Clear Sky Science · es
Un modelo de aprendizaje automático interpretable que utiliza datos clínicos de rutina para predecir la recurrencia temprana en el carcinoma hepatocelular
Por qué esto importa para pacientes y familias
Para las personas que se someten a cirugía para extirpar un cáncer de hígado, una de las preguntas más urgentes es: «¿Volverá el cáncer pronto?». Hoy, los médicos solo pueden ofrecer estimaciones aproximadas, a menudo basadas en sistemas de estadificación general que tratan a muchos pacientes diferentes como si fueran iguales. Este estudio presenta una nueva forma de usar la información que los hospitales ya recogen —análisis de sangre rutinarios y resultados de imágenes— junto con inteligencia artificial interpretable para ofrecer a cada paciente una imagen más clara y personalizada de su riesgo a corto plazo de que el cáncer reaparezca.
Un cáncer común con una tasa de recaída persistente
El carcinoma hepatocelular es el tipo más frecuente de cáncer primario de hígado y una causa importante de muertes por cáncer en todo el mundo. Incluso cuando los cirujanos extirpan por completo los tumores visibles, más del 70% de los pacientes ven la enfermedad reaparecer en un plazo de cinco años. La recurrencia temprana —aproximadamente dentro de los dos años tras la cirugía— es especialmente preocupante, porque suele reflejar células cancerosas agresivas que ya se han diseminado dentro del hígado y empeora drásticamente la supervivencia. Los sistemas de estadificación clínica existentes, como TNM o el sistema BCLC (Barcelona Clinic Liver Cancer), pueden clasificar a los pacientes en categorías generales, pero a menudo no logran identificar con precisión quién está realmente en alto riesgo de una recaída temprana.
Convertir resultados de pruebas rutinarias en una puntuación de riesgo
Los investigadores se basaron en los registros de 1.120 pacientes que habían recibido cirugía aparentemente curativa del hígado en dos hospitales importantes de China entre 2014 y 2024. Se centraron únicamente en la información disponible antes de la intervención: edad y sexo, características de imagen como el tamaño del tumor más grande y si había tumores múltiples, y un amplio panel de pruebas de laboratorio estándar realizados en los días previos a la cirugía. A partir de estos datos, rastrearon nueve predictores clave vinculados a la probabilidad de recurrencia. En lugar de apoyarse en una única fórmula matemática, combinaron tres enfoques distintos de aprendizaje automático y promediaron sus salidas en una única puntuación de riesgo entre 0 y 1. Después, los pacientes se agruparon en categorías de bajo, moderado y alto riesgo en función de esa puntuación. 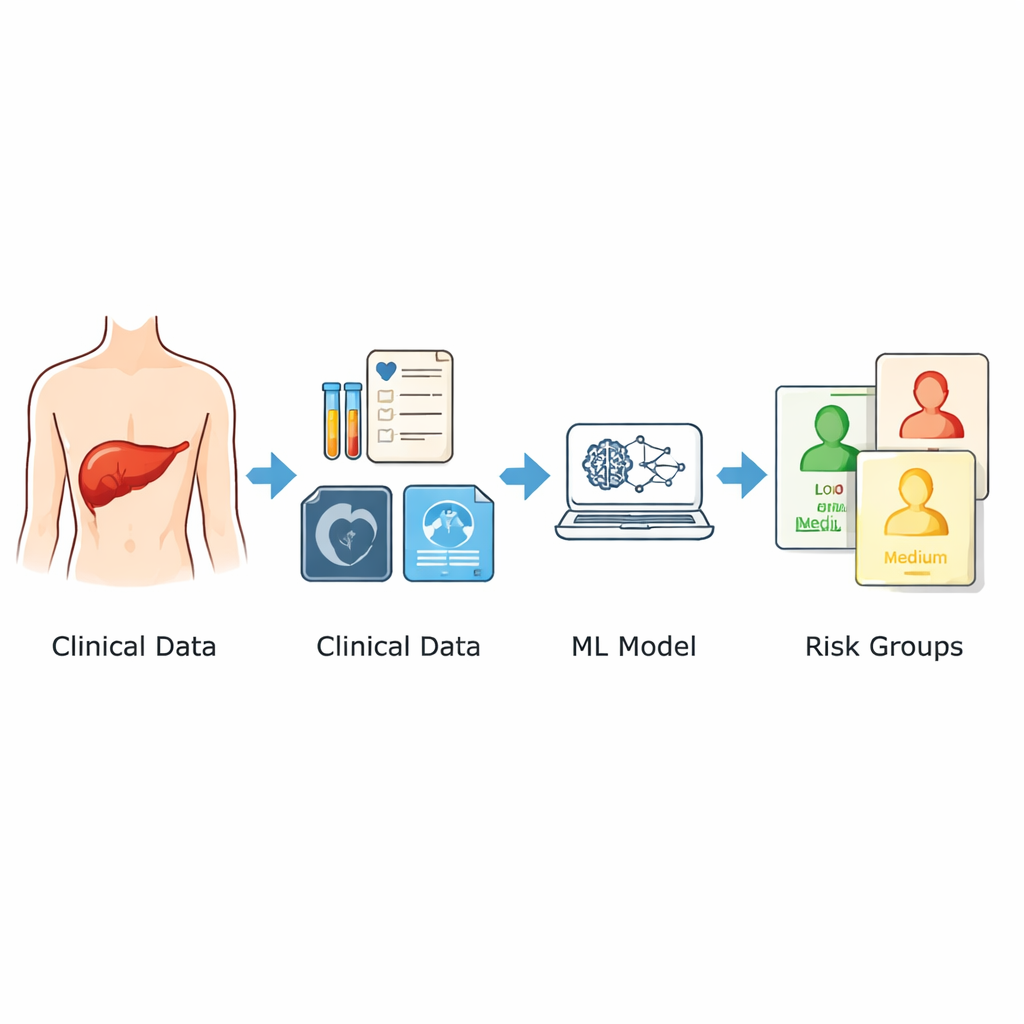
Superando a los sistemas de estadificación estándar
Para evaluar el rendimiento del modelo, el equipo lo probó primero en un conjunto de pacientes «retirado» del hospital original y luego en un grupo independiente del segundo hospital. En ambos contextos, el nuevo modelo fue claramente mejor que los sistemas de estadificación tradicionales para distinguir entre quienes permanecerían libres de cáncer y quienes recaerían dentro de 24 meses. En el grupo de prueba interno, la precisión del modelo a lo largo del tiempo, medida por una estadística estándar llamada área bajo la curva, fue de aproximadamente 0,76, frente a cerca de 0,55 a 0,64 para los métodos de estadificación habituales. Las personas en el grupo de alto riesgo presentaron la peor supervivencia libre de recurrencia; quienes estaban en el grupo de riesgo moderado vieron reducirse su riesgo de recurrencia en torno a un 60%, y las del grupo de bajo riesgo tuvieron aproximadamente un 90% menos de riesgo que el grupo de alto riesgo. Estas diferencias significativas se mantuvieron también en el hospital externo y fueron consistentes en la mayoría de los subgrupos, como pacientes jóvenes y mayores, hombres y mujeres, y aquellos con tumores grandes o pequeños.
Abrir la caja negra de la inteligencia artificial
Una crítica frecuente al aprendizaje automático en medicina es que funciona como una caja negra: puede predecir bien, pero incluso los especialistas no ven por qué. Para abordar esto, los autores aplicaron un método llamado SHapley Additive exPlanations, o SHAP, que descompone cada predicción en las contribuciones de cada factor de entrada. El análisis mostró que el tamaño del tumor fue el factor individual que más impulsó un mayor riesgo en los tres algoritmos, seguido de características como el número de tumores e indicadores sanguíneos de la función hepática y la inflamación. Curiosamente, el nivel de cloruro en sangre tendió a empujar el riesgo en la dirección opuesta, actuando como un factor protector en este conjunto de datos. Para pacientes individuales, el modelo puede generar gráficos sencillos tipo barra que muestran, por ejemplo, cómo un diámetro tumoral grande y marcadores sanguíneos desfavorables elevan la puntuación de riesgo, mientras que una mejor función hepática la reduce. 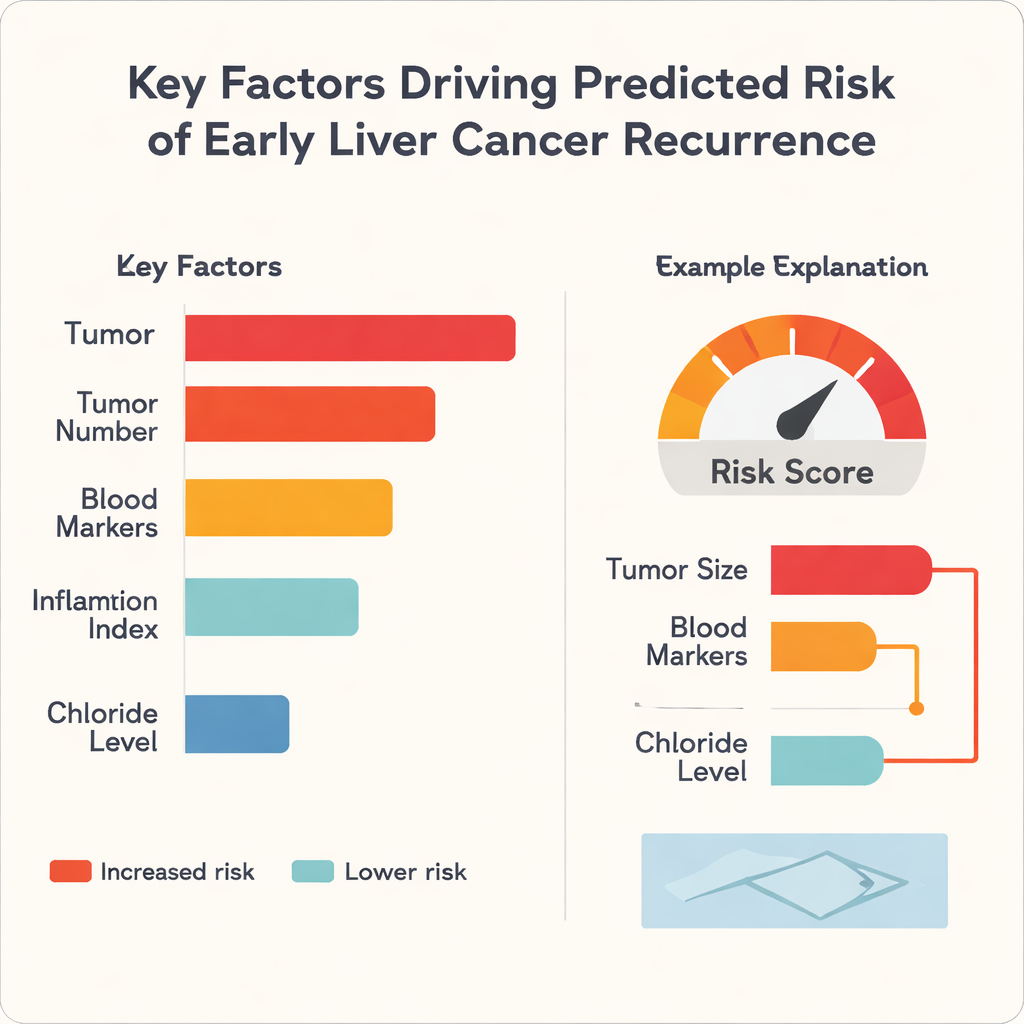
Qué podría significar esto en la práctica clínica
Puesto que el modelo se basa en datos que los hospitales ya recogen y no requiere exploraciones especiales ni costosas pruebas genéticas, podría desplegarse en muchos entornos asistenciales, incluidos aquellos con recursos limitados. Antes de la cirugía, los médicos podrían usarlo para identificar a las personas que necesitan seguimientos más intensivos o que podrían beneficiarse de tratamientos adicionales tras la operación, al tiempo que se evita a los pacientes de bajo riesgo someterse a pruebas y preocupaciones innecesarias. Los autores señalan que su estudio es retrospectivo y proviene de una población de pacientes específica, por lo que todavía se necesitan ensayos prospectivos en entornos más diversos. No obstante, su trabajo ilustra cómo una IA transparente y explicable puede convertir cifras de laboratorio y hallazgos de imagen familiares en pronósticos individualizados y significativos que apoyen la toma de decisiones compartida entre pacientes y sus equipos de atención.
Cita: Guo, DF., Wen, Q., Zhang, X. et al. An interpretable machine learning model using routine clinical data for early recurrence prediction in hepatocellular carcinoma. Sci Rep 16, 7520 (2026). https://doi.org/10.1038/s41598-026-38484-w
Palabras clave: recurrencia del cáncer de hígado, modelo de aprendizaje automático, predicción de riesgo clínico, IA interpretable, carcinoma hepatocelular