Clear Sky Science · es
Poda de bosques de árboles y remuestreo para el problema de clases desbalanceadas
Por qué importan los casos raros en las predicciones inteligentes
Muchas decisiones impulsadas por inteligencia artificial dependen de detectar el evento raro: un cargo fraudulento en una tarjeta, un signo temprano de enfermedad o una falla peligrosa en una máquina. En estas situaciones, los casos importantes son ampliamente superados en número por los ordinarios, y la mayoría de los algoritmos de aprendizaje tiende a ignorarlos. Este artículo presenta una forma de hacer que un método popular, los Bosques Aleatorios, preste mucha más atención a esos casos raros pero cruciales —al tiempo que hace el modelo más ligero y rápido.
El problema de ejemplos desiguales
El aprendizaje automático estándar funciona mejor cuando los datos están bien equilibrados —cuando hay números aproximadamente similares de ejemplos para cada resultado. En la vida real, sin embargo, los eventos raros dominan muchas tareas. Por ejemplo, solo una fracción de las exploraciones médicas muestra un tumor, y solo una porción mínima de las transacciones son fraudulentas. Este desequilibrio facilita que un algoritmo parezca tener buen rendimiento en papel al predecir mayoritariamente el resultado común, aunque falle repetidamente en el raro. A medida que la brecha entre casos comunes y raros crece, el límite de decisión del modelo se desplaza hacia la mayoría y la clase rara se vuelve más difícil de reconocer.
Equilibrar la balanza con muestreo inteligente
Los investigadores suelen intentar reequilibrar estos datos antes de entrenar modelos. Una opción es recortar la clase mayoritaria (submuestreo), descartando algunos casos comunes para igualar el número de los raros. Otra es copiar o generar ejemplos raros adicionales (sobremuestreo), aumentando su presencia sin perder datos originales. Un tercer enfoque híbrido mezcla ambas ideas, recortando algunos ejemplos mayoritarios mientras se incrementa la minoría. Cada táctica tiene sus compensaciones: recortar corre el riesgo de desechar información útil, mientras que duplicar muchos ejemplos puede ralentizar el entrenamiento y provocar sobreajuste. Los autores emplean las tres estrategias para crear conjuntos de entrenamiento más equilibrados y adaptados a los datos disponibles.
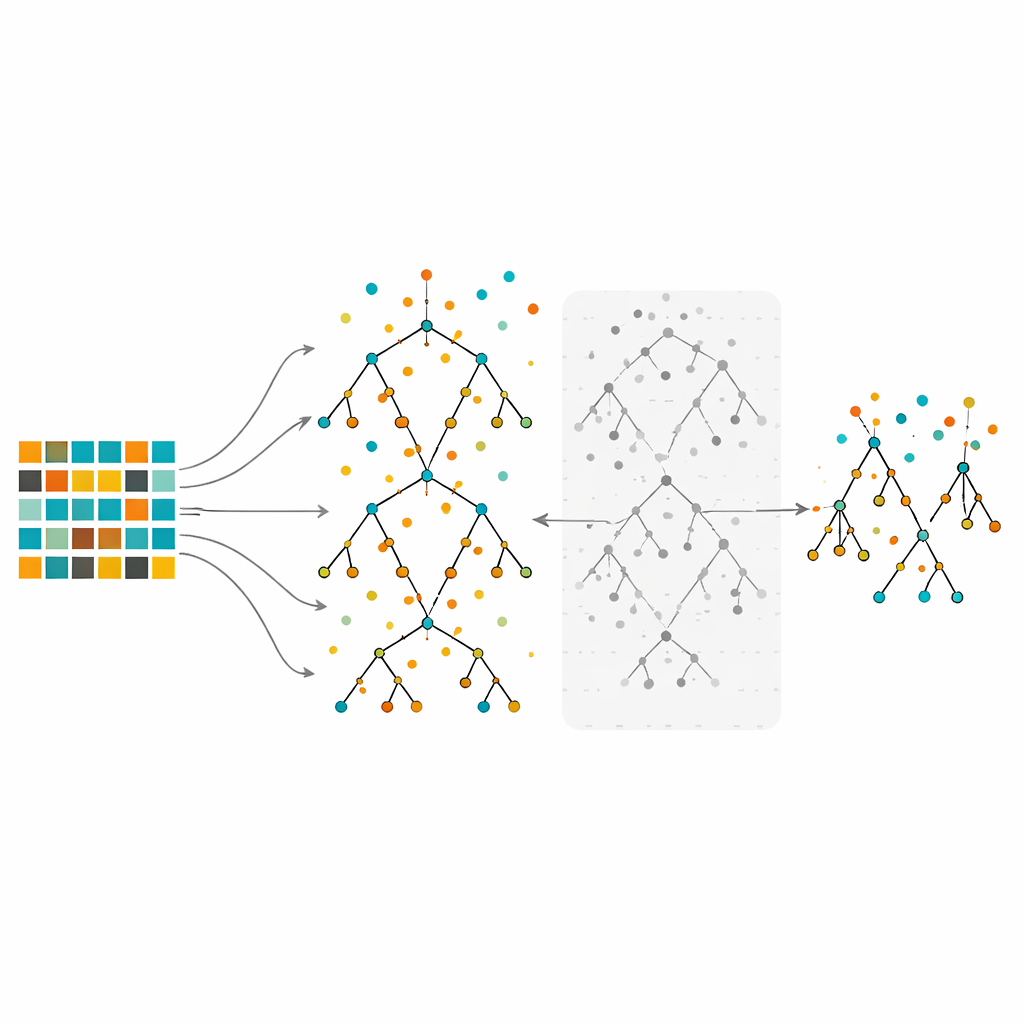
Enseñar y podar un bosque de árboles de decisión
El estudio se centra en los Bosques Aleatorios, un método ensemble que construye muchos árboles de decisión sobre porciones ligeramente diferentes de los datos y luego combina sus votos. Los Bosques Aleatorios son conocidos por manejar datos complejos y por destacar qué características son más importantes. Aun así, cuando se entrenan con datos fuertemente desbalanceados, incluso bosques grandes pueden sesgarse hacia la clase mayoritaria. En el método propuesto, los autores primero reequilibran los datos usando submuestreo, sobremuestreo o su híbrido. Luego crecen muchos árboles usando el procedimiento habitual de Bosque Aleatorio, pero con una variante importante: en lugar de conservar todos los árboles, evalúan cada uno usando observaciones fuera de bolsa (out-of-bag)—puntos de datos que no se usaron para construir ese árbol en particular—y descartan la mitad con las peores tasas de error. Este paso de poda produce un bosque más pequeño y selectivo construido con los árboles más fiables.
Pruebas en muchos conjuntos de datos del mundo real
Para comprobar el rendimiento de este bosque podado, los autores lo prueban en diez conjuntos de datos públicamente disponibles que reflejan una amplia gama de aplicaciones, desde mediciones médicas y biológicas hasta filtrado de correo basura y clasificación de sonidos. Cada conjunto tiene dos clases, con una claramente más rara que la otra, y varían en tamaño, número de características y grado de desequilibrio. El nuevo método se compara con varios enfoques muy usados: k-vecinos más cercanos, un único árbol de decisión, un Bosque Aleatorio estándar, una variante Balanced Random Forest y máquinas de soporte vectorial. A través de las distintas estrategias de muestreo, el bosque podado consigue de forma consistente menor tasa de error de clasificación que las alternativas en la mayoría de los conjuntos. La combinación de muestreo híbrido más poda ofrece los mejores resultados globales, tanto en precisión como en estabilidad del rendimiento en las diez tareas.
Modelos más precisos que gastan menos esfuerzo
Más allá de la precisión, el enfoque también mejora la eficiencia. Al eliminar los árboles menos eficaces, el conjunto final es más pequeño y requiere menos cálculo para entrenar y para hacer predicciones, sin sacrificar —y a menudo mejorando— su capacidad para detectar los casos raros. Pruebas estadísticas confirman que las mejoras frente a métodos competidores no se deben al azar. Para los practicantes que afrontan datos desbalanceados, este trabajo muestra que equilibrar cuidadosamente el conjunto de entrenamiento y luego podar un Bosque Aleatorio según el rendimiento out-of-bag puede dar modelos más precisos y eficientes. En términos cotidianos, el método ayuda a que nuestros algoritmos presten la atención debida a las señales raras pero importantes que se esconden en un mar de ejemplos ordinarios.
Cita: Faiz, N., Iftikhar, S., Jan, S. et al. Pruning tree forest and re-sampling for class imbalanced problem. Sci Rep 16, 8087 (2026). https://doi.org/10.1038/s41598-026-38320-1
Palabras clave: desequilibrio de clases, bosque aleatorio, remuestreo, aprendizaje automático, métodos ensemble