Clear Sky Science · es
Evaluación del rendimiento de grandes modelos de lenguaje en los exámenes de la junta de reumatología persas: precisión y razonamiento clínico de GPT-4o frente a GPT-5.1
Por qué esto importa para médicos y pacientes
La inteligencia artificial está entrando rápidamente en las aulas y clínicas médicas, pero la mayoría de las pruebas de estas herramientas se centran en inglés. Este estudio plantea una pregunta relevante para millones de hablantes de persa: ¿qué tan bien manejan los chatbots avanzados de IA, concretamente GPT‑4o y GPT‑5.1, preguntas complejas de reumatología redactadas en persa? La respuesta ayuda a educadores, residentes y pacientes a entender dónde estas herramientas pueden ayudar con seguridad en el aprendizaje y dónde la experiencia humana sigue siendo esencial.
Poniendo a la IA a prueba
Los investigadores reunieron 204 preguntas de opción múltiple de los exámenes oficiales de la Junta de Reumatología de Irán de 2023 y 2024, los mismos exámenes que los especialistas deben aprobar para certificarse. Tras eliminar siete preguntas defectuosas, se usaron 197 ítems. Cada pregunta, incluidas las imágenes o gráficos adjuntos, se introdujo en persa en GPT‑4o y en GPT‑5.1 en conversaciones separadas y nuevas. Se pidió a los modelos que eligieran la mejor respuesta y que explicaran su razonamiento, emulando cómo un residente podría consultar una herramienta de IA mientras estudia.
Comprobando tanto las respuestas como el razonamiento
El rendimiento se juzgó de dos maneras. Primero, las opciones elegidas por los modelos se compararon con la clave de respuestas oficial, obteniéndose una medida simple de precisión (acierto/error). Segundo, seis reumatólogos certificados valoraron de forma independiente la calidad de cada explicación en una escala de cinco puntos, desde un razonamiento claramente incorrecto hasta un razonamiento completo y clínicamente sólido. Las respuestas de cada modelo fueron puntuadas por dos reumatólogos distintos, que ignoraban las valoraciones del otro y la clave oficial. Esto permitió a los investigadores ver no solo si la IA “acertó”, sino si su lógica se asemejaba a la forma de pensar de los especialistas.
Cómo se comportó el modelo más nuevo
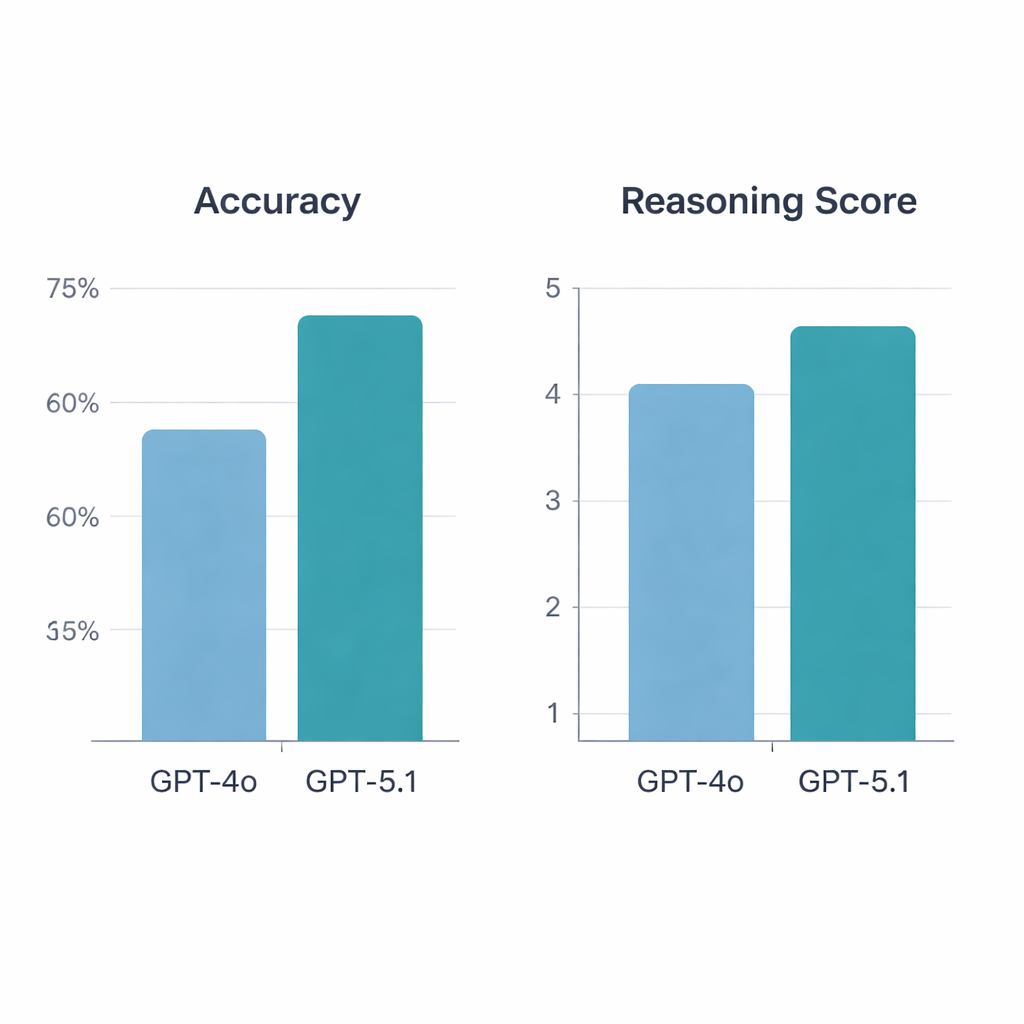
GPT‑5.1 superó claramente a GPT‑4o. En las 197 preguntas válidas, GPT‑4o respondió correctamente el 64,5 %, mientras que GPT‑5.1 alcanzó un 76 % de precisión, un salto estadísticamente significativo. Ambos modelos acertaron 113 preguntas y fallaron en 34, pero GPT‑5.1 resolvió 36 preguntas adicionales que GPT‑4o no respondió; GPT‑4o fue correctamente único en solo 13 casos. Cuando los reumatólogos evaluaron las explicaciones, GPT‑5.1 volvió a salir por delante, con una puntuación media de razonamiento de 4,47 sobre 5 frente a 4,13 de GPT‑4o, y recibió más valoraciones de máxima puntuación. A diferencia de GPT‑4o, cuya calidad de razonamiento variaba según si la pregunta se centraba en ciencias básicas, viñetas clínicas, diagnóstico o tratamiento, GPT‑5.1 mantuvo un rendimiento más uniforme en todas las categorías.
Fortalezas, lagunas y desacuerdos humanos
El estudio desveló matices importantes. Incluso cuando la respuesta final de un modelo era incorrecta, los especialistas a veces juzgaron su razonamiento como bastante coherente, lo que pone de relieve una brecha entre la puntuación de examen y el pensamiento clínico del mundo real. Al mismo tiempo, el acuerdo entre los evaluadores reumatólogos fue solo moderado, subrayando que los propios clínicos discrepan sobre lo que constituye un “buen razonamiento”. El idioma también pareció importar: trabajos previos en inglés y español han informado puntuaciones más altas para modelos similares, lo que sugiere que la IA todavía maneja mejor los principales idiomas mundiales que el persa. Los autores insisten en que estos chatbots pueden generar explicaciones convincentes que oculten errores factuales y en que su rendimiento puede cambiar a medida que los sistemas se actualizan.
Qué significa esto de cara al futuro
Para el lector no especializado, el mensaje es que la generación más reciente de chatbots de IA está mejorando en el manejo de exámenes médicos de especialidad en persa, pero no está lista para reemplazar la formación rigurosa ni el juicio experto. GPT‑5.1 puede ser un compañero de estudio útil para los residentes de reumatología: resumir temas, repasar casos y ofrecer explicaciones estructuradas; sin embargo, no debe considerarse la palabra final para decisiones de alto riesgo sobre diagnóstico o tratamiento. Los autores piden estudios más amplios y multilingües, pruebas repetidas a lo largo del tiempo y simulaciones clínicas realistas para determinar cómo integrar estas herramientas de forma segura en la educación médica y, eventualmente, en la atención clínica diaria de los pacientes.
Cita: Rafiei, F., Sadeghipour, S., Sheikhalishahi, S. et al. Evaluation of large Language model performance on Persian rheumatology board exams: accuracy and clinical reasoning of GPT-4o vs. GPT-5.1. Sci Rep 16, 7274 (2026). https://doi.org/10.1038/s41598-026-38716-z
Palabras clave: reumatología, educación médica persa, grandes modelos de lenguaje, razonamiento clínico, exámenes de certificación