Clear Sky Science · es
SAT: transformador de alineación por desplazamiento para la denoising de vídeo sin estimación de flujo
Vídeos más nítidos a partir de escenas ruidosas
Cualquiera que haya intentado grabar en interiores por la noche o con un teléfono con poca luz conoce el resultado: vídeo granuloso y parpadeante donde los detalles parecen arrastrarse y los colores se ven mal. Este artículo presenta una nueva manera de limpiar ese tipo de vídeos, transformándolos en secuencias más claras y estables sin apoyarse en el costoso software de seguimiento de movimiento que habitualmente lo hace posible. El método, llamado Shift Alignment Transformer, está diseñado para conservar los detalles finos a la vez que sigue siendo lo suficientemente eficiente como para ser práctico.
Por qué limpiar vídeo es tan difícil
Eliminar el ruido de una sola fotografía ya es un reto; hacerlo en vídeo es aún más complicado. Por un lado, cada fotograma está corrompido por motas aleatorias y cambios de color. Por otro, los fotogramas están vinculados en el tiempo: los objetos se mueven, la cámara tiembla y los detalles aparecen y desaparecen. Los métodos de reducción de ruido para vídeo tradicionales se han apoyado en estimar el movimiento entre fotogramas, a menudo mediante una herramienta llamada flujo óptico, que intenta seguir dónde se mueve cada píxel de un fotograma al siguiente. Aunque potente, esa estimación de movimiento puede fallar con facilidad cuando el vídeo es extremadamente ruidoso o el movimiento es rápido y complejo, y además añade una gran carga computacional que puede ralentizar mucho los sistemas.
Una nueva forma de alinear sin seguimiento
En lugar de intentar seguir explícitamente cada píxel, el Shift Alignment Transformer (SAT) toma una ruta diferente: permite que la red descubra implícitamente cómo se relacionan los fotogramas mediante desplazamientos y comparaciones cuidadosas de características. El modelo se construye alrededor de una arquitectura moderna conocida como Transformer, que sobresale encontrando conexiones de largo alcance en los datos. Dentro de este marco, los autores introducen un Módulo de Desplazamiento Espacio-Temporal que baraja suavemente la información a través del tiempo y el espacio. En el tiempo, el modelo desplaza cíclicamente las características de los fotogramas para que, capa a capa, cada fotograma pueda “ver” más hacia el pasado y el futuro. En el espacio, divide las características en muchos grupos pequeños y empuja cada grupo en direcciones distintas. Esta combinación imita de forma efectiva cómo los objetos podrían moverse a través del vídeo, permitiendo que la red alinee información de distintos fotogramas sin calcular nunca un campo de movimiento explícito.
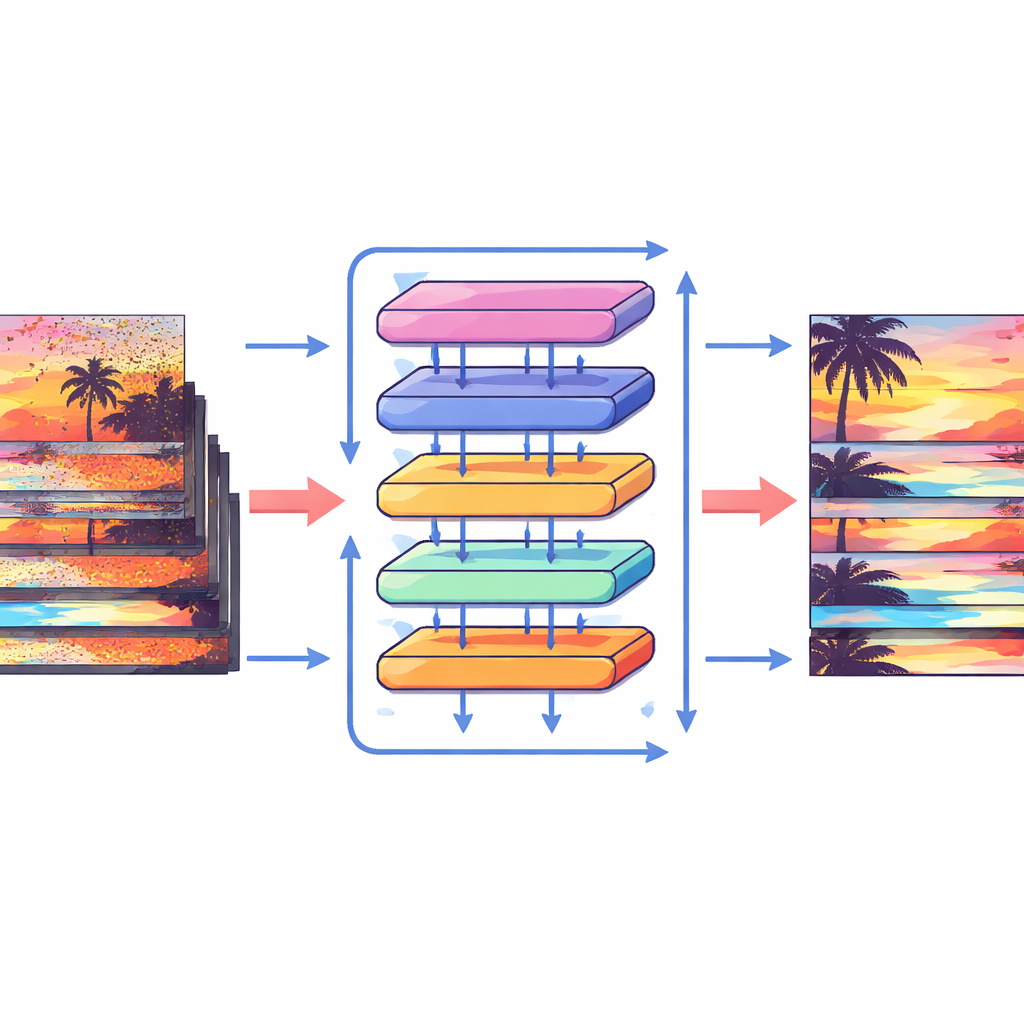
Cómo funcionan los nuevos componentes
Para aprovechar al máximo estos desplazamientos, los autores diseñan un bloque de atención especial que mezcla información dentro y entre fotogramas. Primero, las características desplazadas de fotogramas vecinos se reúnen y se comparan mediante una operación de atención cruzada: el modelo aprende qué regiones en otros fotogramas mejor respaldan al fotograma actual en cada ubicación. Al mismo tiempo, una operación de atención separada se centra en las relaciones dentro de cada fotograma individual, reforzando la estructura local y la textura. Estas dos corrientes se fusionan y pasan por capas de procesamiento sencillas en una red en forma de U multiescala, que va de resolución gruesa a fina y de vuelta. Esta disposición permite al sistema manejar tanto grandes movimientos de cámara como detalles minúsculos, como bordes finos o patrones pequeños, reconstruyendo gradualmente una versión limpia de cada fotograma.
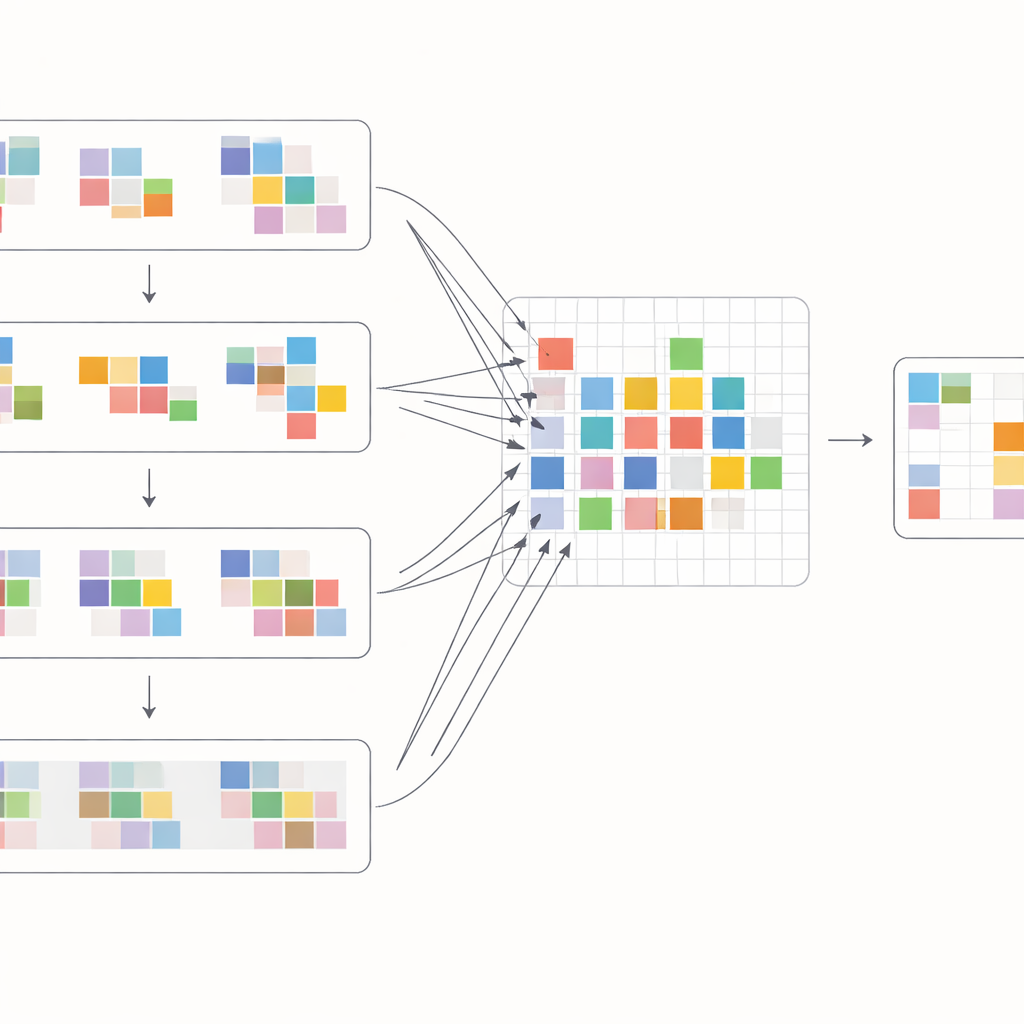
Qué tan bien funciona en la práctica
Los investigadores prueban su enfoque en dos bancos de pruebas exigentes. El primero implica vídeos limpios que se han corrompido artificialmente con diferentes niveles de ruido aleatorio, lo que les permite medir con precisión cuán fieles son los fotogramas restaurados respecto a los originales. Aquí, el nuevo método iguala o supera de forma consistente la calidad de redes convolucionales y recurrentes anteriores, y se aproxima a los mejores modelos basados en Transformers existentes usando menos cómputo. El segundo banco de pruebas utiliza metraje real capturado por sensores de imagen en condiciones de poca luz, donde el ruido es desigual, coloreado y mucho menos predecible. En esta prueba más realista, el Shift Alignment Transformer supera de manera decisiva a los métodos previos de última generación, produciendo vídeos que se ven más limpios, nítidos y estables en el tiempo, con menos cambios de color y menos artefactos residuales.
Qué significa esto para las herramientas de vídeo futuras
En términos sencillos, los autores demuestran que es posible denoising de vídeo de forma eficaz sin rastrear explícitamente el movimiento, combinando desplazamientos inteligentes en el tiempo y el espacio con correspondencia de características basada en atención. Su Shift Alignment Transformer ofrece un fuerte equilibrio entre precisión y eficiencia, especialmente para metraje real en condiciones de poca luz, donde la estimación de movimiento tradicional es frágil. A medida que los modelos basados en atención se vuelvan más eficientes, métodos como este podrían incorporarse a cámaras y servicios de streaming cotidianos, ayudando a convertir clips ruidosos y difíciles de ver en vídeos suaves y nítidos con un mínimo de complicaciones para el usuario.
Cita: Zhang, X., Fan, S., Zhang, H. et al. SAT: shift alignment transformer for video denoising without flow estimation. Sci Rep 16, 8207 (2026). https://doi.org/10.1038/s41598-026-38431-9
Palabras clave: reducción de ruido en vídeo, transformador, ruido en imagen, vídeo con poca luz, visión por ordenador