Clear Sky Science · es
FedSCOPE: Recomendación secuencial federada entre dominios con aprendizaje contrastivo desacoplado y mejora semántica preservadora de la privacidad
Por qué importan recomendaciones más inteligentes y seguras
Cada vez que navegas películas, compras en línea o lees reseñas, los sistemas de recomendación deciden discretamente qué mostrarte a continuación. A medida que nuestra vida digital se extiende por muchas aplicaciones y sitios web, esos sistemas podrían funcionar mucho mejor si pudieran aprender de toda tu actividad a la vez—sin exponer nunca tus datos privados. Este artículo presenta FedSCOPE, una nueva forma para que distintas plataformas colaboren en recomendaciones que son a la vez más precisas y más respetuosas con la privacidad del usuario.
El problema con los motores de recomendación actuales
La mayoría de los sistemas de recomendación actuales viven dentro de una sola aplicación o sitio web y sólo ven una porción limitada de tu comportamiento. Eso hace que tengan dificultades con usuarios “fríos” que tienen poco historial, o con productos de nicho con los que interactúa poca gente. Cuando las empresas intentan combinar datos entre dominios—como libros y películas, o alimentos y utensilios de cocina—se topan con tres grandes problemas: los datos suelen ser escasos, las plataformas tienen tipos de usuarios y actividades muy diferentes, y las estrictas normas de privacidad hacen arriesgado agrupar datos sin procesar en un solo lugar. Arreglos sencillos, como añadir la misma cantidad de ruido preservador de la privacidad para todos, suelen debilitar la protección o perjudicar gravemente la precisión.
Permitir que los modelos de lenguaje rellenen los vacíos
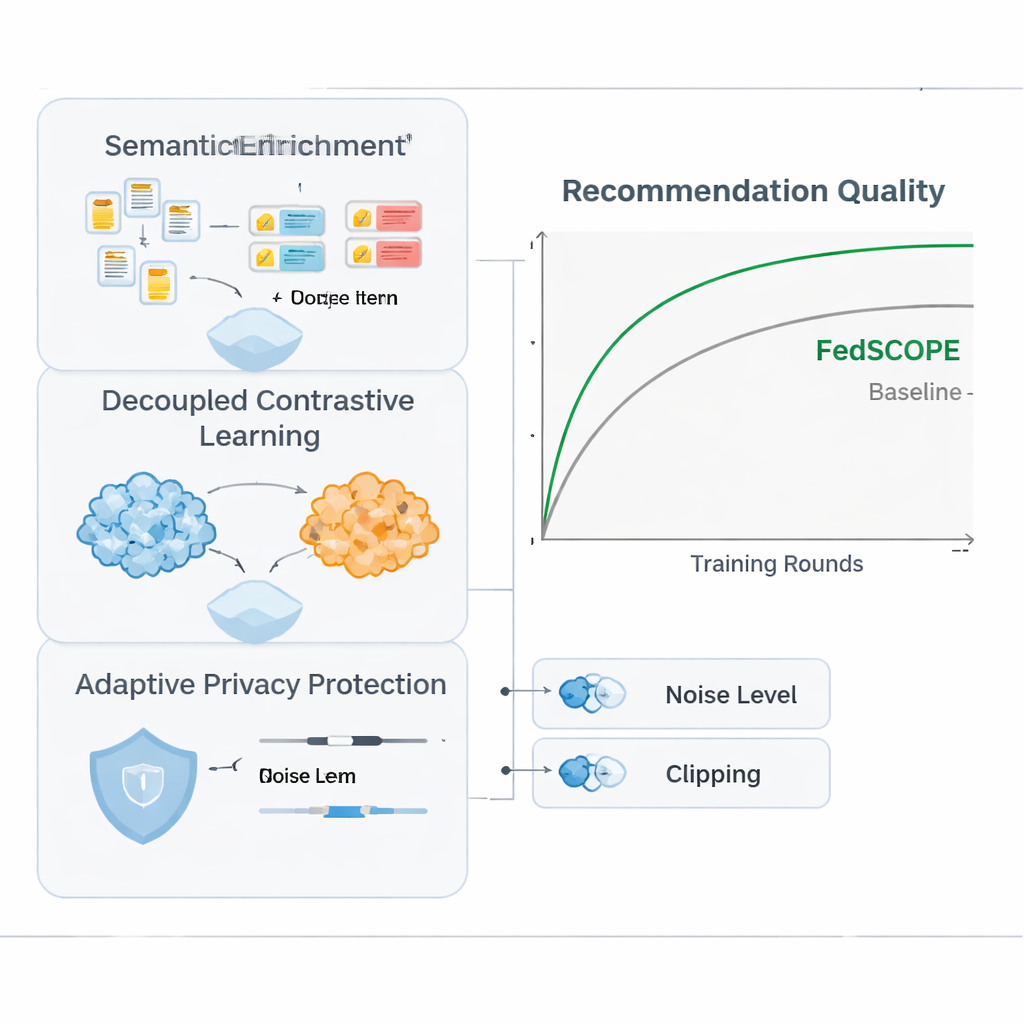
FedSCOPE aborda el problema de la escasez haciendo que cada plataforma enriquezca sus datos usando un modelo de lenguaje grande (LLM), pero de una forma poco habitual y consciente de la privacidad. En lugar de enviar historiales de usuario a un servicio de IA remoto durante cada recomendación, cada cliente ejecuta un proceso offline de una sola vez: alimenta títulos e información básica del ítem (por ejemplo, el nombre y el género de una película) a un LLM y solicita descripciones estructuradas, como temas probables, hábitos de visionado o intereses relacionados. Estos atributos generados permanecen en el dispositivo o servidor local y se fusionan con los historiales de clics y visualización habituales mediante una red neuronal ligera. Esto proporciona al sistema una sensación más rica tanto de usuarios como de ítems, lo cual es especialmente útil cuando sólo hay pocas interacciones registradas. Como el proceso es offline y local, el comportamiento en crudo nunca abandona la plataforma y no hay dependencia continua de servicios de IA externos.
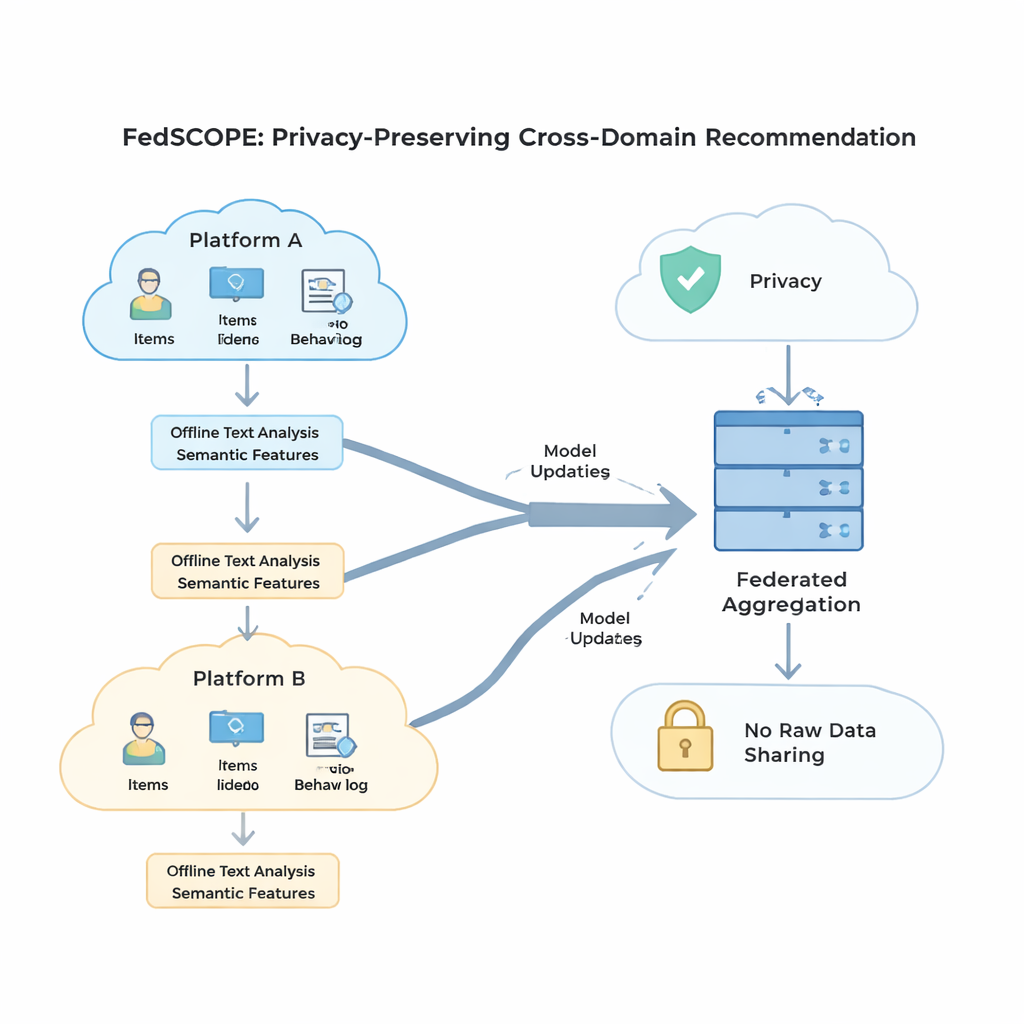
Separar lo personal de lo compartido
Para aprovechar el comportamiento procedente de múltiples dominios sin mezclar señales de forma perjudicial, FedSCOPE introduce una estrategia de entrenamiento denominada aprendizaje contrastivo desacoplado. En términos simples, el sistema aprende dos cosas a la vez. Primero, dentro de cada dominio—por ejemplo, sólo el de películas—agrupa a los usuarios que se comportan de forma similar y separa a los que no, afinando la noción de gusto personal en ese entorno. Segundo, entre dominios, alinea las representaciones del mismo usuario mientras mantiene a distintos usuarios diferenciados, de modo que lo que ves puede ayudar a predecir lo que podrías leer o comprar, sin confundirte con otros. Al manejar por separado estos objetivos “intra-dominio” e “inter-dominio”, el método evita una trampa común en la que forzar todo a un molde compartido destruye las preferencias finas.
Proteger la privacidad sin desechar la utilidad
La privacidad matemática fuerte, conocida como privacidad diferencial, suele implicar añadir ruido aleatorio a las actualizaciones del modelo antes de compartirlas con un servidor central. Muchos sistemas anteriores usaban los mismos ajustes de privacidad para todos los participantes, lo cual encaja mal cuando algunos clientes tienen millones de usuarios y otros sólo unos pocos miles. FedSCOPE, en cambio, otorga a cada cliente un presupuesto de privacidad personalizado y adapta cuánto recorta y perturba sus actualizaciones en función del tamaño de sus datos y su comportamiento pasado. Las plataformas grandes y con muchos datos pueden aportar información más precisa sin ser sobre-ruidosas, mientras que las más pequeñas se protegen de forma más agresiva. Todas las actualizaciones se combinan luego mediante agregación segura, de modo que el servidor nunca ve ninguna contribución individual en claro.
Qué muestran los experimentos en la práctica
Los autores evaluaron FedSCOPE con datos reales de compras de Amazon, emparejando dominios como Películas con Libros y Alimentos con Cocina. Lo compararon con una variedad de métodos modernos de recomendación, incluidos otros enfoques preservadores de la privacidad y entre dominios. En múltiples medidas de precisión, FedSCOPE se situó consistentemente en lo más alto o cerca de la cima. Convergió más rápido durante el entrenamiento, funcionó mejor para usuarios con muy pocas interacciones pasadas y se mantuvo robusto cuando cambiaba el número de clientes participantes o la fracción muestreada en cada ronda. De forma importante, cuando el equipo endureció las restricciones de privacidad, la estrategia adaptativa de FedSCOPE mantuvo el rendimiento mucho más alto que los sistemas que usan privacidad diferencial de talla única.
Qué significa esto para los usuarios cotidianos
Desde la perspectiva de un público general, FedSCOPE apunta hacia un futuro donde tus apps favoritas pueden colaborar para entender tus gustos más profundamente sin llegar a agrupar tus datos en crudo. Al enriquecer historiales escasos con la información de modelos de lenguaje, separar cuidadosamente lo específico de cada dominio de lo compartido y ajustar los controles de privacidad a cada participante, el marco ofrece recomendaciones que son a la vez más relevantes y más respetuosas con la información personal. En términos prácticos, eso podría significar mejores sugerencias sobre qué ver, leer o comprar a continuación—sin tener que renunciar a tu privacidad digital.
Cita: Zhao, L., Lin, Y., Qin, S. et al. FedSCOPE: Federated cross-domain sequential recommendation with decoupled contrastive learning and privacy-preserving semantic enhancement. Sci Rep 16, 7420 (2026). https://doi.org/10.1038/s41598-026-38628-y
Palabras clave: recomendación federada, IA preservadora de la privacidad, personalización entre dominios, modelos de lenguaje grandes, privacidad diferencial