleja vida emocional que nuestros rostros solo revelan de forma imperfecta.
Cita: Lv, G., Zhang, J. & Tsoi, C. Facial expression recognition via variational inference. Sci Rep 16, 7323 (2026). https://doi.org/10.1038/s41598-026-38734-x
Palabras clave: reconocimiento de expresiones faciales, IA emocional, modelado probabilístico, inferencia variacional, visión por computador