Clear Sky Science · es
Un modelo híbrido explicable CNN–transformer para el reconocimiento de lengua de signos en dispositivos edge mediante fusión adaptativa y destilación de conocimiento
Por qué importan las herramientas pequeñas para la lengua de signos
Miles de millones de conversaciones diarias dependen de movimientos de manos, expresiones faciales y lenguaje corporal en lugar de palabras habladas. Aun así, la mayoría de teléfonos, tabletas y dispositivos públicos siguen sin poder entender las lenguas de signos, especialmente fuera de los países anglófonos. Este artículo presenta TinyMSLR, un sistema compacto y explicable de reconocimiento de lengua de signos diseñado para ejecutarse en tiempo real en dispositivos pequeños y de bajo consumo. Su objetivo es convertir hardware común en ayudas comunicativas asequibles y fiables para personas sordas o con discapacidad auditiva en todo el mundo.
Incluir más lenguas en la conversación
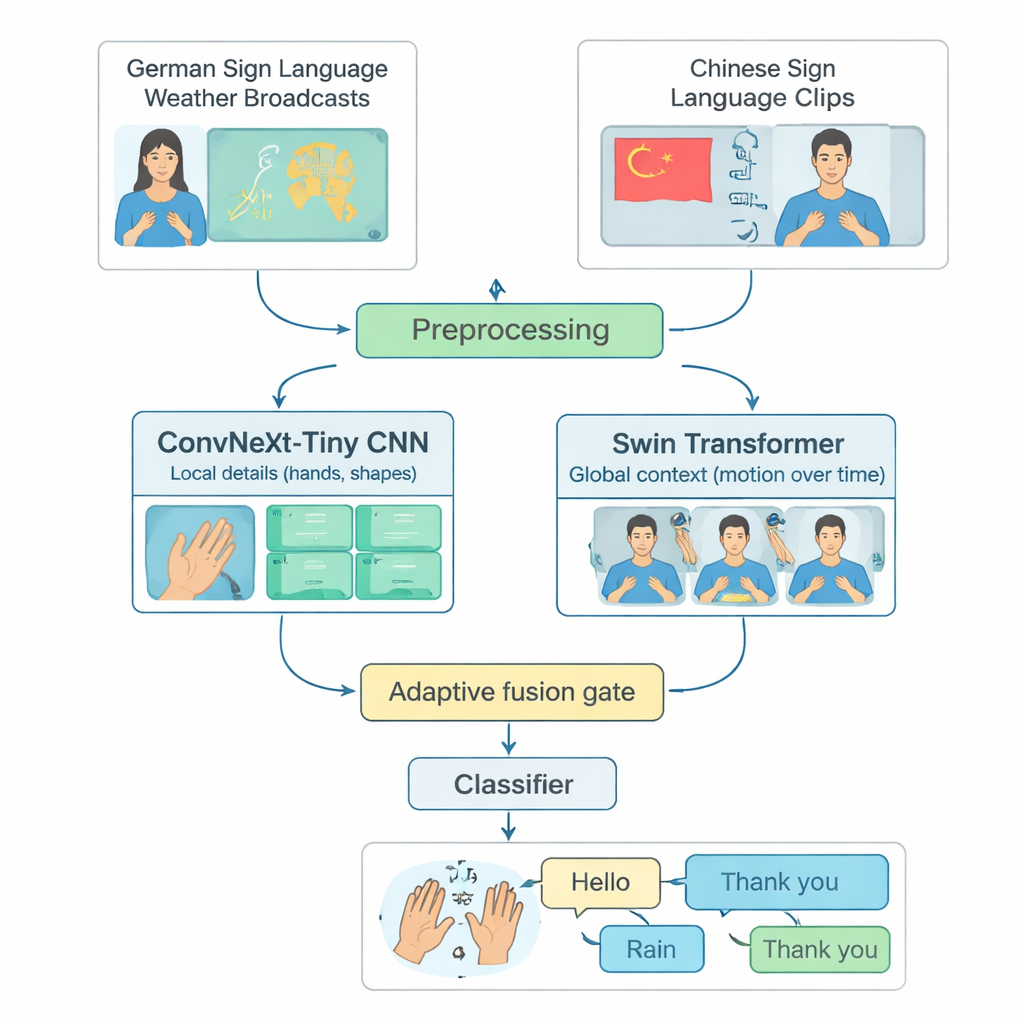
Muchos sistemas avanzados de reconocimiento de lengua de signos se centran en una sola lengua, con mayor frecuencia la American Sign Language, y funcionan únicamente en ordenadores potentes. Eso excluye a personas que usan otras lenguas de signos o que viven en regiones con recursos informáticos limitados. Los autores abordan esta brecha construyendo un banco de pruebas compartido a partir de dos lenguas distintas: emisiones meteorológicas en Lengua de Signos Alemana y una amplia colección de Lengua de Signos China. Seleccionan cuidadosamente 20 signos cotidianos comunes —como Hola, Tiempo, Lluvia, Feliz, Sí y Gracias— que existen en ambas lenguas. Al recortar vídeos largos en clips cortos que contienen un solo signo y equilibrar el número de ejemplos por clase y por intérprete, crean una forma justa y reproducible de evaluar qué tan bien un modelo puede reconocer signos aislados entre lenguas.
Cómo el modelo híbrido ve las manos y el movimiento
TinyMSLR combina dos formas complementarias de analizar vídeo. Una rama usa una red convolucional moderna (ConvNeXt‑Tiny) que destaca al detectar detalles finos, como la forma de los dedos y texturas sutiles. La segunda rama utiliza un Swin Transformer, una familia de modelos más reciente que sobresale al rastrear patrones en el espacio y el tiempo—cómo se mueven las manos, la cara y la parte superior del cuerpo a lo largo de varios fotogramas. Cada clip corto de vídeo se estandariza a 32 fotogramas de 224×224 píxeles, se aumenta suavemente (por ejemplo, pequeñas rotaciones o cambios de brillo) y luego se alimenta en paralelo a ambas ramas. Cada rama produce un resumen de 768 números de lo que observa; juntas, esas dos representaciones capturan tanto detalles locales nítidos como movimiento y contexto más amplios.
Dejar que el modelo decida qué importa más
Dado que algunos signos se distinguen principalmente por la forma de la mano mientras que otros dependen de movimientos amplios del brazo o de señales faciales, TinyMSLR no fija una sola receta para combinar sus dos perspectivas. En su lugar, utiliza una pequeña «puerta de fusión» que aprende, para cada clip de entrada, cuánto confiar en la rama enfocada en el detalle frente a la rama centrada en el contexto. La puerta examina ambos resúmenes de características y genera dos pesos que siempre suman uno; la representación final es una mezcla ponderada de las dos. Durante el entrenamiento, cada rama también recibe su propio pequeño clasificador para que aprenda a ser útil por sí misma, y un par de redes «maestras» más grandes (una CNN, un Transformer) guían suavemente al modelo pequeño mostrando no solo la etiqueta correcta sino también qué etiquetas alternativas se parecen. Esta técnica, llamada destilación de conocimiento, ayuda al sistema compacto a acercarse a la precisión de modelos más pesados manteniendo su tamaño y velocidad adecuados para dispositivos edge.
Ver por qué el sistema toma cada decisión
Más allá de la precisión bruta, los autores subrayan que usuarios y desarrolladores deberían poder inspeccionar en qué presta atención el modelo. Adoptan SHAP, una familia de herramientas que asigna un valor de importancia a cada parte de la entrada. En la práctica calculan estas explicaciones sobre características intermedias y las proyectan de nuevo sobre los fotogramas como mapas de calor y gráficos temporales. Esto revela, por ejemplo, qué fotogramas y regiones impulsan la decisión entre signos visualmente similares como Lluvia y Nieve o Frío y Malo. Agregar muchas explicaciones muestra patrones más amplios: las señales no manuales como la expresión facial y el movimiento de la cabeza, así como la orientación de la muñeca y la forma de la mano, emergen como especialmente influyentes. Estos conocimientos ayudan a verificar que el sistema se apoya en aspectos significativos de la comunicación en lugar de en artefactos de fondo.

Velocidad, eficiencia y margen de mejora
En el banco de pruebas bilingüe de 20 signos, TinyMSLR alcanza alrededor de un 99% de precisión en entrenamiento y validación y una puntuación F1 cercana al 99%, empleando menos de 2,7 millones de parámetros y aproximadamente 1,9 mil millones de operaciones por clip. En una GPU moderna procesa un signo en unos 13,5 milisegundos y consume menos de 30 milijulios de energía; el modelo almacenado ocupa solo unos 7,2 megabytes. Estas cifras sugieren que el reconocimiento de signos en tiempo real y en el dispositivo es factible en placas de bajo coste y sistemas embebidos. Los autores señalan con cuidado que su trabajo cubre solo signos cortos y aislados y dos lenguas, y trata las expresiones faciales de forma implícita en lugar de como una señal separada. Ampliar el enfoque a vocabularios más ricos, frases continuas, más lenguas y modelado explícito de movimientos faciales y de cabeza queda para trabajos futuros. Aun así, TinyMSLR ofrece una prueba de concepto convincente: herramientas precisas, eficientes e interpretables para entender las lenguas de signos no tienen por qué limitarse a la nube—pueden residir directamente en los dispositivos cotidianos.
Cita: Lamaakal, I., Yahyati, C., Maleh, Y. et al. An explainable hybrid CNN–transformer model for sign language recognition on edge devices using adaptive fusion and knowledge distillation. Sci Rep 16, 7143 (2026). https://doi.org/10.1038/s41598-026-38478-8
Palabras clave: reconocimiento de lengua de signos, tiny machine learning, edge AI, IA explicable, modelos multilingües