Clear Sky Science · es
Explorando la interacción docente‑estudiante a través de modelos multimodales de lenguaje: una investigación empírica
Por qué importa observar las aulas con IA
Cualquiera que haya estado en un aula sabe que la manera en que profesores y alumnos interactúan puede marcar la diferencia entre el aburrimiento y un aprendizaje real. Sin embargo, resulta sorprendentemente difícil estudiar esos intercambios momento a momento: los observadores se cansan, los juicios humanos difieren y los datos de vídeo se vuelven rápidamente abrumadores. Este artículo explora cómo un nuevo tipo de inteligencia artificial —modelos multimodales de lenguaje a gran escala que pueden “ver” imágenes y “leer” texto— puede ayudar a investigadores y centros educativos a entender la vida compleja del aula de forma más rápida y objetiva.
Convertir clases reales en datos de investigación
Los investigadores partieron de vídeos de aula ordinarios de escuelas primarias y secundarias chinas, disponibles públicamente en una plataforma educativa nacional. De 30 lecciones extrajeron cerca de 2.400 imágenes fijas que capturaban momentos clave de la enseñanza y el aprendizaje. Cada imagen fue etiquetada según cinco patrones de interacción fáciles de entender: guiada (explicación del profesor), colaborativa (alumnos trabajando juntos), de preguntas (preguntar y responder), independiente (alumnos trabajando por su cuenta) y expositiva (alumnos presentando ante la clase). Expertos en tecnología educativa ayudaron a refinar estas categorías para que coincidieran con lo que observadores experimentados buscan en aulas reales.
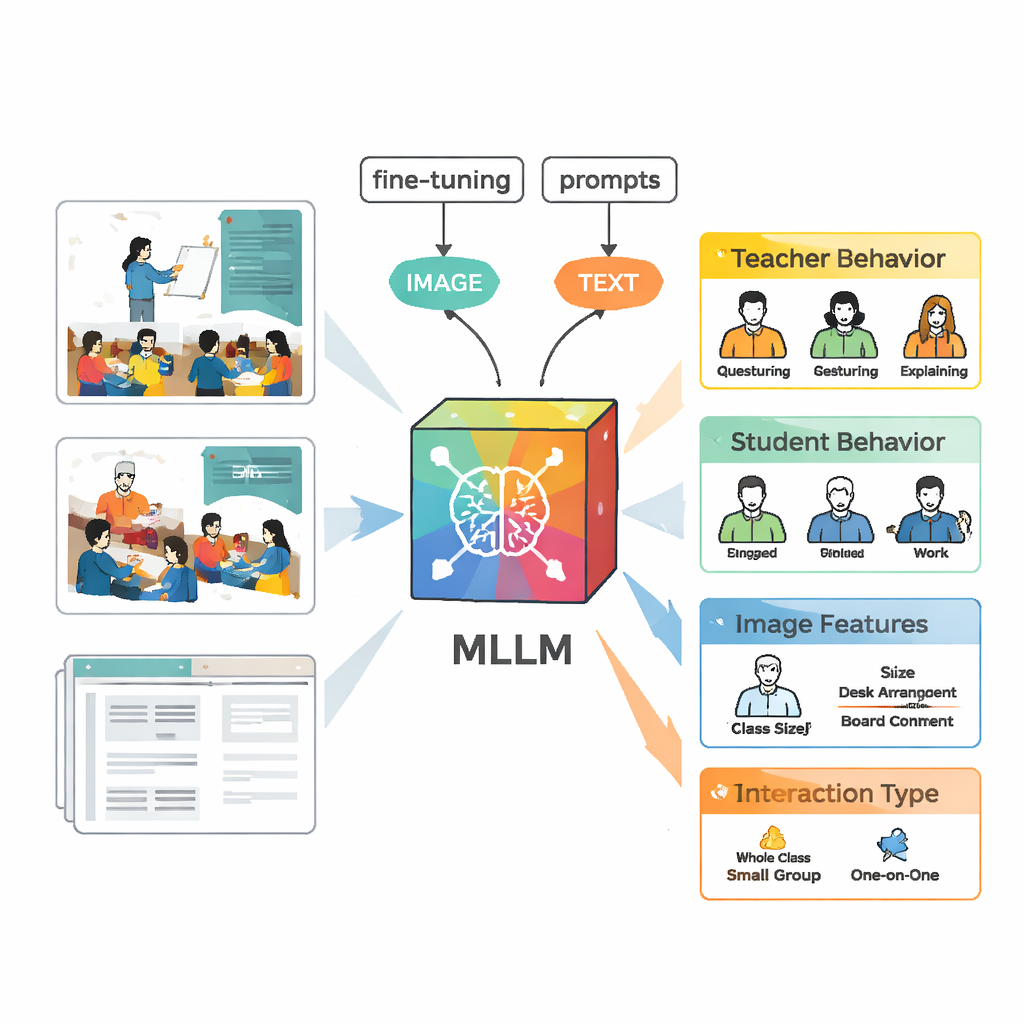
Enseñar a una IA a ver la dinámica del aula
Para analizar estas escenas, el equipo utilizó un modelo multimodal de lenguaje a gran escala llamado VisualGLM‑6B, que acepta imágenes y texto como entrada. Dado que el modelo original fue entrenado de forma general y no específicamente en aulas, los investigadores lo "ajustaron" finamente usando sus imágenes etiquetadas. Adoptaron una técnica llamada LoRA que modifica solo un pequeño número de parámetros internos del modelo, haciendo el entrenamiento más eficiente pero aún potente. También diseñaron indicaciones cuidadosas —instrucciones estructuradas que piden al modelo describir el comportamiento del profesor, el comportamiento de los alumnos, rasgos visuales y el tipo de interacción en un formato coherente— para que la salida fuera más fácil de comparar con los juicios de expertos humanos.
Construir mejores etiquetas con humanos y máquinas
Crear un conjunto de entrenamiento de alta calidad requirió algo más que señalar el modelo hacia los vídeos. Primero, VisualGLM generó descripciones básicas de cada imagen. Anotadores humanos corrigieron errores y completaron el contexto faltante, como quién hablaba o si los alumnos estaban escuchando o discutiendo. A continuación, introdujeron estas descripciones pulidas en ChatGPT que, guiado por indicaciones personalizadas, generó análisis estructurados siguiendo las cinco categorías de interacción. Los expertos revisaron y editaron de nuevo estos análisis generados por la IA. El resultado final fue un conjunto de datos rico en el que cada imagen llevaba un relato detallado y fiable de lo que profesores y alumnos estaban haciendo.
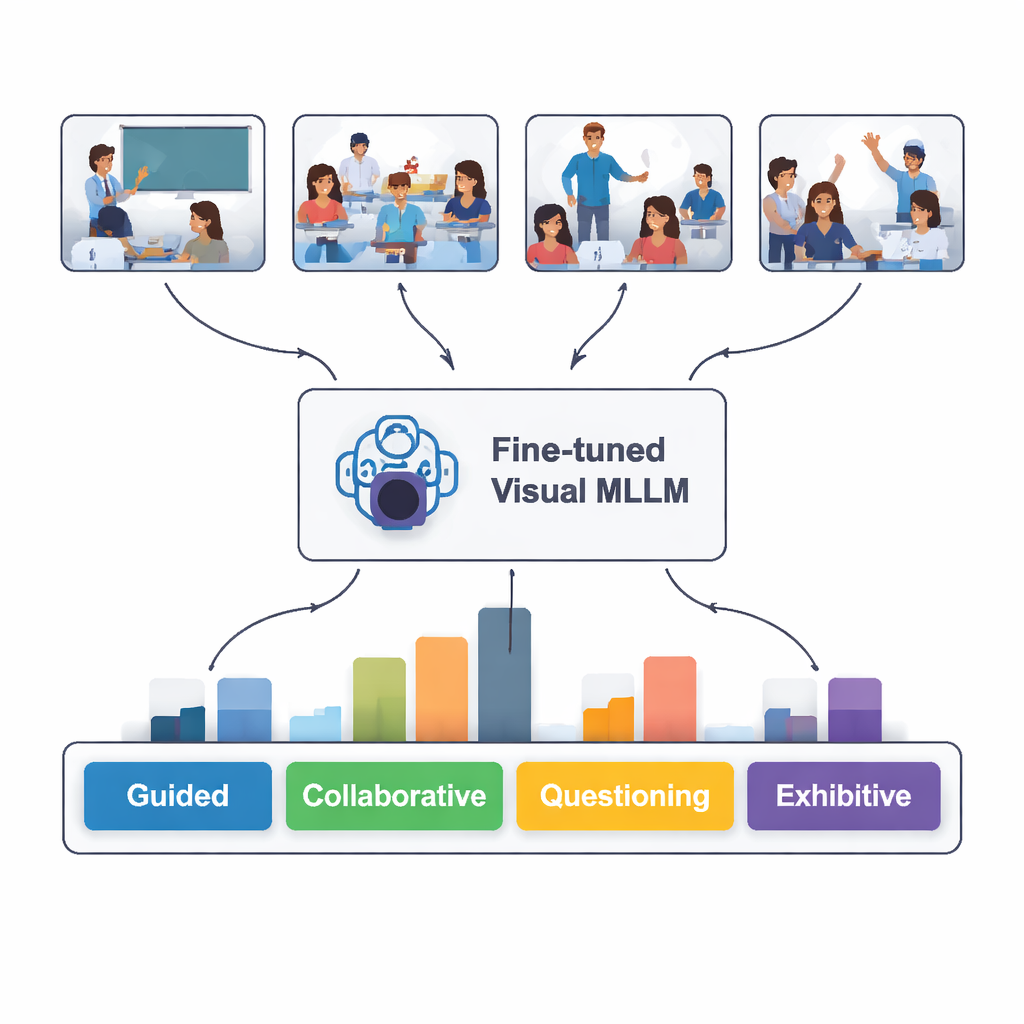
¿Qué tan bien “leyó” la IA el aula?
Cuando se probó con 100 imágenes nuevas de aula que nunca había visto, el modelo afinado identificó correctamente el tipo de interacción el 82 por ciento de las veces. Funcionó mejor reconociendo situaciones guiadas, independientes y expositivas —cuando el profesor explica claramente, los alumnos trabajan en silencio por su cuenta o un alumno presenta al frente—. Tuvo más dificultades con el trabajo colaborativo y las situaciones de preguntas, donde el lenguaje corporal y la disposición de los asientos pueden ser ambiguos incluso para las personas. Una comparación textual más profunda mostró que las descripciones escritas del modelo a menudo coincidían bastante con los análisis de expertos, aunque en ocasiones "alucinó" detalles que no estaban presentes en las imágenes o interpretó mal un gesto sutil.
Qué significa esto para las aulas del futuro
Para un lector no especializado, el mensaje principal es que los sistemas de IA están empezando a ser capaces de observar aulas y resumir cómo se desarrolla la enseñanza y el aprendizaje, con un nivel de estructura y consistencia que sería difícil para los humanos mantener a lo largo de miles de escenas. Si bien no son perfectos —especialmente en formas sutiles de discusión y interrogación—, el enfoque muestra que los modelos multimodales de lenguaje a gran escala ya pueden apoyar la investigación educativa y, eventualmente, herramientas de retroalimentación para el aula. A medida que estos modelos empiecen a incluir sonido, gestos y conjuntos de datos más amplios y variados, podrán ayudar a los docentes a ver patrones en su práctica que antes estaban ocultos, ofreciendo una nueva lente sobre cómo las interacciones cotidianas moldean el aprendizaje de los alumnos.
Cita: Chen, G., Han, G., Niu, J. et al. Exploring teacher-student interaction through multimodal large language models: an empirical investigation. Sci Rep 16, 7602 (2026). https://doi.org/10.1038/s41598-026-38626-0
Palabras clave: interacción docente‑estudiante, analítica del aula, IA multimodal, tecnología educativa, modelos de lenguaje a gran escala