Clear Sky Science · es
Red de fusión de características multinivel guiada por entropía para recuperación de imágenes basada en contenido de alta precisión
Encontrar la imagen adecuada, rápido
Cada día creamos y almacenamos cantidades asombrosas de fotografías —desde escaneos médicos e imágenes satelitales hasta grabaciones de seguridad y fotos personales—. Etiquetar y buscar estas imágenes manualmente es lento y poco fiable. Este artículo presenta una forma más inteligente para que los ordenadores «miren» las imágenes directamente y encuentren las que queremos con alta precisión, incluso en colecciones muy grandes y heterogéneas.
Por qué mirar los píxeles no basta
La búsqueda de imágenes tradicional a menudo se apoya en nombres de archivo o etiquetas simples como «gato» o «edificio». Pero la gente no siempre etiqueta las imágenes con cuidado, y los ordenadores solo ven píxeles crudos, no el significado rico que los humanos infieren. Los sistemas anteriores basados en contenido intentaron cerrar esta brecha usando pistas visuales sencillas como color, textura y forma. Esas señales ayudaron, pero normalmente se combinaban con niveles de importancia fijos. Eso significa que el sistema trataba algunas características como siempre más importantes que otras, incluso cuando una búsqueda concreta se beneficiaría de una mezcla distinta. Como resultado, la precisión empeoraba cuando cambiaban los tipos de imagen, la iluminación o las escenas.
Fusionando varias maneras de ver
Los autores proponen un nuevo marco de recuperación que fusiona dos tipos principales de evidencia visual. Primero, emplea modelos de aprendizaje profundo —redes bien conocidas como ResNet50 y VGG16— que han aprendido a reconocer patrones complejos en las imágenes. Segundo, añade descriptores «hechos a mano» tradicionales que capturan distribuciones de color, bordes y texturas de forma más controlada. En lugar de adivinar por adelantado cuánto debe importar cada tipo de característica, el sistema deja que los datos decidan. Mide cuánta información aporta cada característica para una búsqueda dada y ajusta su influencia sobre la marcha. Esta mezcla multinivel de señales de alto y bajo nivel ayuda al ordenador a formar una comprensión más rica y flexible de lo que hay en una imagen.
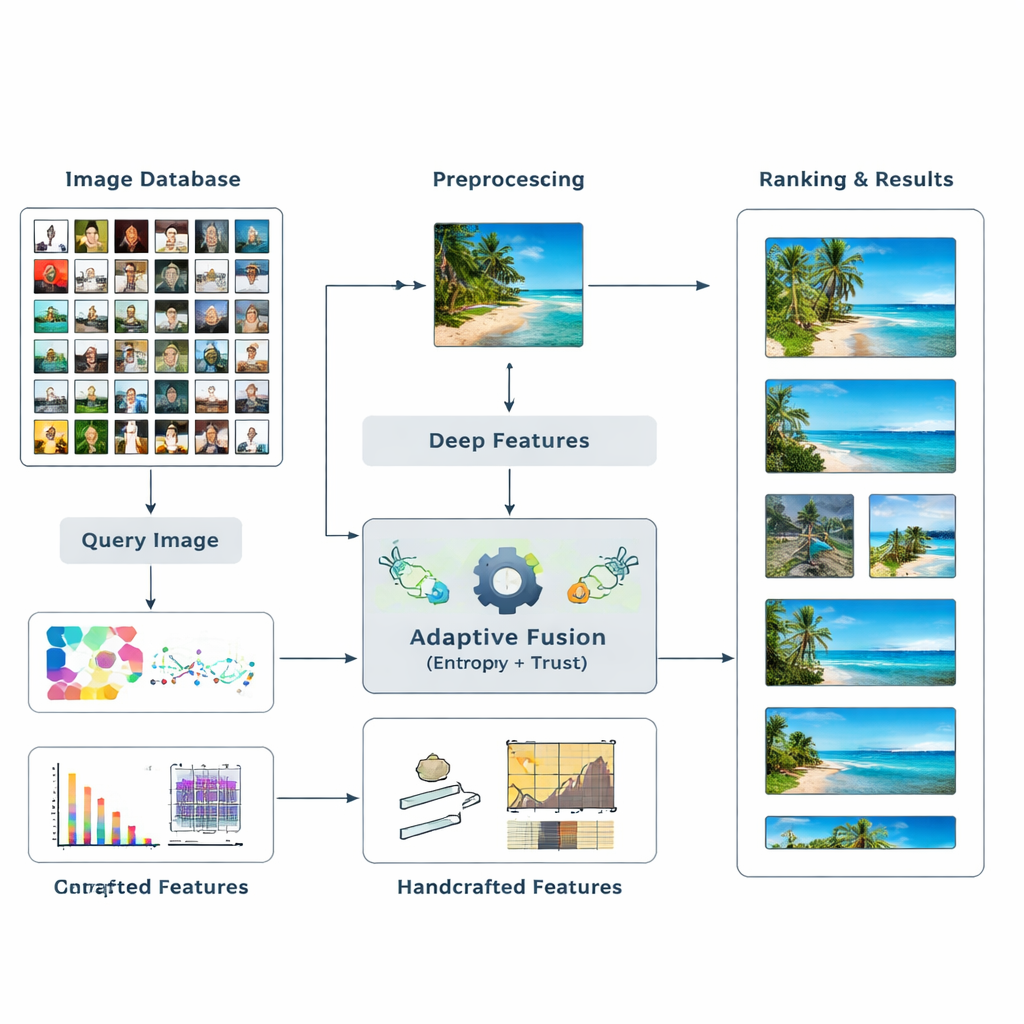
Permitir que la información y la confianza fijen los pesos
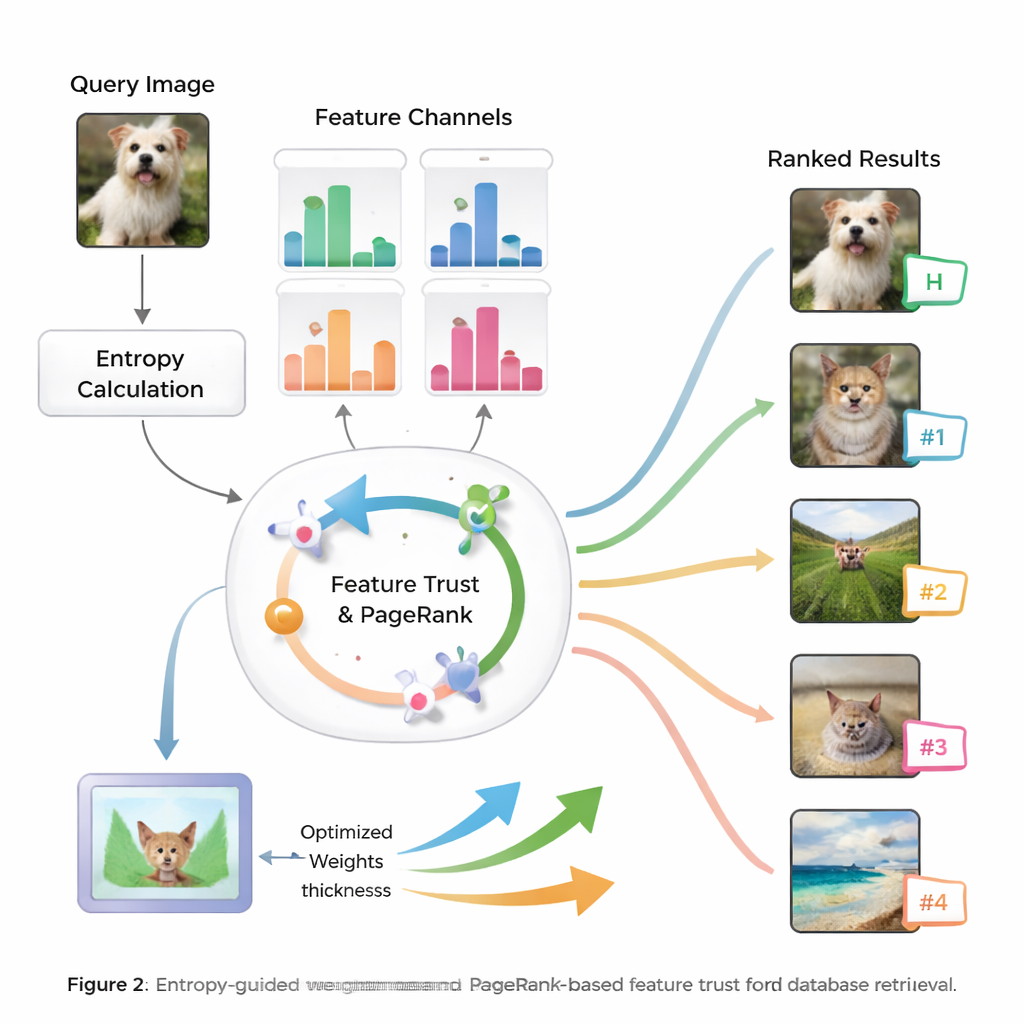
El núcleo del método es la idea de entropía, una medida de cuán incierta o dispersa está la información. Las características que separan de forma consistente las imágenes relevantes de las irrelevantes tienen menor entropía y se tratan como más «discriminativas». Para una nueva consulta, el sistema evalúa cómo se comporta cada característica en la base de datos y le asigna una puntuación inicial de importancia. A continuación examina cuán fiables son los resultados de búsqueda de cada característica —si los mejores emparejamientos realmente se parecen a la consulta— construyendo una noción de «confianza» para cada tipo de pista. Estas puntuaciones de confianza se introducen en un proceso similar a PageRank, parecido a cómo los primeros motores de búsqueda web decidían qué páginas eran más importantes, para refinar los pesos de las características mediante una red de transferencia de probabilidades.
De pesos inteligentes a mejores clasificaciones
Una vez que el sistema ha aprendido cuánto confiar en cada característica para la consulta actual, combina sus puntuaciones de similitud en una medida global para cada imagen de la base de datos. Luego se ordenan las imágenes por esa puntuación integral, de modo que las que coinciden con la consulta de las formas más significativas ascienden a la cima. Los autores prueban su enfoque en bancos de pruebas de imágenes ampliamente usados y lo comparan con varios métodos existentes. Informan mejoras de hasta un 8,6 % en la media de la precisión promedio y mejoras notables en la calidad de los diez primeros resultados, tanto en precisión como en la relevancia del orden. Las pruebas estadísticas muestran que estas mejoras probablemente no se deben al azar, lo que sugiere que el sistema es preciso y estable en muchos tipos de imágenes.
Qué significa esto para la búsqueda de imágenes cotidiana
En términos sencillos, esta investigación muestra cómo crear motores de búsqueda de imágenes que se adaptan a cada consulta en lugar de depender de reglas rígidas. Al dejar que el contenido informativo y la confianza ganada decidan qué señales visuales importan más, el sistema puede encontrar las imágenes correctas con mayor frecuencia, ya sea para localizar una huella dactilar en una gran base de datos policial, identificar un edificio específico en fotografías satelitales o recuperar la exploración médica adecuada. Los autores reconocen que el método es computacionalmente más pesado que los sistemas más simples, pero sostienen que su mayor fiabilidad y precisión lo hacen adecuado para repositorios grandes y críticos de imágenes donde encontrar la imagen correcta realmente importa.
Cita: Lavanya, M., Vennira Selvi, G., Gopi, R. et al. Entropy guided multi level feature fusion network for high precision content based image retrieval. Sci Rep 16, 7449 (2026). https://doi.org/10.1038/s41598-026-38699-x
Palabras clave: recuperación de imágenes basada en contenido, aprendizaje profundo, fusión de características, búsqueda de imágenes, ponderación por entropía