Clear Sky Science · es
Aprendizaje federado para sistemas heterogéneos de registros electrónicos de salud con selección rentable de participantes
Por qué es tan difícil compartir datos hospitalarios
Los hospitales modernos recopilan enormes cantidades de información digital sobre sus pacientes, desde pruebas de laboratorio y signos vitales hasta medicamentos y procedimientos. En teoría, combinar estos registros entre muchas instituciones debería permitir a los médicos construir modelos informáticos más inteligentes que predigan quién está en riesgo y qué tratamientos pueden ayudar más. En la práctica, sin embargo, los hospitales usan distintos sistemas de software, almacenan datos en formatos incompatibles y deben proteger estrictamente la privacidad de los pacientes y sus presupuestos. Este estudio explora cómo permitir que los hospitales aprendan unos de otros sin copiar los datos ni gastar de más.
Entrenar juntos sin compartir registros en bruto
Los autores se basan en un enfoque llamado aprendizaje federado, en el que cada hospital entrena un modelo local sobre sus propios registros de pacientes y luego comparte solo actualizaciones de modelo, no datos en bruto. Un hospital central “anfitrión” coordina este proceso y busca mejorar un modelo de predicción para sus propias necesidades, como pronosticar complicaciones en cuidados intensivos. Otros hospitales, llamados sujetos, participan a cambio de compensación. Esta configuración evita mover registros sensibles entre instituciones, pero plantea dos preguntas difíciles: cómo trabajar con muchos sistemas de registros diferentes y cómo evitar pagar a colaboradores que en realidad no ayudan al modelo.
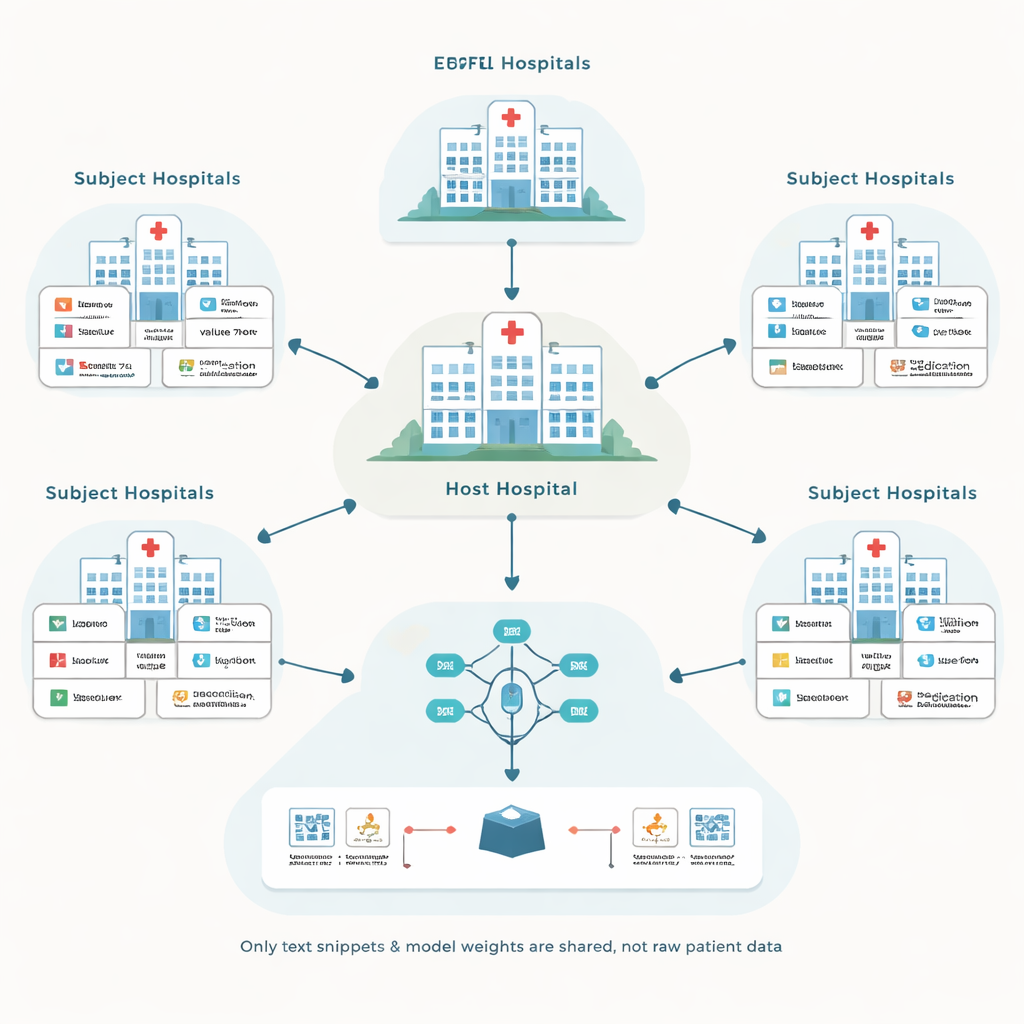
Convertir registros desordenados en un lenguaje compartido
Los sistemas de registros electrónicos de salud varían ampliamente en cómo etiquetan y codifican la información. Un hospital puede almacenar una prueba de glucemia bajo un código numérico, mientras que otro usa un código distinto para la misma prueba. Las soluciones tradicionales intentan convertir todo a una única base de datos estándar cuidadosamente diseñada, lo cual es caro y requiere muchas horas de expertos. En cambio, el marco propuesto, llamado EHRFL, convierte cada evento médico en un breve texto. Por ejemplo, una entrada de laboratorio como una medición de glucosa se transforma en una frase como “evento de laboratorio glucosa valor 70 mg/dL.” Dado que cada hospital ya mantiene diccionarios que mapean códigos locales a nombres legibles por humanos, esta conversión puede automatizarse sin ajustes manuales personalizados.
Construir perfiles de paciente a partir de texto
Una vez que los eventos se escriben como texto, EHRFL emplea modelos modernos de procesamiento de lenguaje para convertir cada evento en un vector numérico y luego combina muchos eventos en un único “embedding de paciente”: un resumen compacto del historial médico de esa persona en una ventana temporal. Estos embeddings alimentan una capa de predicción que aborda varias tareas clínicas a la vez, como predecir la muerte en el hospital o lesión renal tras una admisión en cuidados intensivos. Los autores ejecutan entrenamiento federado sobre cinco grandes conjuntos de datos reales de cuidados críticos que abarcan distintos hospitales, periodos temporales y sistemas de registro. En una variedad de algoritmos, incluidos métodos federados de uso común, los modelos entrenados con este enfoque basado en texto superan de forma consistente a los modelos entrenados en un solo hospital, aunque los formatos de datos subyacentes difieran.
Elegir a los socios adecuados mientras se protege la privacidad
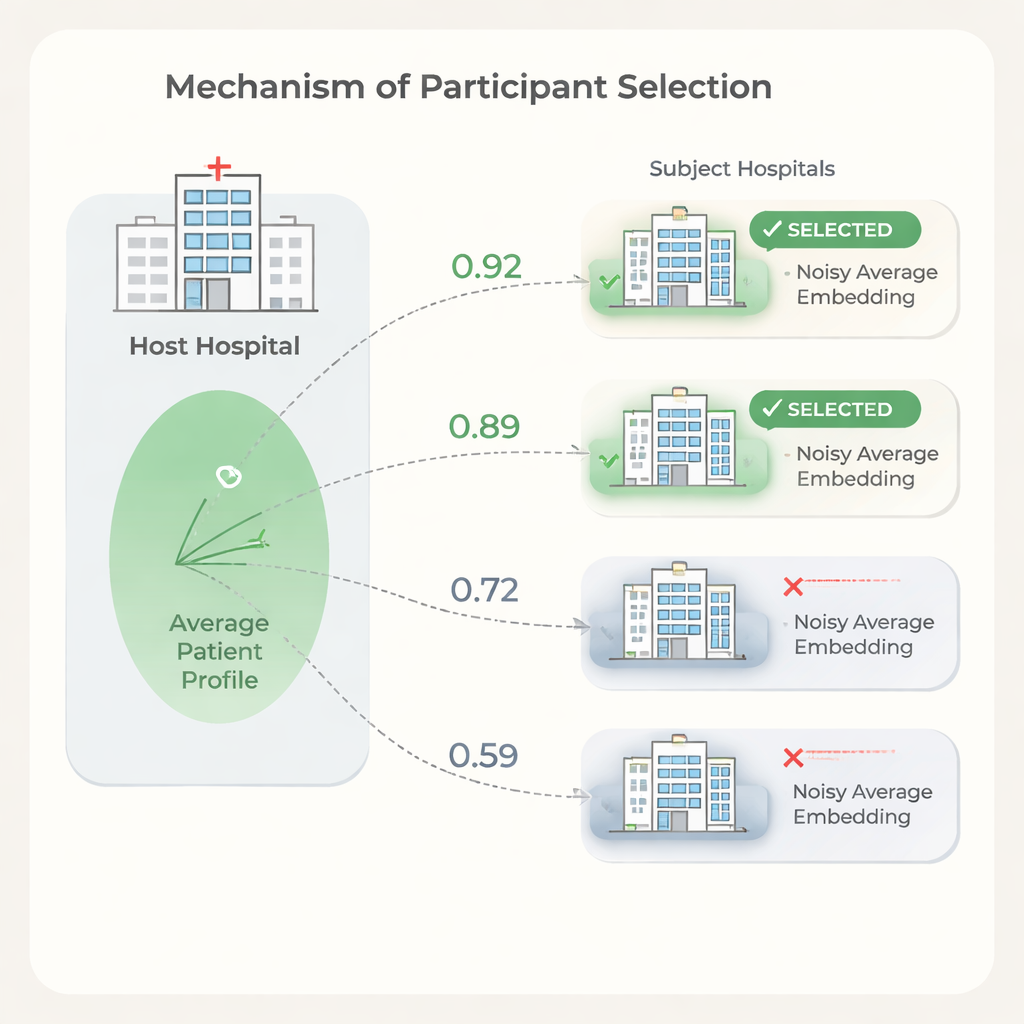
Tener más hospitales colaboradores no siempre equivale a mejores resultados. Algunas instituciones tienen poblaciones de pacientes o patrones de registro tan diferentes del anfitrión que incluirlas puede ralentizar el entrenamiento o perjudicar ligeramente el rendimiento, a la vez que incrementa el coste. Para abordar esto, los autores proponen un paso de selección basado en la similitud entre los embeddings promedio de pacientes de los hospitales. El anfitrión primero entrena un modelo con sus propios datos, comparte los pesos del modelo y cada hospital candidato los utiliza para calcular embeddings de pacientes. Para proteger la privacidad, cada sujeto recorta valores extremos de sus embeddings, los promedia en un único vector y luego añade ruido aleatorio cuidadosamente calibrado antes de enviar solo este promedio ruidoso al anfitrión. El anfitrión compara su propio promedio con el de cada sujeto usando medidas simples de similitud y elige solo los hospitales más similares para unirse a la ejecución federada completa.
Ahorro de costes sin perder precisión
Los experimentos muestran que la similitud entre los embeddings promedio de pacientes de los hospitales se alinea con cuánto ayuda o perjudica cada hospital al rendimiento de predicción del anfitrión. Usando esta señal para seleccionar socios, el anfitrión puede descartar hospitales de baja similitud mientras mantiene o incluso mejora la calidad de la predicción en comparación con usar todos los sitios disponibles. Los autores también presentan un modelo de costes que muestra que, dado que las tarifas por uso de datos y el tiempo de entrenamiento escalan con el número de hospitales participantes, incluso reducciones modestas en el número de colaboradores pueden generar ahorros sustanciales. Al mismo tiempo, el paso de selección es ligero: el modelo se entrena una vez y cada hospital solo realiza cálculos simples sobre un único vector promedio.
Qué significa esto para la IA sanitaria futura
Para lectores fuera del campo, el mensaje clave es que puede ser posible que los hospitales “aprendan juntos” sin agrupar los registros crudos de pacientes y hacerlo de una manera que respete tanto la privacidad como los límites financieros. Al traducir registros diversos a una forma textual compartida y luego usar resúmenes preservadores de la privacidad de las poblaciones de pacientes para elegir socios compatibles, EHRFL ofrece una receta práctica para construir herramientas de predicción específicas para hospitales. Aunque el estudio se centra en datos de cuidados intensivos, las mismas ideas podrían extenderse a consultas ambulatorias, urgencias e incluso a dominios no médicos donde organizaciones quieran colaborar en mejores modelos sin ceder el control de sus datos.
Cita: Kim, J., Kim, J., Hur, K. et al. Federated learning for heterogeneous electronic health record systems with cost effective participant selection. Sci Rep 16, 6876 (2026). https://doi.org/10.1038/s41598-026-38299-9
Palabras clave: aprendizaje federado, registros electrónicos de salud, privacidad del paciente, predicción clínica, IA en salud