Clear Sky Science · es
Un método de fusión de mejora de imágenes visibles e infrarrojas de extremo a extremo y multiescala
Visión nocturna más nítida para personas y máquinas
Cualquiera que haya intentado fotografiar de noche sabe lo rápido que la oscuridad destruye el detalle: las escenas parecen granuladas, borrosas y con colores extraños. Sin embargo, muchas tecnologías críticas —desde cámaras en carretera y seguridad doméstica hasta vehículos autónomos y drones de rescate— deben ver con claridad precisamente en estas condiciones. Este artículo presenta una nueva forma de combinar cámaras de color ordinarias con cámaras infrarrojas de “calor” para que los ordenadores, y finalmente las personas, obtengan vistas brillantes y detalladas del mundo incluso en la casi total oscuridad.
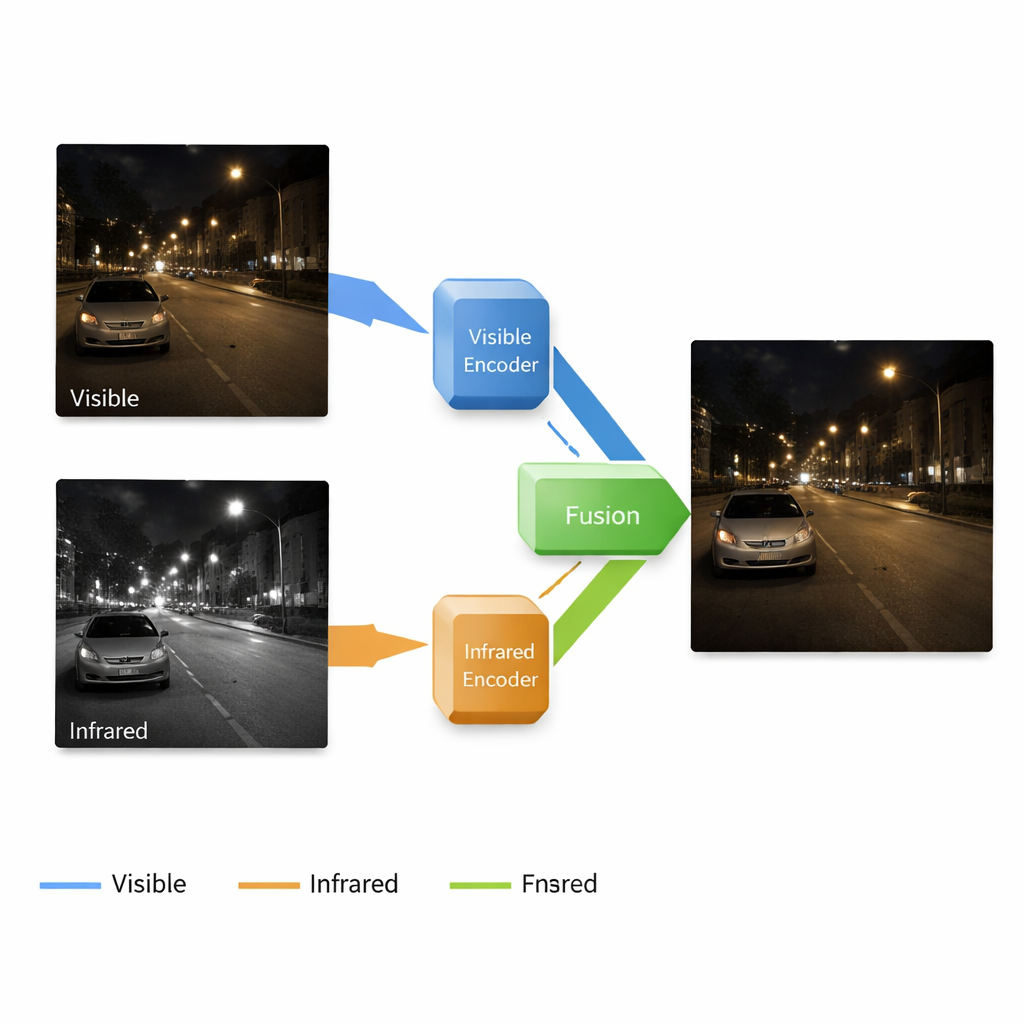
Por qué dos tipos de cámaras son mejores que una
Las cámaras estándar capturan el mismo tipo de luz que ven nuestros ojos, lo que hace que sus imágenes sean fáciles de interpretar para los humanos, pero fallan estrepitosamente cuando la luz escasea: las sombras engullen el detalle, aparece ruido y los colores se desplazan. Las cámaras infrarrojas hacen lo contrario: detectan patrones de calor, revelando personas, animales y vehículos en la oscuridad o a través de niebla ligera, pero sus imágenes carecen de texturas finas y de una apariencia natural. Los investigadores llevan tiempo intentando fusionar estas dos visiones en una sola imagen que parezca una foto en color nítida y, al mismo tiempo, revele objetos cálidos ocultos. Sin embargo, los métodos existentes suelen tratar cada paso —iluminar imágenes oscuras, limpiar el ruido y fusionar la información infrarroja— como tareas separadas. Ese enfoque por partes puede causar desajustes de características y resultados de fusión decepcionantes.
Una única tubería que ilumina y fusiona
Los autores proponen un sistema de extremo a extremo que mejora y fusiona imágenes en un único flujo continuo. Se construye alrededor de una red neuronal con cuatro partes principales: una rama aprende a limpiar e iluminar imágenes en color con poca luz, otra aprende a representar la escena desde la cámara infrarroja, un bloque de fusión combina lo aprendido por cada rama y un decodificador reconstruye una imagen final a partir de esas señales mezcladas. Es importante que el sistema opera a múltiples escalas, desde formas gruesas hasta texturas finas. Las capas poco profundas conservan bordes y detalles de superficie como ladrillos o marcas viales, mientras que las capas profundas capturan estructuras más amplias —edificios, coches o árboles— y la localización de objetivos calientes en la imagen infrarroja.
Tres fases de aprendizaje en lugar de un gran salto
En vez de entrenar todo el sistema de una vez, el equipo usa una estrategia de aprendizaje en tres etapas diseñada para estabilidad y precisión. En la primera fase, la red ve solo fotos oscuras en luz visible y aprende a iluminarlas sin referencias “perfectas” proporcionadas por humanos. Términos de pérdida cuidadosamente elegidos empujan la salida a tener brillo natural, colores estables, regiones uniformes sin ruido manchado y textura preservada. En la segunda fase, se reutiliza el mismo decodificador mientras una nueva rama infrarroja aprende a reconstruir fielmente las imágenes infrarrojas, enseñando a la red cómo deben verse los patrones de calor. En la tercera fase, todas esas piezas aprendidas se congelan y solo se entrena el bloque de fusión para combinar las dos representaciones en una sola imagen de alta calidad que sea a la vez brillante y rica en información.
Poniendo el método a prueba
Los investigadores evaluaron su enfoque en conjuntos de datos públicos que contenían pares de imágenes visibles e infrarrojas tomadas en condiciones de iluminación difíciles, como calles nocturnas. Compararon con varias técnicas de fusión líderes, incluidas las basadas en transformadas clásicas de imagen, redes convolucionales estándar y modelos generativos más complejos. Su método ofreció, en general, detalles más nítidos, un brillo más uniforme y objetivos térmicos más claros, además de puntuaciones superiores en medidas cuantitativas de contenido informativo, nitidez de bordes, similitud estructural y contraste. Experimentos adicionales, en los que retiraron selectivamente componentes clave del sistema, mostraron que cada parte —el bloque de fusión multiescala, el entrenamiento por etapas y el ponderado adaptativo de características visibles frente a infrarrojas— contribuye de forma mensurable a la calidad final.
Qué significa esto para los sistemas de visión del mundo real
Para los no especialistas, la conclusión es sencilla: este trabajo demuestra que una única red cuidadosamente entrenada puede tanto iluminar escenas oscuras como fusionar inteligentemente vistas de calor y color en una imagen coherente. Las imágenes fusionadas conservan texturas finas mientras resaltan objetos calientes, lo que las hace mucho más útiles para tareas como vigilancia nocturna, asistencia a la conducción y realidad aumentada o virtual en entornos con poca luz. Aunque los autores señalan algunos problemas pendientes —como la reducción de contraste en regiones muy brillantes y la necesidad de modelos más rápidos y ligeros—, su enfoque supone un avance significativo hacia sistemas de cámara que ven de forma fiable en la oscuridad, de un modo que resulta natural e interpretable para los usuarios humanos.
Cita: Xin, Y., Huang, J., Sun, C. et al. A multi-scale end-to-end visible and infrared image enhancement fusion method. Sci Rep 16, 7135 (2026). https://doi.org/10.1038/s41598-026-38323-y
Palabras clave: mejora de imágenes con poca luz, fusión de imágenes infrarrojas, visión nocturna, imagen multisensor, visión por aprendizaje profundo