Clear Sky Science · es
Clasificación incremental inteligente mediante una red neuronal dinámica mejorada con saltamontes para flujos de datos
Por qué importa que los datos cambien constantemente
Desde redes eléctricas y fábricas hasta pagos en línea, los sistemas modernos generan datos cada segundo. Ocultas en estos flujos continuos de datos hay alertas tempranas de fallos en equipos, ciberataques o subidas inminentes de precios. El desafío es que este río de información no se detiene y su comportamiento cambia con el tiempo. El artículo resumido aquí presenta una nueva forma de entrenar redes neuronales para que puedan seguir aprendiendo de datos en vivo sin ralentizarse ni perder precisión, haciéndolas más útiles para la supervisión y la toma de decisiones en el mundo real.
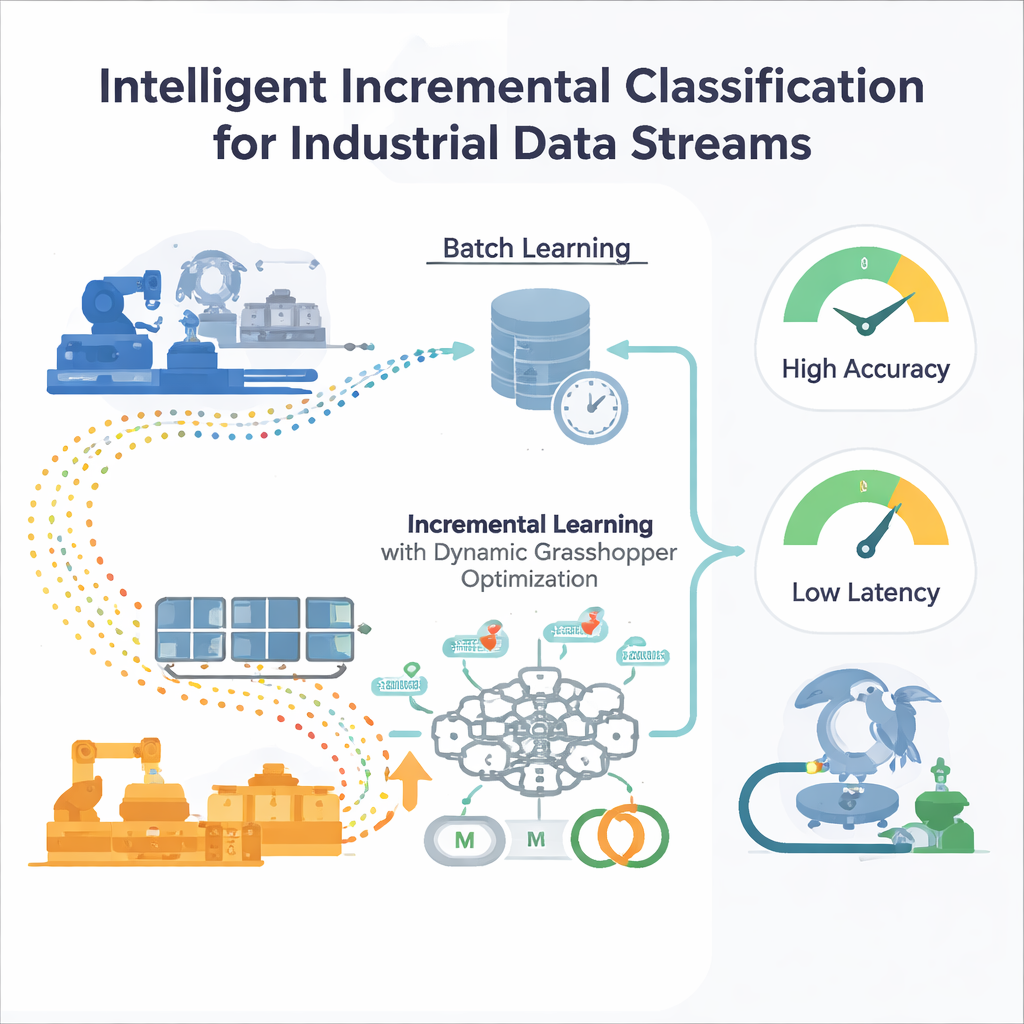
Los límites del entrenamiento puntual
La mayoría de los modelos tradicionales de aprendizaje automático se entrenan en “lotes”: los ingenieros recogen un gran conjunto de datos histórico, afinan el modelo y luego lo despliegan. Esto funciona si el mundo permanece más o menos igual. Pero en entornos industriales, las condiciones derivan: los patrones de demanda cambian, los sensores envejecen, los mercados fluctúan. Un modelo congelado en el tiempo deja de ver nuevos patrones, y volver a entrenarlo desde cero sobre conjuntos de datos cada vez mayores es costoso y lento. Los métodos estándar de ajuste automático, como la búsqueda en cuadrícula o los algoritmos evolutivos, también suponen datos fijos, lo que implica que deben reiniciarse cada vez que la distribución de datos cambia, algo impráctico para sistemas que están siempre en funcionamiento.
Una red neuronal que aprende sobre la marcha
Los autores proponen un marco de aprendizaje incremental centrado en un perceptrón multicapa (MLP), un tipo común de red neuronal. En lugar de alimentar a la red con todos los datos pasados de una vez, el flujo de datos entrante se divide en ventanas manejables. Cada nueva ventana se convierte en un pequeño paso de entrenamiento que actualiza los pesos internos de la red y luego se descarta—una estrategia de “entrenar y olvidar” que mantiene bajo el uso de memoria. De forma crucial, el sistema no depende de ajustes de entrenamiento fijos. Dos perillas clave que controlan el comportamiento de aprendizaje—la tasa de aprendizaje (qué tan grande es cada actualización) y el momentum (qué tan suaves son las actualizaciones)—se ajustan continuamente a medida que el flujo evoluciona, de modo que el modelo puede permanecer receptivo sin volverse inestable.
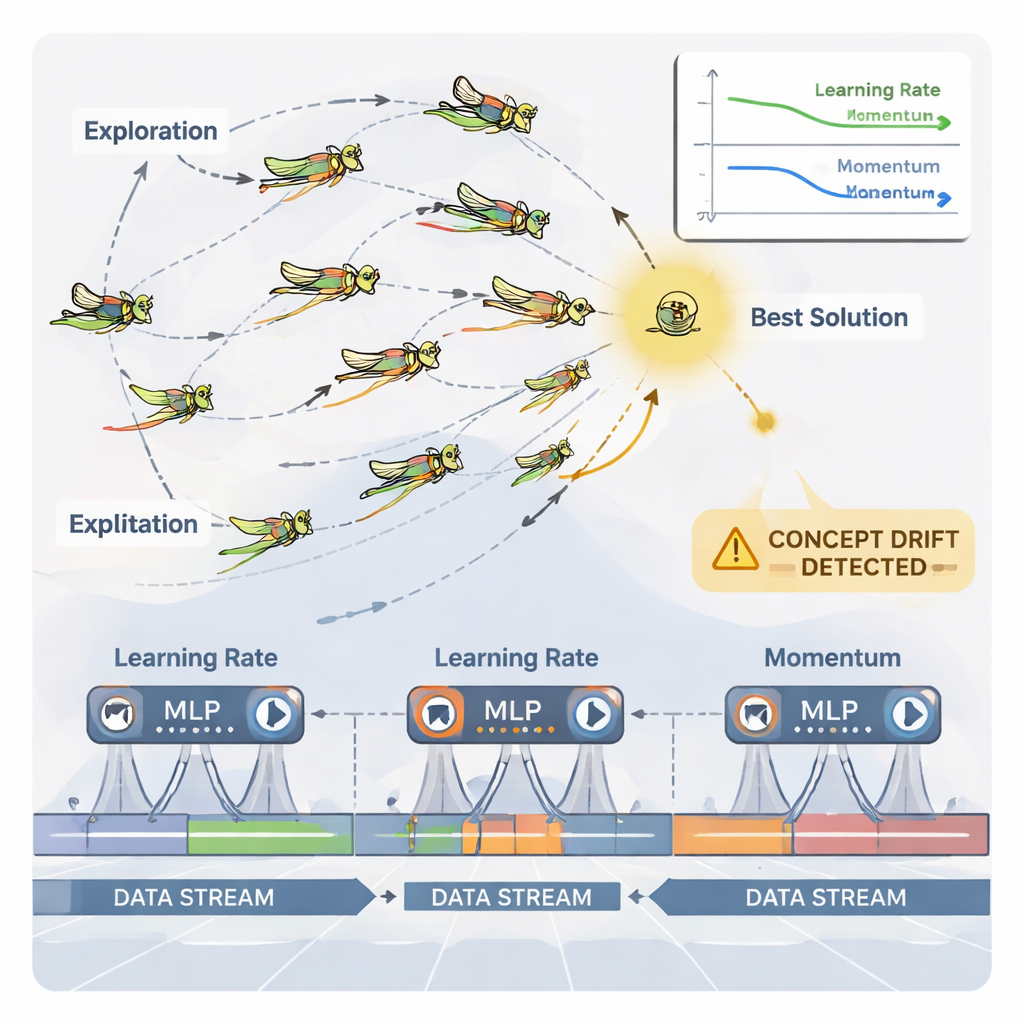
Saltamontes como afinadores inteligentes de parámetros
Para manejar este ajuste continuo, el artículo utiliza un optimizador inspirado en la naturaleza llamado Algoritmo Dinámico de Optimización por Saltamontes (DGOA). Imagine un enjambre de saltamontes virtuales explorando posibles combinaciones de tasa de aprendizaje y momentum. Al principio, vagan ampliamente para buscar buenas regiones; más adelante, reducen sus movimientos para refinar las opciones prometedoras. En esta variante dinámica, el tamaño de sus pasos y la atracción hacia la mejor solución cambian con el tiempo según el rendimiento de la red neuronal. El sistema también vigila el “concept drift” —cambios bruscos en los errores de predicción o en los propios datos—. Cuando se detecta una deriva, algunos saltamontes se reinician y sus pasos temporales aumentan, lo que permite al optimizador buscar rápidamente en nuevas regiones y escapar de configuraciones obsoletas.
Poniendo el método a prueba
Los investigadores evaluaron su enfoque con un conjunto de datos real del mercado eléctrico de Australia, donde el objetivo era predecir si los precios subirían o bajarían. En comparación con métodos comunes de ajuste como búsqueda en cuadrícula, búsqueda aleatoria, optimización por enjambre de partículas, algoritmos genéticos, optimización por colonia de hormigas y el algoritmo estándar de saltamontes, la versión dinámica emparejada con aprendizaje incremental alcanzó la mayor precisión (alrededor del 89,5%) mientras consumía menos tiempo de cómputo y menos iteraciones. Experimentos adicionales mostraron que el método se adapta mejor tanto a flujos de datos estables como cambiantes, escala desde miles hasta miles de millones de muestras manteniendo la memoria bajo control, y rinde de forma competitiva en tareas como mantenimiento predictivo, detección de anomalías y detección de fraude, además de en benchmarks estándar de optimización matemática.
Qué significa esto en la práctica
Para los no expertos, la conclusión es que este trabajo ofrece una forma de mantener las redes neuronales “vivas” y bien afinadas en entornos donde los datos no paran y las condiciones cambian constantemente. En lugar de detener repetidamente el sistema para reconstruir modelos desde cero, el marco propuesto permite a una red ligera actualizarse ventana a ventana, mientras un optimizador basado en enjambres ajusta continuamente la velocidad y la suavidad del aprendizaje. El resultado es una adaptación más rápida a nuevos patrones, mejor precisión a largo plazo y un uso más eficiente de los recursos informáticos—ingredientes clave para una toma de decisiones fiable en tiempo real en sectores como la energía, la manufactura y las finanzas.
Cita: Darwish, S.M., El-Shoafy, N.A. Intelligent incremental classification using a dynamic grasshopper-enhanced neural network for data streams. Sci Rep 16, 7730 (2026). https://doi.org/10.1038/s41598-026-38571-y
Palabras clave: flujos de datos, aprendizaje incremental, redes neuronales, optimización de hiperparámetros, inteligencia de enjambre