Clear Sky Science · es
MDI-YOLO: un modelo ligero de fusión de características multidimensionales basado en transformador‑CNN para la detección de objetos pequeños
Ojos más agudos en el cielo
Desde la vigilancia del tráfico hasta la respuesta ante desastres, drones y satélites vigilan cada vez más nuestro mundo. Sin embargo, lo que más nos interesa en estas imágenes —coches diminutos, personas, embarcaciones y aeronaves— a menudo aparece como apenas unos pocos píxeles. El artículo sobre MDI‑YOLO aborda una cuestión sencilla pero crucial: ¿cómo pueden los ordenadores detectar con fiabilidad estos objetos minúsculos en tiempo real, incluso en dispositivos de baja potencia que llevan los propios drones?
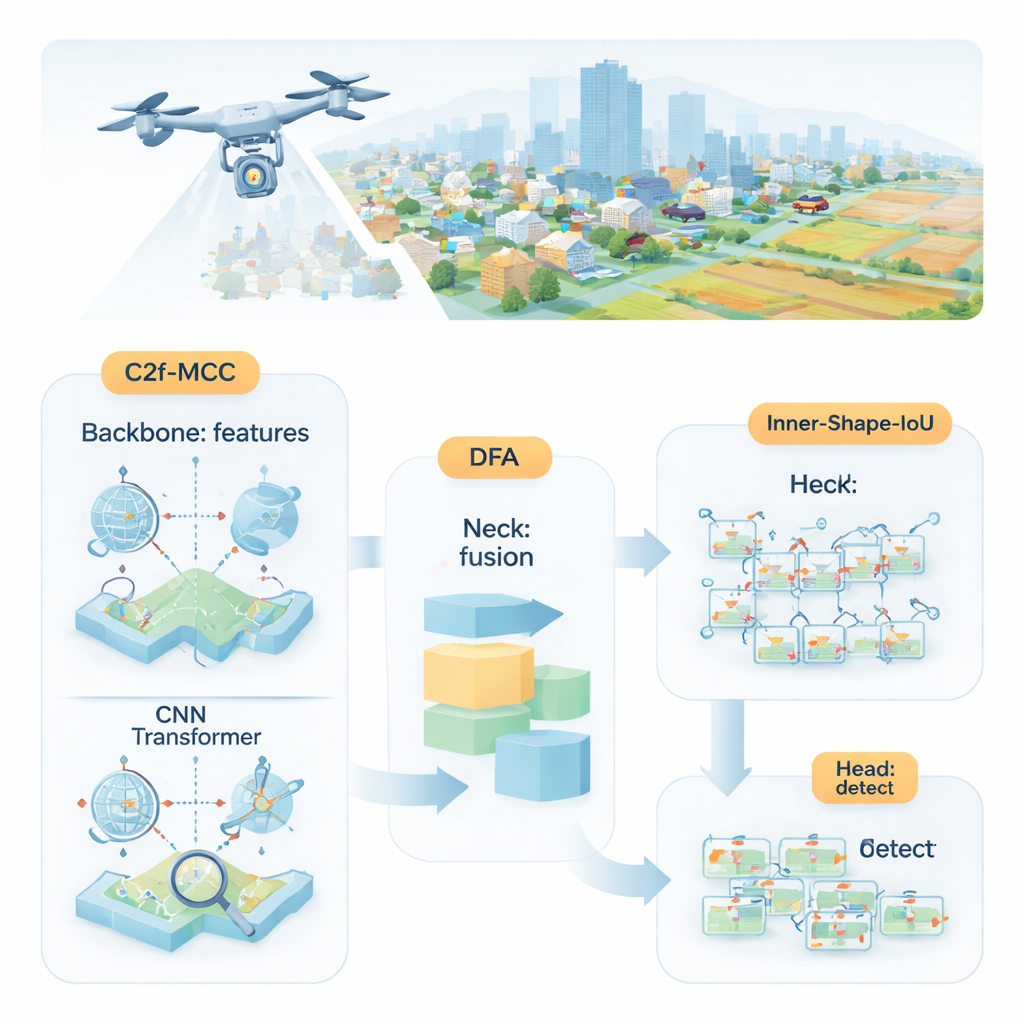
Por qué es difícil detectar objetos pequeños
En vistas aéreas y satelitales, los objetos de interés suelen ser muy pequeños, a menudo están muy juntos y pueden quedar parcialmente ocultos por edificios, árboles o sombras. Los sistemas de detección estándar afrontan un compromiso: los modelos ligeros se ejecutan con rapidez en dispositivos de borde como los ordenadores a bordo de drones pero fallan en muchos blancos pequeños; los modelos más pesados y precisos son demasiado lentos y demandan demasiados recursos para ser prácticos en el terreno. Además, los objetos pequeños tienden a fundirse con fondos complejos —piense en coches grises sobre carreteras grises— de modo que sus rasgos distintivos pueden desaparecer fácilmente cuando las imágenes se comprimen y se procesan mediante redes profundas.
Una nueva mezcla de visión global y local
Los investigadores proponen MDI‑YOLO, una versión rediseñada del popular detector YOLOv8 que mantiene el modelo compacto a la vez que afina su capacidad para encontrar objetivos diminutos. En su núcleo hay un nuevo bloque constructivo llamado C2f‑MCC, que divide la información visual que atraviesa la red en dos vías. Una vía usa procesamiento al estilo Transformer, que es bueno captando relaciones a larga distancia en toda la imagen —por ejemplo, cómo un grupo de píxeles encaja en una carretera o pista más amplia. La otra vía conserva los filtros convolucionales clásicos, que sobresalen en detectar detalles locales como bordes y texturas. Al agrupar canales y enviar solo una parte de los datos por la vía Transformer más costosa, el modelo gana conciencia global sin aumentar mucho su tamaño ni ralentizarse.
Ayudando a la red a centrarse en lo importante
Incluso con mejores bloques constructivos, la red aún necesita decidir dónde prestar atención. Para guiar esto, los autores introducen un mecanismo que llaman Atención de Fusión Direccional (DFA). Este módulo examina patrones a lo largo del ancho y la altura de la imagen, además de un resumen global de la escena, y aprende a ponderar diferentes regiones y canales de características. En la práctica, DFA anima al modelo a concentrarse en áreas probables de objetos —como manchas con forma de vehículo en las carreteras— y a restar importancia a texturas de fondo repetitivas o confusas. Esta combinación de foco espacial y por canales facilita separar blancos diminutos del entorno enmarañado o de regiones de fondo de apariencia similar.
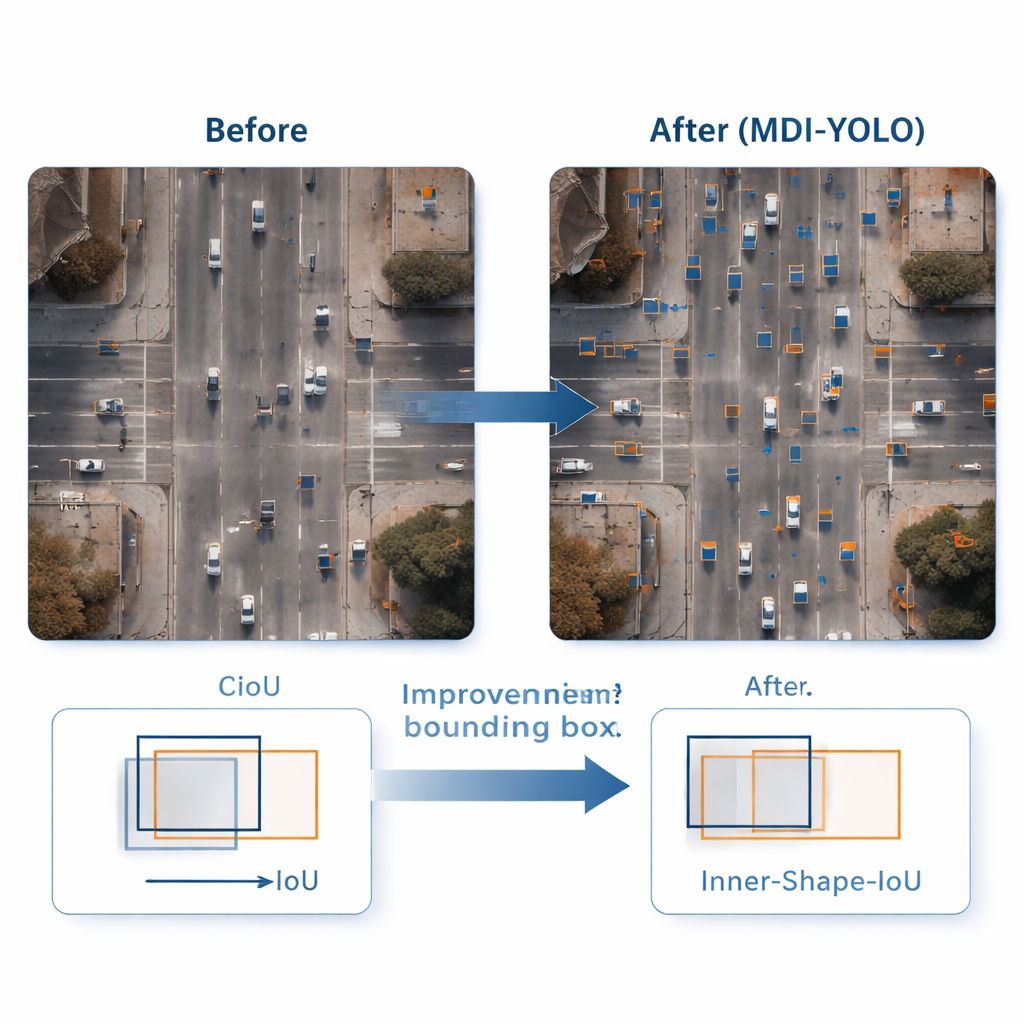
Trazando cajas más ajustadas alrededor de objetivos diminutos
Detectar un objeto es solo la mitad del trabajo; el detector también debe enmarcarlo con precisión. Los métodos de entrenamiento estándar comparan rectángulos predichos con los reales mediante una puntuación de "solapamiento", pero esto puede ser poco sensible cuando los objetos son pequeños o de forma extraña. Los autores diseñan una nueva función de pérdida, Inner‑Shape‑IoU, que evalúa las cajas no solo por cuánto se solapan, sino también por qué tan bien su forma, tamaño y región central coinciden con el objeto real. Al combinar dos medidas complementarias, penaliza cajas que solo coinciden en los bordes pero fallan en el núcleo del objetivo, lo que conduce a contornos más precisos —especialmente para objetos pequeños, densamente agrupados o alargados.
Mejoras demostradas sin peso adicional
Para evaluar MDI‑YOLO, el equipo realizó experimentos en dos difíciles bancos de prueba públicos: VisDrone2019, con grabaciones de drones en ciudades y tráfico, y DOTAv1.0, una gran colección de escenas aéreas con muchos objetos pequeños y densamente agrupados. Sin depender de modelos preentrenados, MDI‑YOLO mejoró las puntuaciones de precisión estándar en varios puntos porcentuales respecto al YOLOv8 base, manteniendo casi sin cambios el número de parámetros y conservando tiempos de inferencia rápidos. En comparación con una gama de detectores populares —desde variantes ligeras de YOLO hasta sistemas basados en Transformer más pesados— ofreció una combinación poco común de alta precisión, bajo coste computacional y robustez a través de distintas escenas.
Qué significa esto para el uso en el mundo real
Para el público general, la conclusión es que MDI‑YOLO proporciona a drones y sistemas de teledetección "ojos" más nítidos y fiables sin exigir ordenadores grandes y consumidores de energía. Al mezclar de manera inteligente contexto global, detalle local, atención dirigida y una forma más exigente de entrenar las cajas delimitadoras, el método facilita la detección de objetos diminutos que importan para la seguridad, la vigilancia y el mapeo. Este tipo de visión eficiente y de alta precisión es un paso clave hacia plataformas aéreas más inteligentes que puedan operar de forma autónoma, responder con rapidez y desplegarse ampliamente en el mundo real.
Cita: Shi, H., Wu, Y., Xu, Y. et al. MDI-YOLO a lightweight transformer-CNN-based multidimensional feature fusion model for small object detection. Sci Rep 16, 7233 (2026). https://doi.org/10.1038/s41598-026-38378-x
Palabras clave: imágenes con drones, detección de objetos pequeños, teledetección, YOLO, visión por computador