Clear Sky Science · es
NeuroAction: un enfoque neuroevolutivo para el aprendizaje por refuerzo en vehículos autónomos
Por qué importan estilos de conducción más inteligentes
La mayoría imaginamos los coches autónomos como conductores serenos y perfectamente racionales. Pero los sistemas actuales tienden a perseguir una única mezcla de objetivos —por ejemplo, no chocar mientras te llevan rápido— y esa mezcla la definen los ingenieros. NeuroAction, el enfoque descrito en este artículo, pretende dotar a los coches autónomos de algo más cercano a la flexibilidad humana: la capacidad de elegir entre muchos estilos de conducción seguros, desde un comportamiento extremadamente cauteloso «bebé a bordo» hasta una conducción rápida en autopista, sin tener que reentrenar el coche cada vez.
De talla única a muchas opciones seguras
Los sistemas actuales de aprendizaje profundo por refuerzo para la conducción aprenden por ensayo y error: observan la carretera, realizan acciones como girar o acelerar, y reciben una recompensa numérica única que mezcla diferentes fines como velocidad, seguridad y posición en el carril. Para ajustar el sistema, los ingenieros deben diseñar esa recompensa única con mucho cuidado. Si ponderan demasiado la velocidad, el coche puede conducir agresivamente; si sobrevaloran la seguridad, puede avanzar muy despacio. Cambiar las preferencias más tarde suele implicar volver a entrenar una gran red neuronal desde cero, lo cual es lento, requiere mucha memoria y es sensible a parámetros técnicos.
Dividir la conducción en objetivos simples
NeuroAction aborda esto dividiendo la tarea de conducción en varios objetivos claros en lugar de uno solo. En el estudio, el conductor virtual del coche se evalúa de forma independiente en tres aspectos: qué tan rápido viaja dentro de un rango seguro, qué tan fielmente se mantiene en el carril más a la derecha (normalmente más seguro) y qué tan bien evita las colisiones. En lugar de combinar estos factores en una sola puntuación, el método los trata como métricas separadas. En segundo plano, cada política de conducción posible —la red neuronal que convierte las entradas de los sensores en decisiones de dirección y velocidad— se evalúa a lo largo de los tres ejes a la vez.
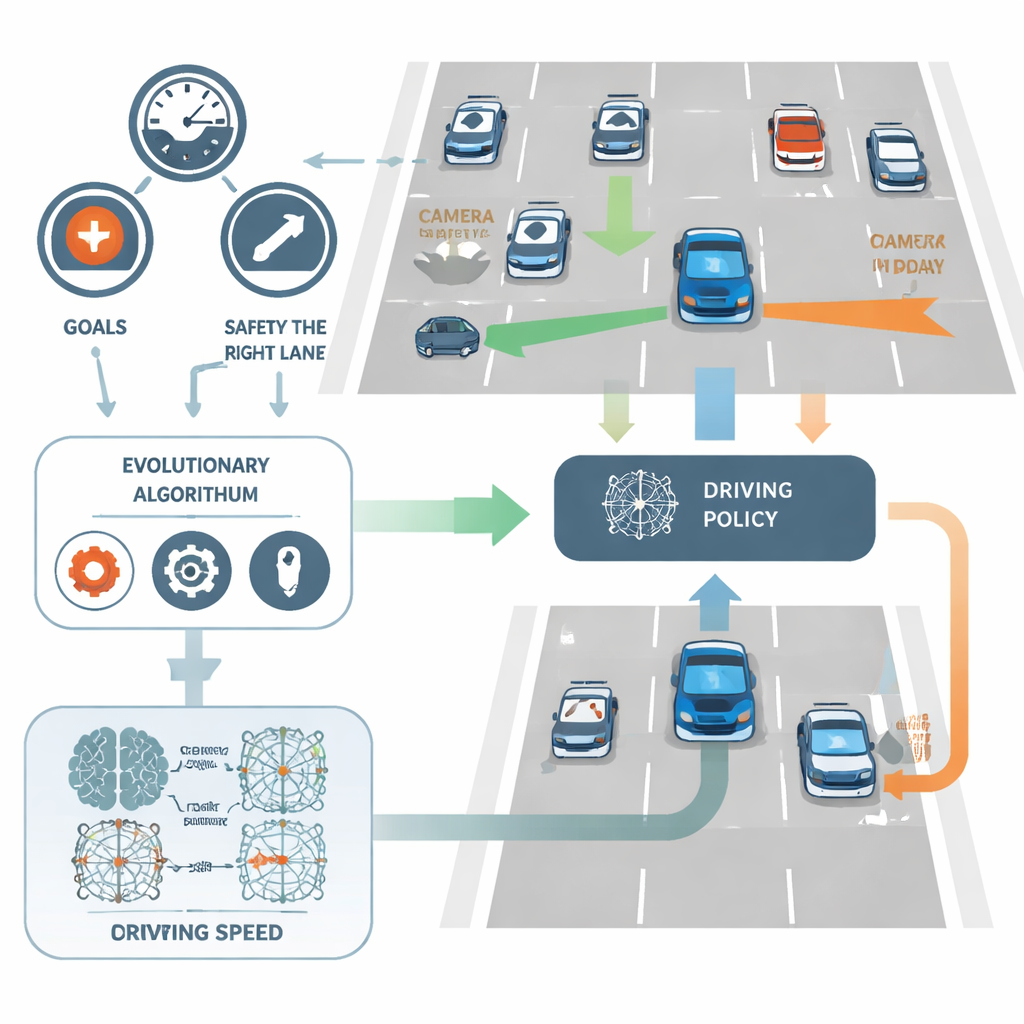
Dejar que la evolución busque mejores conductores
En lugar de ajustar los pesos de la red con la técnica estándar de retropropagación, NeuroAction emplea ideas tomadas de la evolución biológica. Se crea una población de distintas políticas de conducción y se prueban en un entorno simulado de autopista. Se mantienen y recombinan las políticas que logran buenos compromisos entre velocidad, disciplina de carril y seguridad, mientras que las menos eficaces se descartan. A lo largo de muchas generaciones, este proceso evolutivo descubre toda una frontera de soluciones fuertes —conocida como frente de Pareto— donde ninguna política puede mejorarse en un objetivo sin sacrificar al menos otro.
Comparando aprendizaje evolutivo y basado en gradiente
Los investigadores aplicaron NeuroAction a un simulador de autopista 2D ampliamente utilizado, empleando un agente de conducción estándar basado en redes neuronales. A continuación optimizaron los parámetros del agente con varios algoritmos evolutivos multiobjetivo establecidos, comparando qué tan bien cubría cada uno el rango de compromisos deseables. Una medida clave de rendimiento, el «hipervolumen» de la frontera encontrada, captura tanto la calidad como la diversidad de las soluciones. Un algoritmo, NSGA-II, obtuvo la mejor cobertura global, mientras que un pariente cercano, NSGA-III, produjo resultados particularmente consistentes en ejecuciones repetidas.
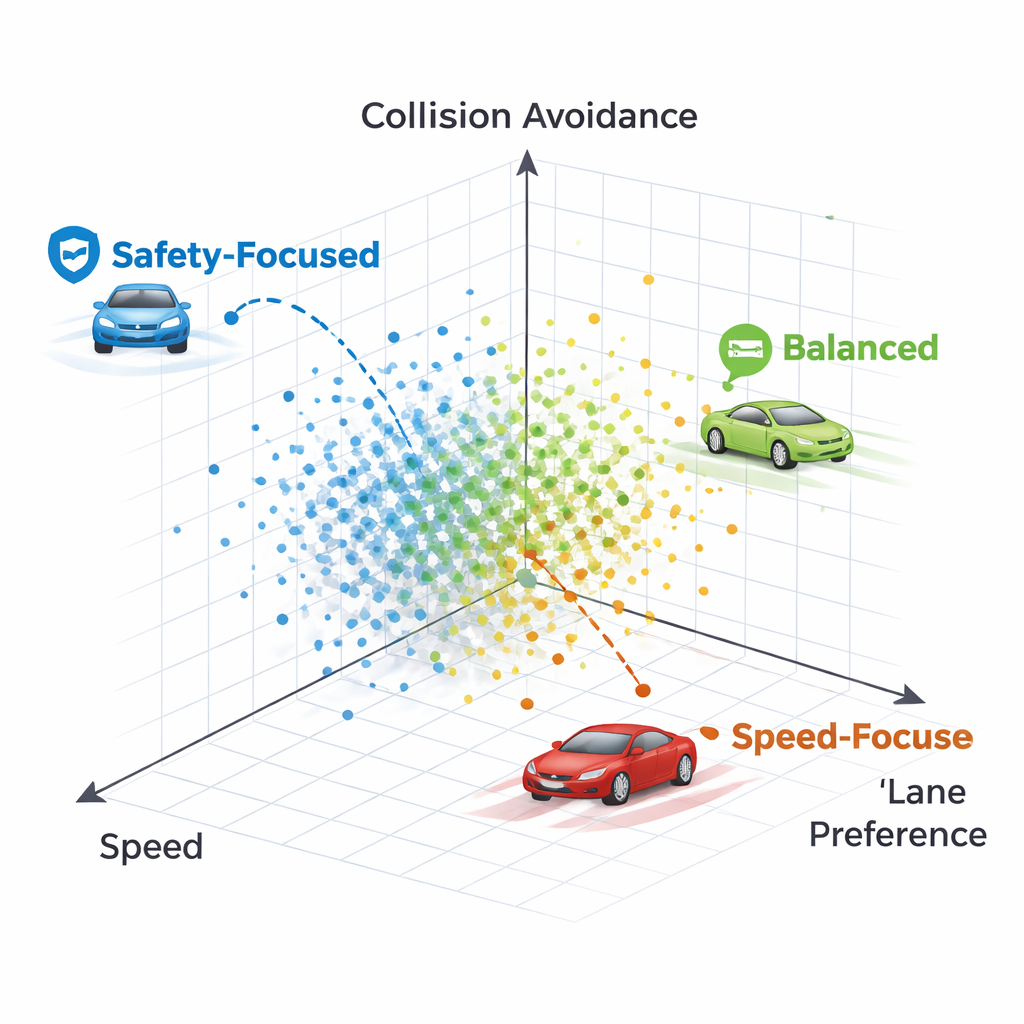
Cómo se ven los distintos estilos de conducción
Al inspeccionar políticas individuales en el frente de Pareto, los autores muestran que cada punto corresponde a un estilo de conducción reconocible. Una política se mantiene firmemente en el carril derecho casi a cualquier precio, sacrificando velocidad y llegando a chocar con un vehículo muy lento por delante: una estrategia excesivamente cautelosa que valora en exceso la preferencia por el carril. Otra política cambia de carril inicialmente pero luego regresa a un carril derecho despejado, manteniendo mayor velocidad mientras sigue evitando choques. En general, los métodos producen un espectro de estrategias que van desde conductores conservadores que mantienen el carril hasta conductores más asertivos pero aún seguros, todos disponibles simultáneamente sin reentrenamiento.
Qué significa esto para los futuros coches autónomos
Para un público no especializado, el mensaje central es que NeuroAction convierte el entrenamiento de coches autónomos en una búsqueda de muchas buenas opciones en lugar de un único comportamiento fijo. Esto hace posible seleccionar una política de conducción acorde con la situación —lenta y ultra segura cuando se transportan niños, más rápida si tienes prisa— mientras se siguen respetando las restricciones de seguridad. Aunque los experimentos actuales son en simulación y usan objetivos simplificados, el marco apunta hacia vehículos autónomos más adaptables y conscientes de las preferencias, capaces de ofrecer estilos de conducción personalizados pero fiables, sobre una base matemática sólida.
Cita: Aboyeji, E., Ajani, O.S., Fenyom, I. et al. NeuroAction: a neuroevolutionary approach to reinforcement learning for autonomous vehicles. Sci Rep 16, 7403 (2026). https://doi.org/10.1038/s41598-026-38269-1
Palabras clave: conducción autónoma, aprendizaje por refuerzo, algoritmos evolutivos, optimización multiobjetivo, coches autónomos