Clear Sky Science · es
Detección de intrusiones basada en anomalías en conjuntos de datos de referencia para la seguridad de redes: una evaluación exhaustiva
Por qué importan defensas más inteligentes para todos los usuarios en línea
Cada correo que envías, vídeo que transmites o factura que pagas en línea viaja por redes que están constantemente sondeadas por atacantes. Herramientas de seguridad llamadas sistemas de detección de intrusiones actúan como alarmas digitales, analizando este tráfico en busca de señales de peligro. Pero a medida que los ataques se vuelven más variados y sofisticados, las herramientas antiguas basadas en reglas tienen dificultades para mantenerse al día. Este estudio explora cómo los métodos modernos de aprendizaje profundo pueden alimentar alarmas más precisas y adaptables que detecten tanto amenazas conocidas como inéditas, manteniendo al mismo tiempo bajas las alertas falsas.
De reglas fijas a aprender por experiencia
Las herramientas tradicionales de detección de intrusiones funcionan de forma similar al software antivirus: buscan firmas conocidas, patrones específicos que coinciden con ataques catalogados. Este enfoque es rápido y fiable para amenazas familiares, pero falla cuando los atacantes cambian de táctica o emplean vulnerabilidades de día cero. Una estrategia más reciente, la detección de anomalías, aprende en su lugar cómo se comporta la red de manera normal y marca actividades inusuales. Eso la hace mejor para capturar ataques novedosos, aunque corre el riesgo de generar demasiadas falsas alarmas. Los autores se centran en el aprendizaje profundo, una rama de la inteligencia artificial en la que redes en capas de unidades de procesamiento simples aprenden automáticamente patrones a partir de datos, con el objetivo de combinar la adaptabilidad de la detección de anomalías con la fiabilidad de los sistemas basados en firmas.
Poniendo a prueba dos motores de aprendizaje
Los investigadores evalúan dos modelos populares de aprendizaje profundo: una red neuronal profunda (DNN), que procesa cada conexión de red como un registro numérico rico, y una red neuronal recurrente (RNN), que añade una "memoria" interna diseñada para capturar relaciones en datos ordenados. En lugar de crear características a mano, alimentan a estos modelos con conjuntos completos de medidas que describen cada conexión de red, tras convertir campos de texto a números y escalar todos los valores. Ambos modelos se entrenan y prueban exactamente de la misma manera en tres colecciones de referencia de tráfico de red ampliamente utilizadas: KDDCup99, NSL-KDD y UNSW-NB15, que en conjunto cubren una amplia gama de tipos de ataque, desde saturar un servidor con tráfico (DoS) hasta intentos furtivos de obtener privilegios adicionales de usuario.
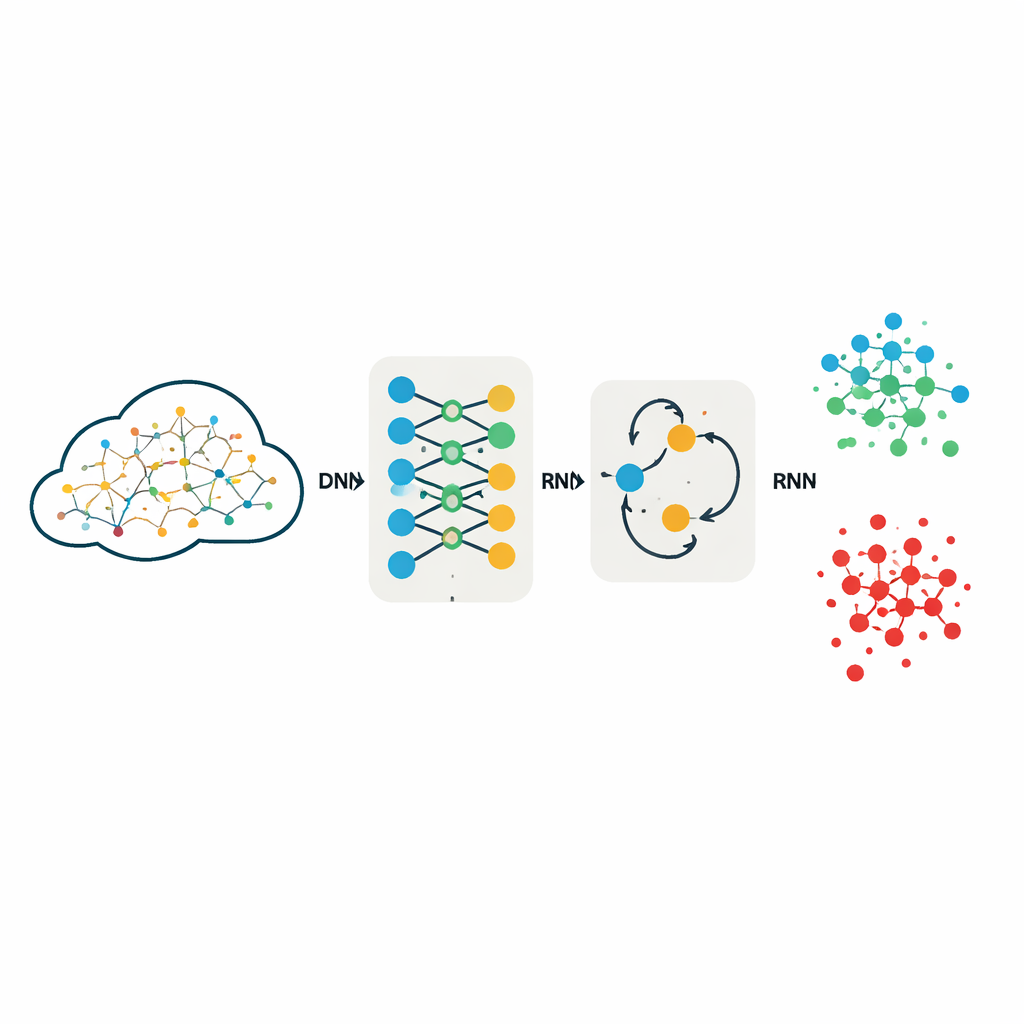
Cómo se diseñó cuidadosamente el estudio
Para que la comparación fuera justa y repetible, el equipo mantiene los diseños de los modelos intencionalmente simples y transparentes. La DNN utiliza tres capas totalmente conectadas para transformar las 40–42 características de entrada en predicciones sobre cinco o diez categorías de tráfico, como "normal" o diferentes familias de ataques. La RNN usa una capa recurrente ligera seguida de una capa de decisión final, tratando cada registro como una secuencia muy corta para poder modelar interacciones entre características. Ambos modelos emplean la misma función de activación y una estrategia de optimización ampliamente adoptada conocida por su aprendizaje estable. De forma crucial, los autores no descartan características para reducir los datos; trabajos anteriores mostraron que una reducción agresiva de características puede eliminar pistas sutiles que son vitales para distinguir ataques raros pero peligrosos.
Qué dicen los resultados sobre precisión y fiabilidad
En los conjuntos de datos más antiguos KDDCup99 y NSL-KDD, ambos modelos ofrecen un rendimiento notablemente alto: las precisiones superan el 99% con falsas alarmas por debajo del 1%. Esto significa que casi todas las conexiones maliciosas se detectan correctamente, mientras que muy pocas conexiones legítimas se marcan por error. En UNSW-NB15, un conjunto de datos más moderno y desafiante con diez clases distintas, el rendimiento baja algo como era de esperar, pero se mantiene sólido. La DNN alcanza aproximadamente un 96% de precisión, mientras que la RNN queda rezagada en torno al 82%. Las puntuaciones detalladas muestran que la DNN no solo clasifica bien los ataques comunes, sino que también maneja categorías raras como gusanos y ataques de usuario a root con altas puntuaciones F1, una medida que equilibra la detección de ataques y la evitación de fallos. Experimentos con un modelo más complejo basado en transformadores obtienen un rendimiento peor, lo que sugiere que una mayor sofisticación arquitectónica no proporciona automáticamente mejor seguridad.
Qué significa esto para redes más seguras
El estudio concluye que modelos de aprendizaje profundo bien diseñados pero relativamente sencillos pueden formar la columna vertebral de sistemas prácticos de detección de intrusiones. Al entrenar directamente con conjuntos de datos de referencia completos y ajustar cuidadosamente su proceso de aprendizaje, la DNN en particular alcanza una precisión de vanguardia con bajas tasas de falsos positivos en una amplia variedad de tipos de ataque. Para los usuarios cotidianos, esto se traduce en herramientas de seguridad que detectan mejor tanto amenazas rutinarias como inusuales sin dar la alarma constantemente. Los autores sugieren que trabajos futuros pueden construir sobre esta base refinando modelos recurrentes, explorando reducción selectiva de características para ganar velocidad y combinando extractores profundos de características con clasificadores tradicionales, acercándonos a una detección de intrusiones potente y eficiente en redes del mundo real.
Cita: Kumar, L.K.S., Nethi, S.R., Uyyala, R. et al. Anomaly-based intrusion detection on benchmark datasets for network security: a comprehensive evaluation. Sci Rep 16, 8507 (2026). https://doi.org/10.1038/s41598-026-38317-w
Palabras clave: detección de intrusiones, seguridad de redes, aprendizaje profundo, detección de anomalías, ciberataques