Clear Sky Science · es
Descomposición de tensores sin rango mediante aprendizaje métrico
Encontrar patrones en un mar de datos
La ciencia moderna está inundada de datos complejos: pilas de exploraciones médicas, mapas de actividad cerebral, imágenes astronómicas y simulaciones de materiales. Entender estos datos suele implicar comprimirlos en formas más simples sin perder lo que realmente importa. Este artículo presenta una nueva forma de hacerlo. En lugar de intentar reconstruir fielmente cada píxel, se centra en capturar las verdaderas relaciones entre las muestras —qué cerebro se parece más a cuál, qué forma de galaxia se asemeja a otra— para que el mapa resultante de los datos refleje significado en lugar de detalle bruto.
De reconstruir imágenes a medir similitud
Las herramientas tradicionales para simplificar datos multidimensionales, conocidas como descomposiciones de tensores, funcionan un poco como descomponer un acorde en notas. Factorizan un “bloque” de datos en un pequeño número de patrones básicos más pesos. Para ello, deben conocerse de antemano cuántos patrones —el “rango”— se pueden usar, y evalúan el éxito por la calidad de la reconstrucción del dato original. Eso es ideal para compresión o eliminación de ruido, pero no necesariamente para tareas como “¿son estas dos caras la misma persona?” o “¿pertenece esta exploración cerebral a una persona con autismo o a una típica?”, donde agrupar correctamente importa más que la reconstrucción perfecta.
En paralelo, el aprendizaje profundo ha popularizado otra idea: en lugar de descomponer un tensor algebraicamente, aprender un código numérico compacto, o incrustación, mediante una red neuronal. Los autoencoders clásicos siguen centrados en la reconstrucción. Este trabajo invierte el objetivo. Propone un marco “sin rango” que no fija un rango por adelantado y no se preocupa por una recuperación perfecta de píxeles. En su lugar, aprende una medida de distancia de modo que puntos que deben estar cerca (misma persona, mismo diagnóstico, misma clase física) terminen vecinos en el espacio de incrustación, y los que deben ser diferentes queden separados.
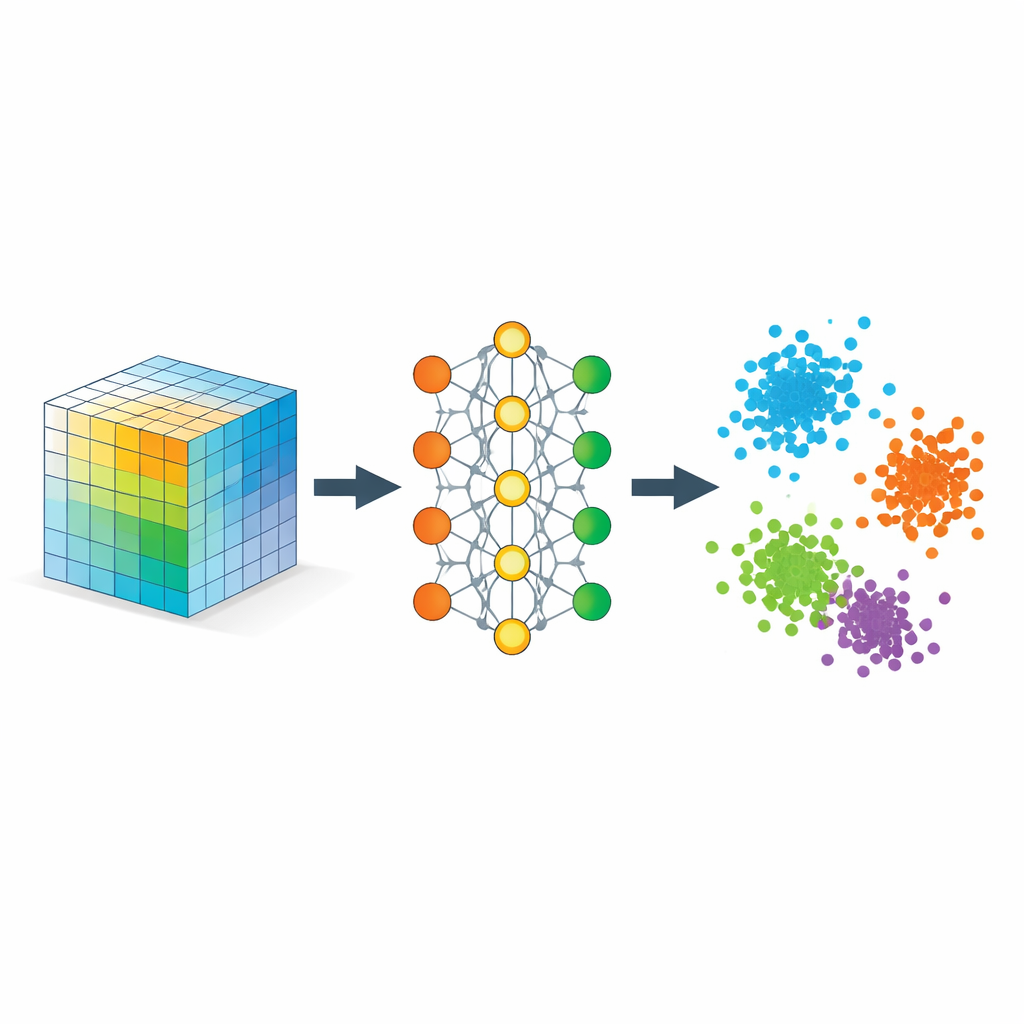
Enseñar a la red qué debe significar “cercano”
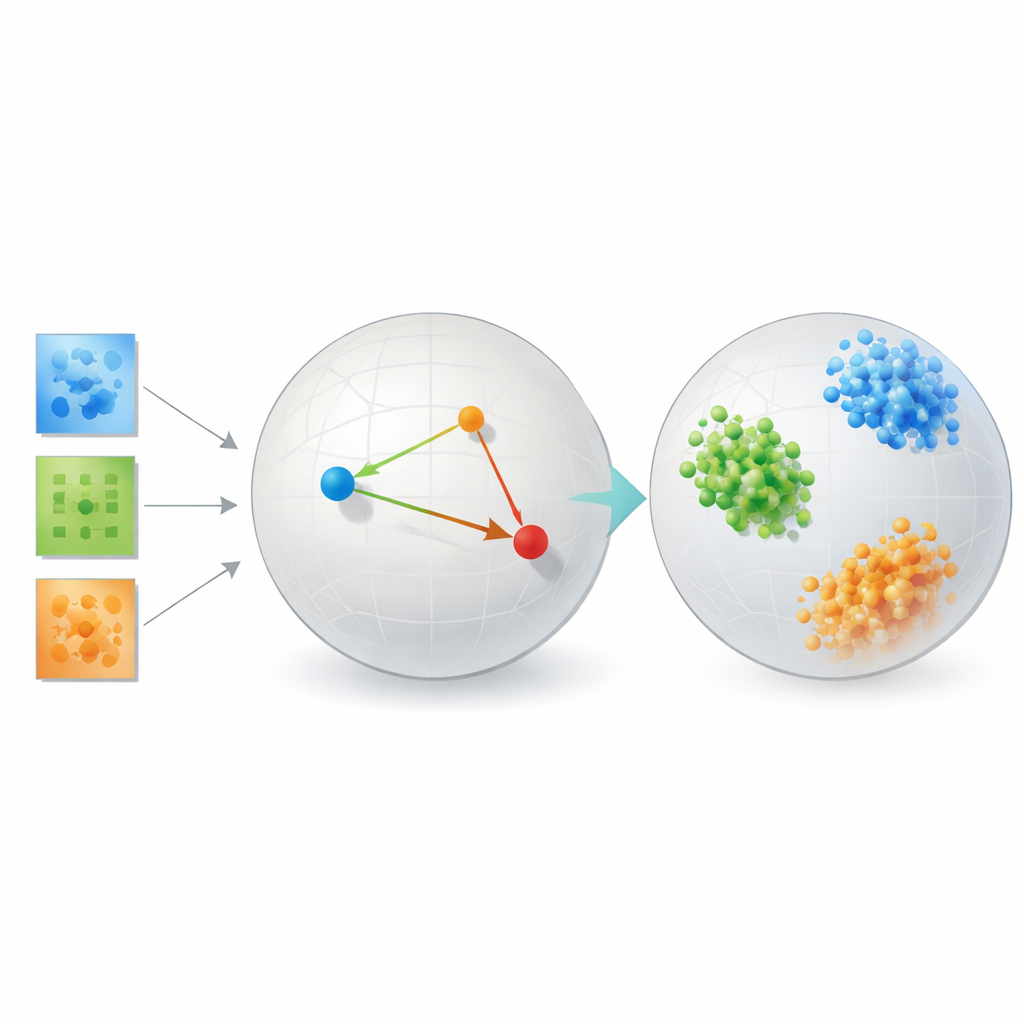
El ingrediente clave es una estrategia llamada aprendizaje métrico, implementada aquí mediante tríos de ejemplos: una muestra ancla, una muestra positiva del mismo tipo y una muestra negativa de distinto tipo. Durante el entrenamiento, la red es recompensada cuando el ancla queda más cerca de la positiva que de la negativa por un margen de seguridad. A lo largo de muchos tríos así, esta regla simple esculpe el espacio de incrustación para que las distancias reflejen similitud semántica en lugar de similitud de píxeles. Regularizadores adicionales animan a la red a distribuir la información de forma uniforme entre las dimensiones, evitar que todo colapse en una línea y mantener los vecindarios locales razonablemente intactos, de modo que puntos cercanos en los datos originales sigan estando cerca una vez incrustados.
Matemáticamente, los autores muestran que esta incrustación se comporta como una descomposición de tensores flexible, pero sin un rango preestablecido. Las coordenadas aprendidas pueden interpretarse como factores en una descomposición clásica de un tensor de similitud cuyos elementos miden cuán fuertemente se alinean distintas partes de los datos. Como el modelo penaliza direcciones redundantes, tiende a usar de forma eficaz todas las dimensiones de la incrustación, dejando que los propios datos determinen cuántos componentes significativos son necesarios. Al mismo tiempo, ofrecen garantías teóricas de que los procedimientos de entrenamiento estándar convergen y de que la geometría resultante separa las clases fielmente sin distorsionar en exceso las relaciones locales relevantes.
Poner el método a prueba
Para mostrar que su enfoque no es sólo teoría elegante, el autor lo prueba en varios problemas muy distintos. En benchmarks de reconocimiento facial, las incrustaciones aprendidas agrupan imágenes de la misma persona en cúmulos compactos y bien separados, superando con creces métodos clásicos como componentes principales, herramientas populares de visualización como t-SNE y UMAP, y descomposiciones de tensores tradicionales que dependen de rangos fijos. En datos de conectividad cerebral de personas con y sin autismo, el método descubre un espacio donde los dos grupos están más claramente separados que con herramientas tensoriales enfocadas en la reconstrucción o redes neuronales autoencoder, lo que sugiere que capta patrones clínicamente relevantes en la interacción entre regiones cerebrales.
El estudio también incluye simulaciones controladas de formas galácticas y estructuras cristalinas, donde las categorías “reales” se conocen exactamente. Allí, el marco de aprendizaje métrico agrupa casi a la perfección las galaxias y los cristales sintéticos según sus tipos físicos subyacentes. En todos estos escenarios, el método sacrifica algo de fidelidad al arreglo original de píxeles a cambio de una representación en la que la semejanza y la diferencia se alinean con el significado científico. Es importante destacar que lo hace sin los enormes datos y recursos de cálculo que suelen requerir los modelos profundos basados en transformadores, que tuvieron dificultades en estos conjuntos de datos científicos relativamente pequeños.
Por qué esto importa para los datos científicos futuros
Para los científicos que buscan patrones en datos limitados y de alta dimensión, este trabajo ofrece un cambio de perspectiva atractivo. En lugar de adivinar un rango y optimizar la reconstrucción, los investigadores pueden pedir directamente una incrustación que refleje las relaciones que les importan: mismo diagnóstico, misma fase de material, misma clase astrofísica. El marco propuesto de aprendizaje métrico sin rango demuestra que tales incrustaciones pueden ser a la vez interpretables y potentes, especialmente cuando los datos son escasos. Como señalan los autores, quedan desafíos —incluida la gestión del desequilibrio de clases y la escalabilidad a muchas categorías—, pero el mensaje es claro: en muchos problemas científicos, aprender una buena noción de similitud puede ser más valioso que reconstruir cada detalle de la señal original.
Cita: Bagherian, M. No-rank tensor decomposition via metric learning. Sci Rep 16, 8326 (2026). https://doi.org/10.1038/s41598-026-38221-3
Palabras clave: aprendizaje métrico, descomposición de tensores, aprendizaje de representaciones, reducción de dimensionalidad, análisis de datos científicos