Clear Sky Science · es
Ataque adversario basado en decisiones eficiente en consultas con bajo presupuesto de consultas
Por qué pequeños fallos en imágenes pueden engañar a máquinas inteligentes
La inteligencia artificial moderna puede detectar rostros, animales y objetos cotidianos con una precisión impresionante. Sin embargo, estos mismos sistemas pueden ser engañados por cambios en una imagen tan pequeños que las personas apenas los perciben. Este artículo explora una nueva forma de crear imágenes «engañosas» mientras se interroga a la IA con el menor número posible de consultas, revelando tanto lo frágiles que pueden ser los modelos actuales como cómo los atacantes podrían explotarlos en el mundo real.
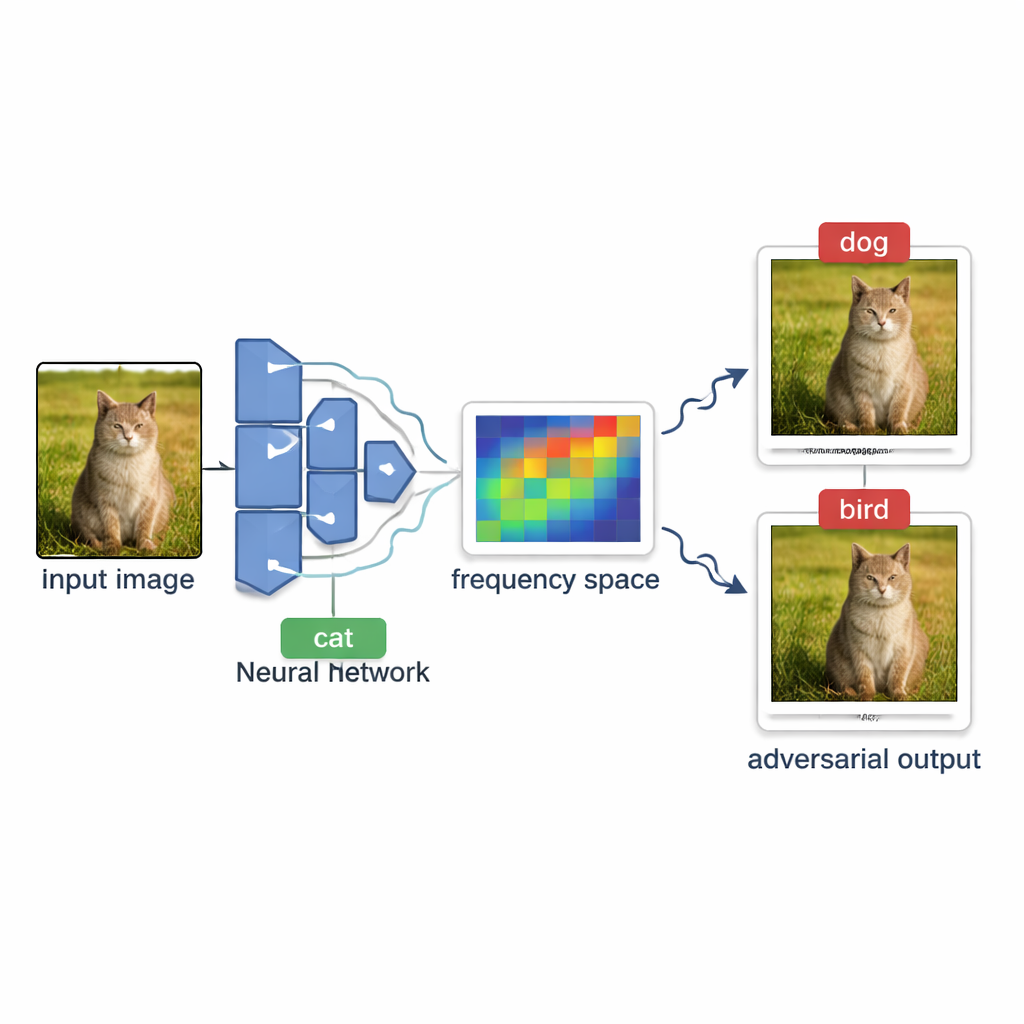
Cómo los atacantes sondean los sistemas de IA desde fuera
En muchos servicios reales—como el etiquetado de fotos en línea o los filtros de contenido—el modelo actúa como una caja negra. Personas externas pueden subir una imagen y ver solo la etiqueta final, como «perro» o «señal de stop», pero nunca las puntuaciones internas de confianza ni la estructura del modelo. Crear una imagen engañosa en estas condiciones se denomina ataque de caja negra basado en decisiones. El reto es empujar suavemente una imagen normal hasta que el modelo la clasifique mal, sin poder ver qué tan «cerca» está de cambiar de opinión y sin enviar tantas imágenes de prueba que el sistema lo detecte o que las consultas se vuelvan demasiado costosas.
Una nueva forma de buscar con muy pocas preguntas
Los autores presentan OPOQA (One Plane One Query Attack), un método diseñado para economizar consultas a la vez que genera imágenes adversarias de alta calidad. En lugar de sondear repetidamente a lo largo de una única dirección estimada, OPOQA trabaja en rondas. En cada ronda parte de una imagen ya engañosa y de la imagen limpia original, y luego propone varios nuevos candidatos que se sitúan en direcciones cuidadosamente elegidas. Crucialmente, cada dirección se sondea como máximo una vez, lo que libera el limitado presupuesto de consultas para explorar muchas más posibilidades en lugar de refinar en exceso una sola conjetura.
Navegando las ondas suaves en una imagen
Para elegir direcciones prometedoras, OPOQA se apoya en la idea de que los cambios más eficaces y difíciles de ver suelen ser suaves y amplios, en lugar de ruido agudo a nivel de píxel. El método utiliza una herramienta matemática llamada transformada discreta del coseno para mover la imagen a una vista de «frecuencia», donde las variaciones lentas y suaves se concentran en una región compacta. Muestrea aleatoriamente algunos de estos componentes de baja frecuencia, los convierte de nuevo en cambios de píxeles normales y los usa como direcciones básicas para la exploración. Cada dirección muestreada ayuda a definir una superficie plana bidimensional que conecta la imagen original, la imagen adversaria actual y un nuevo candidato. En cada una de estas superficies, OPOQA selecciona un único punto para probar, equilibrando dos objetivos: acercarse a la imagen original mientras sigue teniendo probabilidad de inducir al modelo a una decisión errónea.

Elegir el mejor candidato y adaptarse sobre la marcha
Una vez que OPOQA ha generado un pequeño conjunto de imágenes candidatas, mide cuánto se aleja cada una de la imagen original y las ordena de menos a más cambiadas. Luego consulta el modelo en ese orden. En el momento en que encuentra un candidato que el modelo clasifica mal, se detiene y trata esa imagen como el nuevo punto de partida para la siguiente ronda. Si ninguno de los candidatos logra engañar al modelo, OPOQA conserva la mejor imagen adversaria previa pero ajusta un control interno que regula cuán conservadores o agresivos serán los siguientes pasos. Esta estrategia «codiciosa»—aceptar siempre la mejor imagen mal clasificada disponible y ajustar dinámicamente el tamaño del paso—permite al ataque centrarse en perturbaciones sutiles y efectivas sin malgastar consultas en direcciones poco prometedoras.
Qué revelan los experimentos sobre los puntos débiles de la IA
Los investigadores probaron OPOQA en 200 imágenes del gran conjunto de referencia ImageNet y en seis modelos neuronales ampliamente usados, incluidos Inception-v3, ResNet, VGG, DenseNet y transformadores de visión. Bajo un límite estricto de 1.000 consultas al modelo por imagen, OPOQA igualó o superó a varios métodos de ataque líderes. Por ejemplo, en Inception-v3 consiguió engañar al modelo en el 94 por ciento de las imágenes manteniendo cambios tan pequeños que eran casi invisibles al ojo humano, mejorando varios puntos porcentuales sobre el mejor método previo. A través de los modelos, OPOQA tendió a alcanzar altas tasas de éxito antes—usando menos consultas—aunque algunos métodos competidores lo igualaron o superaron cuando se les dio presupuestos de consultas muy grandes y tiempo para ajuste fino.
Qué significa esto para la seguridad cotidiana de la IA
El estudio demuestra que los sistemas de visión actuales pueden ser engañados incluso cuando los atacantes solo ven decisiones finales y tienen oportunidades limitadas para sondear el modelo. Al explorar inteligentemente cambios suaves y de baja frecuencia y racionar con cuidado cada consulta, OPOQA puede crear imágenes que a las personas les parecen iguales pero que llevan a las máquinas por mal camino. Para el público general, la conclusión es que la «visión» de la IA sigue siendo bastante frágil: puede desviarse de su rumbo por medios sutiles y difíciles de notar. Reconocer y estudiar estos ataques eficientes es un paso clave para reforzar sistemas del mundo real—como cámaras de seguridad, herramientas de imágenes médicas y vehículos autónomos—contra manipulaciones que de otro modo podrían pasar desapercibidas.
Cita: Tuo, Y., Yin, M. & Che, S. Query-efficient decision-based adversarial attack with low query budget. Sci Rep 16, 6886 (2026). https://doi.org/10.1038/s41598-026-38428-4
Palabras clave: ejemplos adversarios, ataques de caja negra, seguridad en aprendizaje profundo, clasificación de imágenes, ataque eficiente en consultas