Clear Sky Science · es
Evaluación de la susceptibilidad a inundaciones usando tres técnicas de aprendizaje automático y comparación de su rendimiento
Por qué importa el riesgo de inundación en una cuenca etíope
Las inundaciones causan miles de muertes en todo el mundo cada año, arrasan cultivos y dañan viviendas y carreteras. En la cuenca Choke de Etiopía, una región de tierras altas que alimenta el Nilo Azul, las inundaciones repentinas llegan con rapidez y a menudo sin advertencia. Este estudio muestra cómo las técnicas informáticas modernas pueden transformar imágenes satelitales, mapas y registros de precipitación en mapas detallados de riesgo de inundación, ayudando a comunidades y planificadores a decidir dónde construir, dónde cultivar y dónde proteger a las personas antes de que llegue la próxima tormenta.

Un paisaje montañoso bajo presión
La cuenca Choke se sitúa en las tierras altas del noroeste de Etiopía, donde montañas escarpadas dan origen a más de 60 ríos y cientos de manantiales. Este terreno accidentado sostiene la agricultura, la energía hidroeléctrica, el abastecimiento de agua potable e incluso el turismo, pero también canaliza las fuertes lluvias estacionales hacia valles y llanuras aluviales estrechas. En la última década, inundaciones recurrentes han dañado campos, carreteras, puentes, escuelas y viviendas, especialmente durante la principal estación de lluvias de junio a septiembre. El crecimiento poblacional, la deforestación y la expansión urbana han alterado la superficie terrestre, haciendo a menudo que absorba menos agua y que sea más propensa a transportar repentinos incrementos de escorrentía río abajo.
Convertir mapas y mediciones en un historial de inundaciones
Para entender dónde ocurren las inundaciones con más frecuencia, los investigadores primero construyeron un “inventario” de inundaciones para la cuenca. Combinaron informes oficiales de desastres, información de campo e imágenes radar del satélite Sentinel-1, que puede detectar áreas inundadas incluso a través de las nubes. Para cinco años de inundaciones importantes entre 2005 y 2020, compararon imágenes tomadas antes y después de los eventos para localizar zonas inundadas. También usaron datos de elevación para eliminar lagos permanentes y pendientes pronunciadas que no albergarían agua estancada. A partir de esto, ensamblaron un conjunto equilibrado de ubicaciones que habían sufrido inundaciones y otras que se habían mantenido secas, formando el material de aprendizaje para sus modelos informáticos.
Leer el terreno para predecir futuras inundaciones
A continuación, el equipo recopiló once tipos de información que influyen en dónde se acumula el agua, incluyendo altitud, pendiente, curvatura de las laderas, tendencias de humedad del suelo, redes fluviales, distancia a los cauces, precipitación, tipo de suelo y uso del suelo. Todo ello se procesó en capas cartográficas coincidentes dentro de un sistema de información geográfica. Los modelos se entrenaron para identificar patrones que vinculan esas capas con inundaciones pasadas. En las distintas pruebas, tres variables destacaron como especialmente importantes: elevación, pendiente y un índice de humedad que refleja la facilidad con la que el agua se acumula en ciertos puntos. Las áreas bajas con pendientes suaves y valores altos de humedad emergieron como focos claros de inundación, mientras que la orientación de la pendiente (a qué dirección mira) e incluso la variabilidad de la precipitación tuvieron menos peso en este entorno montañoso particular.
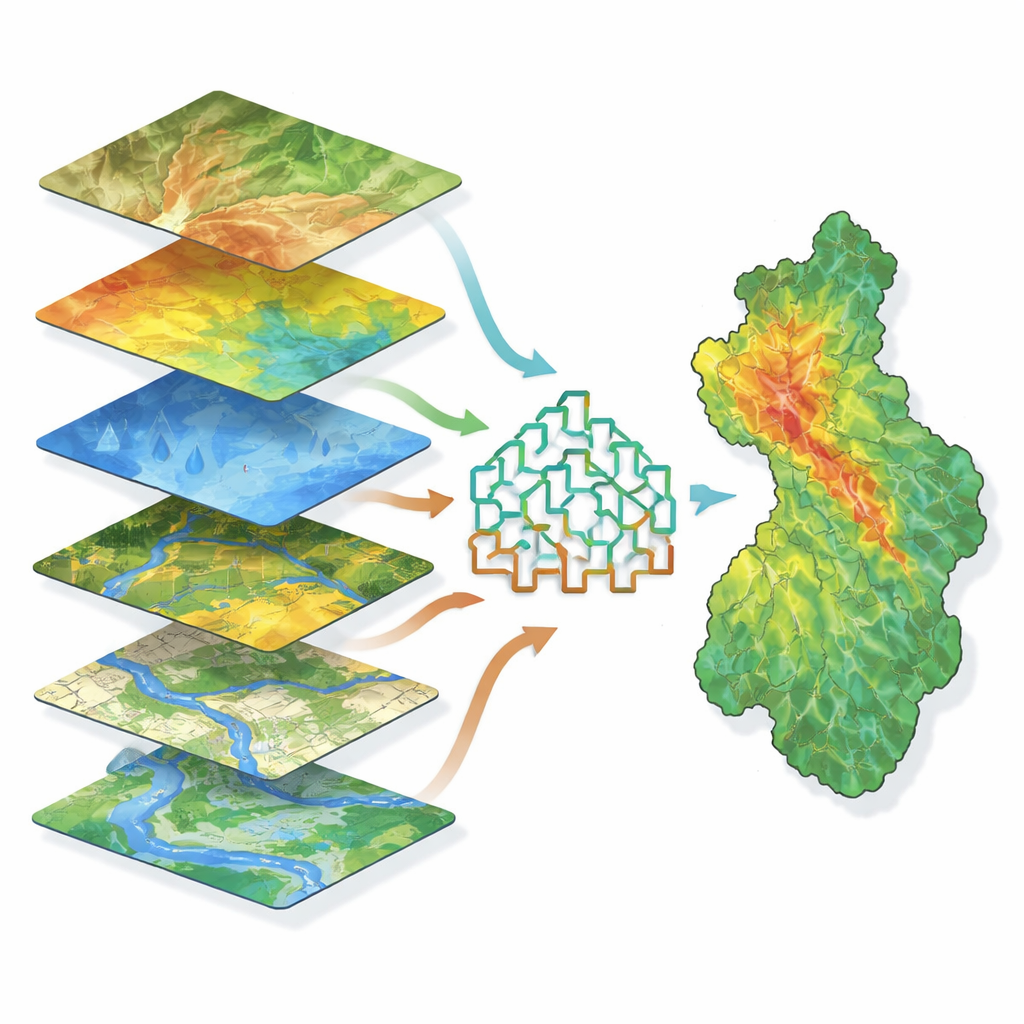
Enseñar a las máquinas a identificar zonas de alto riesgo
El estudio comparó tres métodos avanzados de aprendizaje automático que se basan en muchos árboles de decisión trabajando en conjunto: Random Forest, Gradient Boosting y Extreme Gradient Boosting. Estos enfoques son eficaces para manejar relaciones complejas entre muchos factores sin necesitar datos perfectos ni fórmulas sencillas. Tras dividir sus datos en conjuntos de entrenamiento y prueba, los autores ajustaron cada modelo y comprobaron su rendimiento usando varias métricas estadísticas. Dos de los métodos, Gradient Boosting y Extreme Gradient Boosting, resultaron especialmente precisos, distinguiendo correctamente puntos inundados de no inundados en alrededor del 97 por ciento de los casos; Random Forest quedó muy cerca. Los tres generaron mapas de susceptibilidad a inundaciones que dividían la cuenca en cinco clases, desde muy baja hasta muy alta probabilidad, con las secciones norte y suroeste mostrando el mayor peligro.
De los mapas computacionales a comunidades más seguras
Para el público no especializado, el resultado clave es que estos mapas generados por máquinas convierten registros dispersos e imágenes satelitales en una imagen clara de dónde es más probable que se extiendan las aguas de inundación. Solo una fracción modesta de la cuenca Choke cae en las zonas de mayor riesgo, pero esos bolsillos coinciden con tierras bajas pobladas y zonas agrícolas importantes. Las autoridades locales pueden usar los resultados para orientar la ubicación de nuevas viviendas, reforzar puentes y drenajes o restaurar la vegetación para ralentizar la escorrentía. Aunque los modelos no pueden reemplazar simulaciones hidráulicas detalladas, ofrecen una forma rápida y rentable de enfocar recursos limitados en las áreas más vulnerables y podrían adaptarse a otros riesgos, como deslizamientos de tierra o sismos. En un país donde los datos y los presupuestos a menudo escasean, esta combinación de satélites y algoritmos inteligentes ofrece un camino práctico hacia paisajes y comunidades más resilientes.
Cita: Asrade, T., Abebe, S., Tadesse, K. et al. Flood susceptibility assessment using three machine learning techniques and comparison of their performance. Sci Rep 16, 8099 (2026). https://doi.org/10.1038/s41598-026-38391-0
Palabras clave: susceptibilidad a inundaciones, aprendizaje automático, cuenca Choke, teledetección, reducción del riesgo de desastres