Clear Sky Science · es
Asignación de recursos asistida por gemelos digitales mediante aprendizaje por imitación adversarial generativo en escenarios complejos nube-borde-dispositivo
Autopistas de datos más inteligentes para el Internet de las Cosas
A medida que ciudades, fábricas y hogares se llenan de sensores y dispositivos conectados, generan torrentes de datos que deben procesarse con rapidez y fiabilidad. Enviar todo a servidores en la nube lejanos puede resultar demasiado lento, mientras que los pequeños dispositivos en el "borde" a menudo no disponen de suficiente potencia de cálculo. Este artículo explora una nueva manera de enrutar y asignar automáticamente recursos de computación, almacenamiento y red entre dispositivos, servidores de borde cercanos y la nube, de forma que las aplicaciones inteligentes sigan siendo rápidas y robustas incluso cuando las condiciones reales son desordenadas e impredecibles.
Por qué los métodos actuales tienen problemas
Los sistemas modernos suelen apoyarse en aprendizaje por refuerzo profundo, donde un algoritmo aprende por ensayo y error usando señales de recompensa del entorno. Sin embargo, en redes complejas y ruidosas, esas recompensas son difíciles de definir y medir. Si la función de recompensa es incorrecta o está distorsionada por interferencias, el sistema puede aprender comportamientos inseguros o derrochadores. Muchos métodos existentes también asumen un conocimiento previo abundante sobre patrones de tráfico y comportamiento de los dispositivos, que rara vez está disponible en redes industriales reales. Además, la mayoría de las soluciones optimizan un solo tipo de recurso a la vez —como la capacidad de cómputo— ignorando almacenamiento o ancho de banda de red, aun cuando los tres interactúan para determinar el rendimiento en el mundo real.
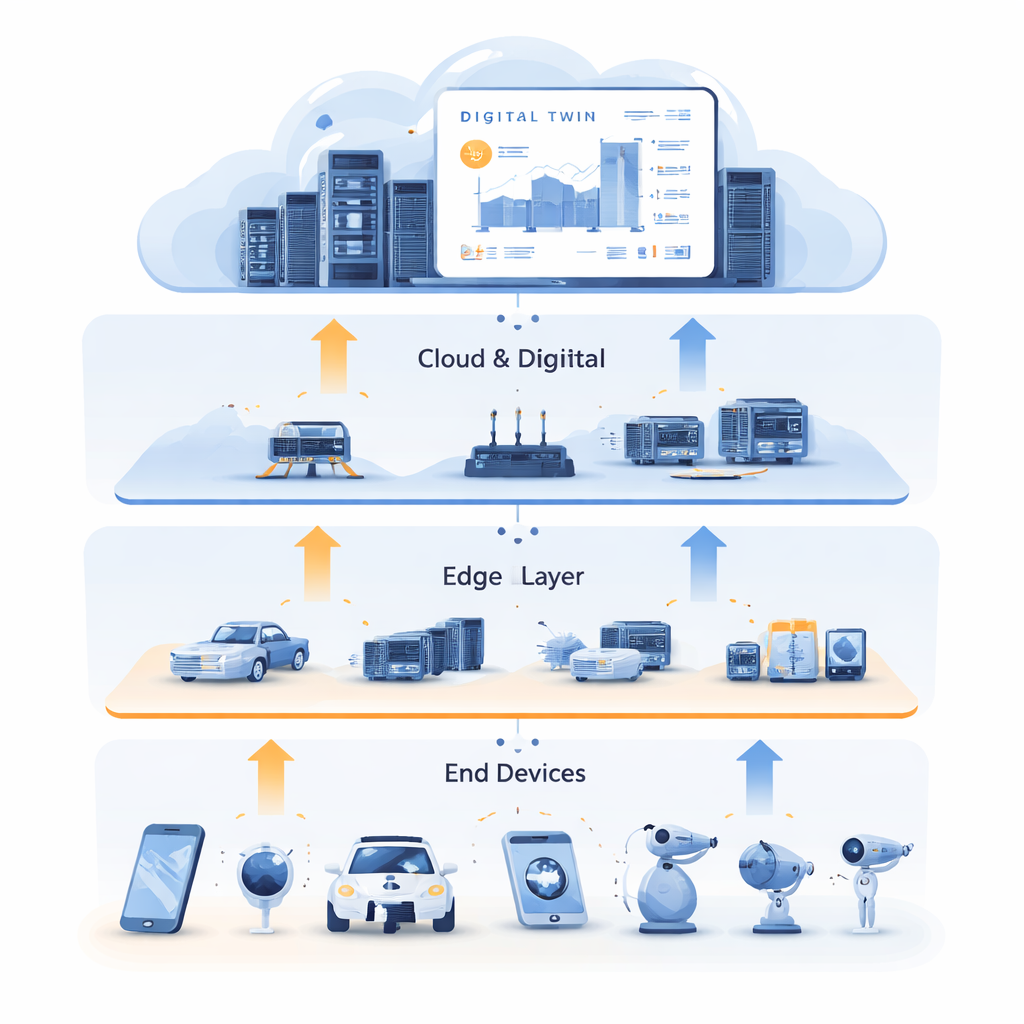
Aprender de un doble digital
Para romper este bloqueo, los autores combinan la asignación de recursos con la tecnología de Gemelo Digital. Un gemelo digital es una réplica virtual detallada de la red física, mantenida en la nube. Refleja el estado de servidores de borde, enlaces y tareas a lo largo del tiempo, usando abundantes datos históricos procedentes de sensores y registros. En este trabajo, el gemelo digital no es solo un panel de control; se convierte en un campo de entrenamiento. El sistema utiliza datos pasados para generar ejemplos "expertos" de buenas decisiones, capturando cómo deben repartirse las tareas entre cálculo y caché, y dónde deben procesarse para minimizar la latencia. Este entrenamiento se realiza fuera de línea, sin perturbar los servicios en vivo, y aprovecha la abundante capacidad de la nube para explorar muchas situaciones posibles.
Imitación en lugar de ensayo y error
En lugar de aprender directamente a partir de recompensas, el modelo propuesto E‑GAIL adopta el aprendizaje por imitación: el agente intenta comportarse como un experto. Primero, los autores construyen múltiples políticas expertas usando un marco Actor–Crítico mejorado con una capa NoisyNet. Inyectar ruido cuidadosamente controlado en la red de decisión permite a estos expertos experimentar una amplia variedad de condiciones —incluyendo perturbaciones que imitan la interferencia inalámbrica real y cargas de trabajo fluctuantes— de modo que sus trayectorias sean más realistas. A continuación, el sistema fusiona varias trayectorias de un solo experto en una referencia única "multi-experto" utilizando herramientas de la teoría de juegos. Buscando un equilibrio de Nash entre los expertos, se evitan los conflictos entre ellos y se produce una estrategia de consenso con mayor cobertura de escenarios posibles.
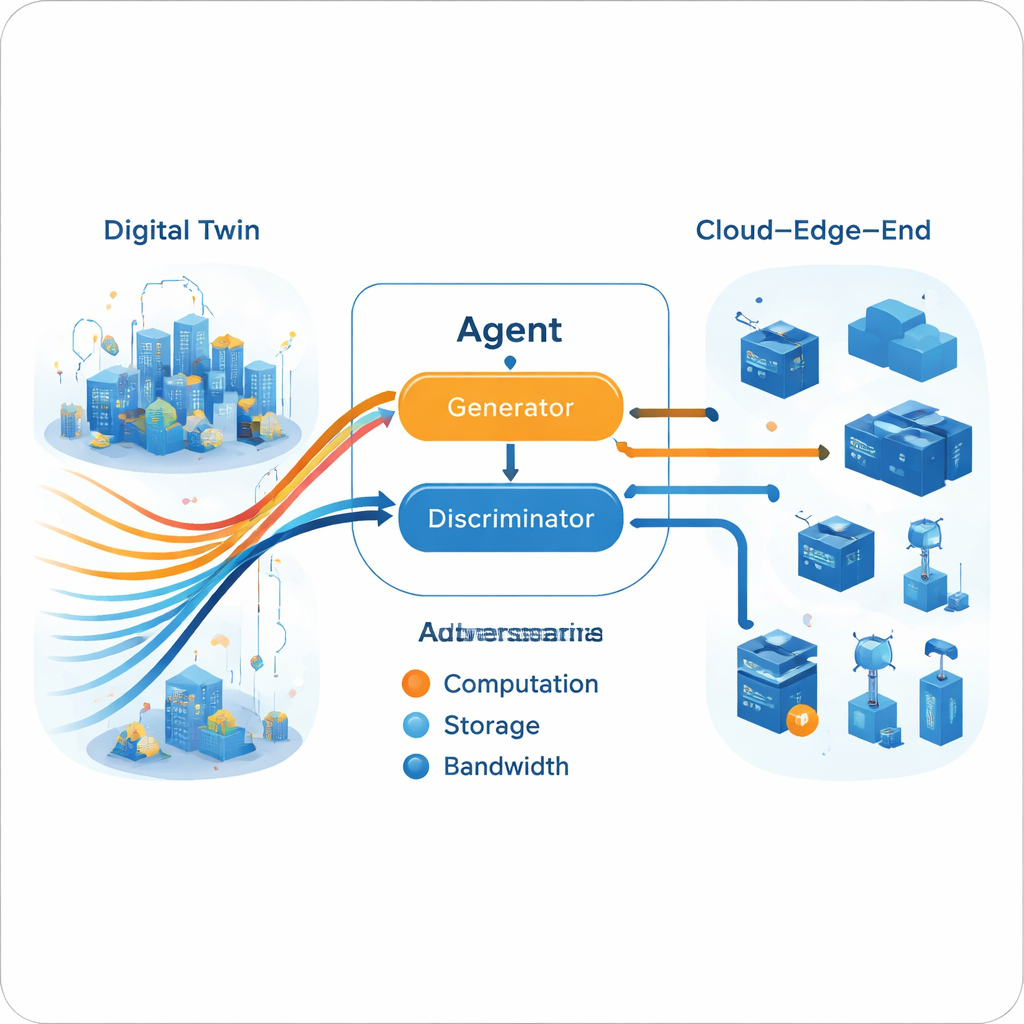
Un motor adversarial generativo para tomar decisiones
Una vez construida la trayectoria multi-experto en el gemelo digital, el agente en vivo aprende a imitarla usando un esquema adversarial generativo, similar en espíritu a las redes neuronales generadoras de imágenes. Un generador propone acciones de asignación de recursos dado el estado actual de la red, mientras que un discriminador trata de determinar si una secuencia de acciones proviene del agente o de las trayectorias expertas. Con el tiempo, este juego adversarial empuja al generador a producir decisiones que el discriminador no puede distinguir del comportamiento experto. Crucialmente, este proceso no requiere una función de recompensa explícita del entorno real. El entrenamiento se divide: un aprendizaje intensivo fuera de línea (en la nube) refina a los expertos y al generador, mientras que actualizaciones más ligeras en línea (en el borde) mantienen el modelo alineado con las condiciones actuales, respetando los límites prácticos del hardware de borde.
¿Qué tan bien funciona?
Los autores prueban E‑GAIL frente a varias líneas base populares, incluyendo deep Q‑learning, offloading con teoría de juegos, heurísticas codiciosas, procesamiento solo en la nube y asignación aleatoria. A lo largo de muchos experimentos —variando el número de dispositivos finales, canales, mezcla de tareas, cargas de trabajo, tamaños de datos, distancias y patrones de ruido— E‑GAIL obtiene de forma consistente retardos de extremo a extremo muy cercanos a los de la política experta y visiblemente mejores que otros métodos automáticos. Se adapta bien cuando las tareas cambian entre intensivas en cómputo y en almacenamiento, cuando la red crece o cuando la interferencia se intensifica. El gemelo digital acelera la generación de trayectorias expertas y mejora su calidad, mientras que la fusión multi-experto amplía los escenarios que el agente puede manejar sin necesidad de reentrenar desde cero.
Qué significa esto para sistemas cotidianos
Para un público no especialista, el mensaje clave es que este enfoque permite a las redes gestionarse con mayor inteligencia ante la incertidumbre. En lugar de diseñar reglas a mano o confiar en un aprendizaje por ensayo y error frágil, E‑GAIL aprende a partir de experiencia simulada rica provista por un gemelo digital y de varios “expertos” experimentados cuya asesoría se reconcilia matemáticamente. El resultado es un asignador de recursos que puede decidir con rapidez dónde ejecutar tareas y dónde almacenar datos, manteniendo tiempos de respuesta bajos incluso cuando cambian las condiciones. En futuros sistemas industriales y de ciudades inteligentes, tales coordinadores autodidactas podrían ocuparse discretamente de equilibrar cálculo, almacenamiento y ancho de banda tras bambalinas, haciendo nuestro mundo conectado más rápido, más fiable y más eficiente energéticamente.
Cita: Zhang, X., Xin, M., Li, Y. et al. DT-aided resource allocation via generative adversarial imitation learning in complex cloud-edge-end scenarios. Sci Rep 16, 7657 (2026). https://doi.org/10.1038/s41598-026-38367-0
Palabras clave: gemelo digital, computación en el borde, aprendizaje por imitación, asignación de recursos, Internet Industrial de las Cosas