Clear Sky Science · es
Preentrenamiento en ImageNet y aprendizaje por transferencia en dos pasos para la clasificación de imágenes de cromosomas
Vistas más nítidas de nuestros cromosomas
Nuestros cromosomas contienen las instrucciones para construir y mantener nuestros cuerpos, y los médicos estudian su morfología para detectar trastornos genéticos y algunos tipos de cáncer. Hoy en día, los ordenadores pueden ayudar a interpretar imágenes de cromosomas, pero enseñarles a hacerlo bien es difícil porque las imágenes médicas son escasas y muy diferentes de las fotos cotidianas. Este estudio plantea una pregunta sencilla con gran impacto práctico: ¿pueden los ordenadores aprender mejor a partir de imágenes médicas relacionadas, no solo de enormes colecciones de fotos de gatos, perros y coches?
Por qué importan las imágenes de cromosomas
En los hospitales, los especialistas ordenan los 46 cromosomas de una persona en un gráfico llamado cariotipo, agrupados en 24 tipos (22 pares numerados más X e Y). Las bandas claras y oscuras a lo largo de cada cromosoma ayudan a revelar pérdidas o ganancias de fragmentos asociadas a condiciones como el síndrome de Down o ciertas leucemias. Tradicionalmente, los expertos clasifican estas bandas a simple vista, lo que es lento y subjetivo. El aprendizaje profundo ofrece una forma de automatizar este trabajo, pero estos sistemas suelen partir de modelos entrenados en ImageNet, un enorme conjunto de imágenes cotidianas. Ese salto —de fotos de vacaciones a vistas microscópicas de cromosomas— es enorme, y no está claro cuánto se traslada realmente esa experiencia.
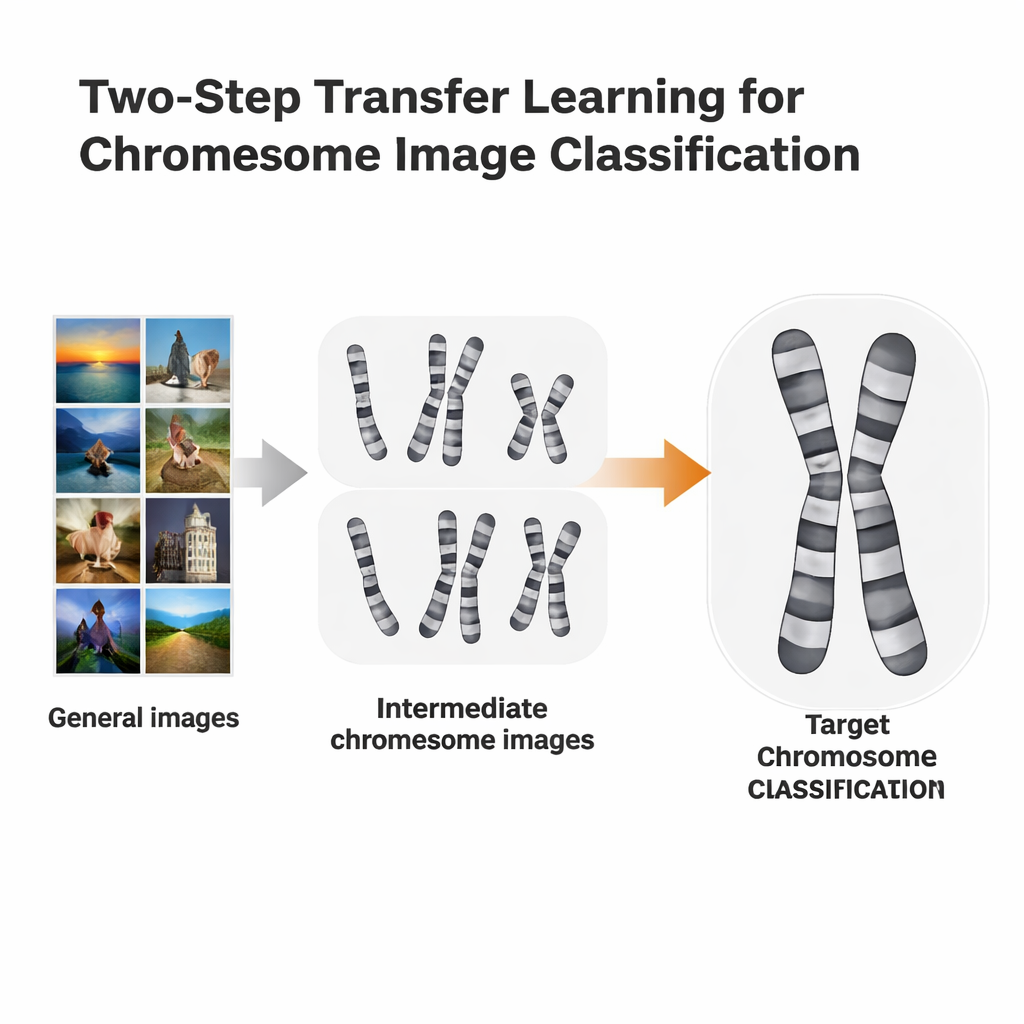
Un atajo de aprendizaje en dos pasos
Los investigadores probaron una ruta de entrenamiento más adaptada llamada aprendizaje por transferencia en dos pasos. En lugar de ir directamente de ImageNet a una tarea cromosómica específica, primero reajustaron (fine-tuned) modelos entrenados en ImageNet con imágenes de cromosomas de un método de tinción, y luego volvieron a reajustarlos con un segundo método ligeramente distinto. Utilizaron dos conjuntos de datos abiertos: imágenes Q-band, de menor calidad y más difíciles de leer, e imágenes G-band, más limpias y detalladas. Cada conjunto alternó el papel de “escalón” para el otro. La idea es similar al aprendizaje de idiomas: si ya conoces español, puede ser más fácil aprender italiano que saltar directamente desde el inglés.
Probando muchos “ojos” informáticos
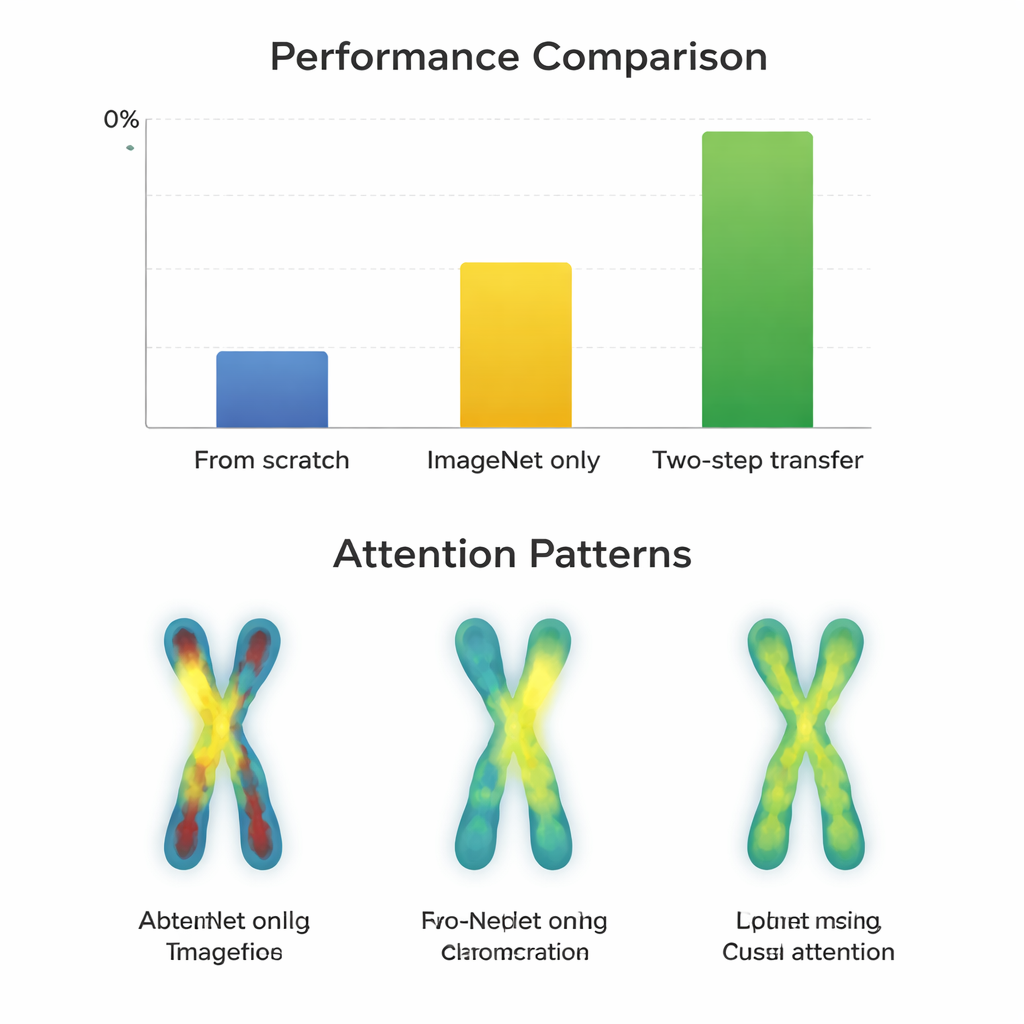
Para ver cuándo ayuda ese paso adicional, el equipo entrenó 66 clasificadores distintos, combinando 11 arquitecturas neuronales populares con tres estrategias: entrenar desde cero, reajustar solo desde ImageNet y usar transferencia en dos pasos. Midiieron el rendimiento con Macro-F1, una métrica que trata de forma equitativa a todos los tipos de cromosomas, incluidos los raros. Primero confirmaron que las imágenes Q-band y G-band son estadísticamente más similares entre sí que cualquiera de ellas a las fotos de ImageNet, lo que las hace prometedoras como escalones intermedios. Luego compararon cómo aprendían los distintos modelos bajo cada estrategia en los conjuntos de datos fáciles (G-band) y difíciles (Q-band).
Cuando compensa el paso adicional
En las imágenes de mayor calidad G-band, casi todos los modelos ya rindieron de forma excelente tras el reajuste desde ImageNet, con puntuaciones alrededor del 97–98 por ciento. Aquí, el entrenamiento en dos pasos aportó solo pequeñas mejoras —a menudo menos de un punto porcentual— y a veces incluso perjudicó a diseños de redes más antiguos. En contraste, en las imágenes más desafiantes Q-band, la historia cambió. Arquitecturas modernas y compactas como ConvNeXt, Swin Transformer, Vision Transformer y MobileNetV3 se beneficiaron claramente de la ruta en dos pasos, mejorando entre aproximadamente 0,8 y 3,3 puntos porcentuales respecto a ImageNet solo. Mapas visuales de dónde “miraban” los modelos mostraron la razón: con la transferencia en dos pasos, las redes se centraron de forma más uniforme a lo largo de las bandas de ambos brazos del cromosoma, en lugar de fijarse solo en contornos o en una región única. Sin embargo, redes muy grandes y antiguas como VGG no mejoraron e incluso empeoraron en ocasiones, lo que sugiere que un diseño más inteligente puede superar a la mera magnitud.
Límites impuestos por los propios datos
Los investigadores también examinaron los errores en imágenes G-band. Algunas fallas no se debieron a la estrategia de aprendizaje sino a entradas defectuosas, como cromosomas recortados de forma incorrecta al separar formas superpuestas. En esos casos, todos los métodos de entrenamiento tuvieron dificultades, y los mapas de atención estaban dispersos o fijados en bordes engañosos. Esto subraya un mensaje práctico para clínicas y desarrolladores: incluso la mejor canalización de entrenamiento no puede superar completamente la mala calidad de la imagen o los errores de preprocesamiento, especialmente cuando se trabaja con conjuntos de datos de tamaño moderado como los disponibles para imágenes de cromosomas.
Qué significa esto para el diagnóstico en la práctica
Para el público general, la conclusión clave es que la reutilización inteligente de imágenes médicas relacionadas puede mejorar la lectura automatizada de cromosomas, sobre todo cuando los datos objetivo son ruidosos o escasos y cuando se usan redes neuronales modernas y bien diseñadas. Para imágenes de alta calidad, el entrenamiento estándar basado en ImageNet puede ser ya suficiente. Pero cuando los patólogos trabajan con conjuntos de datos más difíciles, un paso adicional de aprendizaje con un tipo de imagen estrechamente relacionado puede afinar el “ojo” del ordenador, llevando el rendimiento al rango del 93–98 por ciento. Este enfoque podría aplicarse más allá de los cromosomas a muchas áreas de la imagen médica donde las etiquetas son limitadas, ayudando a acercar herramientas de IA fiables a la práctica clínica cotidiana.
Cita: Chen, T., Xie, C., Zhang, W. et al. ImageNet pre-training and two-step transfer learning in chromosome image classification. Sci Rep 16, 7572 (2026). https://doi.org/10.1038/s41598-026-38662-w
Palabras clave: clasificación de cromosomas, IA en imágenes médicas, aprendizaje por transferencia, modelos de aprendizaje profundo, cariotipado