Clear Sky Science · es
Un modelo de acoplamiento de degradación guiado por VLM para fusión de imágenes infrarrojas y visibles consciente de la degradación
Visión nocturna más nítida para un mundo ruidoso
Las cámaras modernas pueden ver en la oscuridad, detectar calor y vigilar la carretera por nosotros; sin embargo, sus imágenes a menudo están lejos de ser perfectas. Las farolas generan destellos, las sombras ocultan detalles y los sensores introducen ruido punteado. Este estudio presenta una nueva forma de fusionar vídeo en color ordinario con imágenes infrarrojas térmicas para que la vista final sea más clara y fiable, incluso cuando ambas entradas están muy degradadas. El método podría hacer que los coches autónomos, los sistemas de vigilancia y otras cámaras inteligentes sean más fiables en las condiciones que más nos importan: de noche, con mal tiempo y en escenas reales saturadas de complejidad.
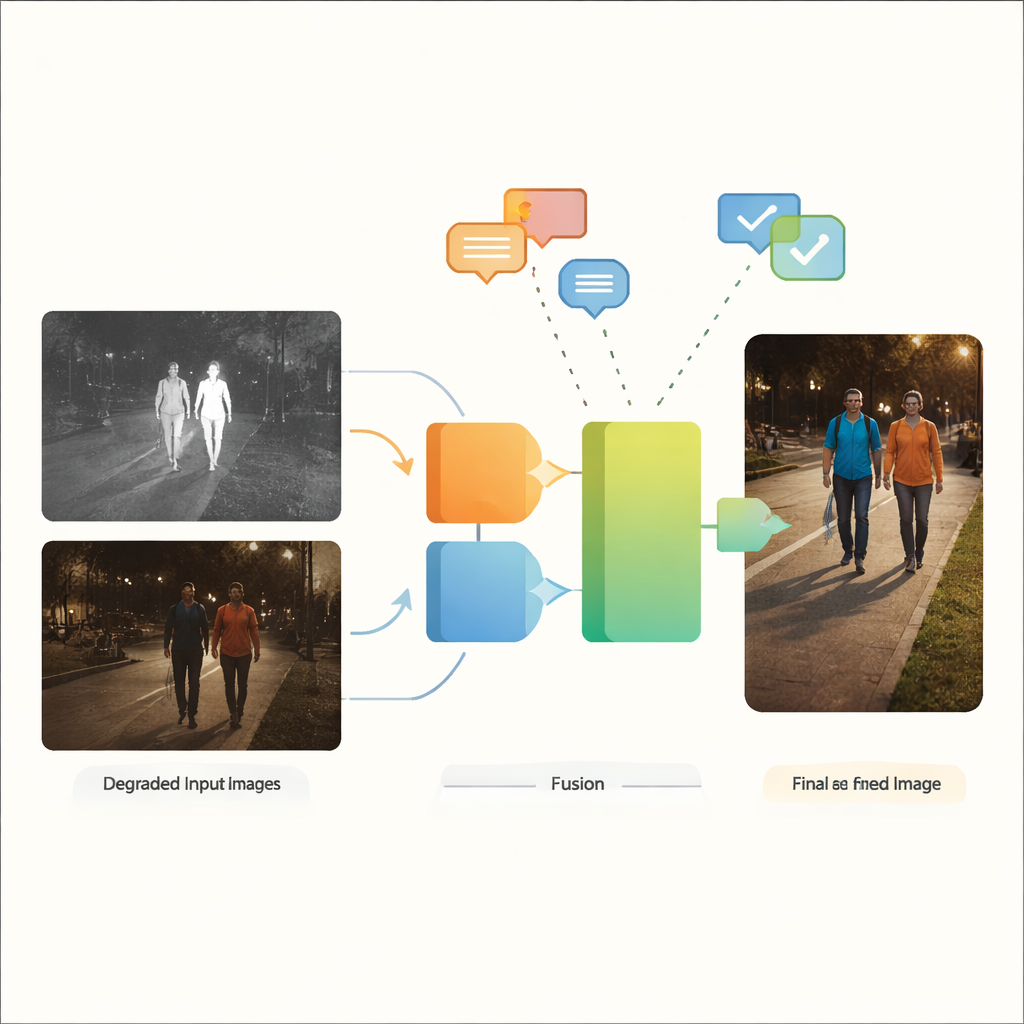
Por qué dos ojos son mejores que uno
Las cámaras de luz visible capturan los ricos colores y texturas a los que estamos acostumbrados, pero se debilitan en condiciones de poca luz, deslumbramiento y sombras intensas. Las cámaras infrarrojas, en cambio, detectan el calor y distinguen fácilmente objetos cálidos como personas o vehículos en la oscuridad, aunque sus imágenes suelen verse planas y carecer de detalles finos. La fusión de imágenes infrarrojas y visibles busca combinar lo mejor de ambos: los contornos nítidos de los objetivos cálidos del infrarrojo con el detalle contextual y el color de la luz visible. Tradicionalmente, sin embargo, la mayoría de los métodos de fusión asumen que ambas imágenes de entrada ya están limpias y son de alta calidad, lo cual encaja mal con calles, ciudades y entornos industriales reales donde el desenfoque, el ruido, la iluminación tenue y la sobreexposición son la norma en lugar de la excepción.
Cuando el preprocesamiento se queda corto
Los sistemas existentes suelen abordar las imágenes degradadas en dos pasos desconectados. Primero, herramientas de mejora separadas iluminan escenas oscuras, reducen el ruido o corrigen el contraste. Solo entonces una red de fusión mezcla las imágenes mejoradas. Este enfoque en dos etapas tiene varias desventajas. Obliga a los ingenieros a elegir y ajustar distintas herramientas de mejora para cada tipo de defecto y cada sensor, haciendo los flujos de trabajo frágiles y complejos. Más importante aún, cualquier información perdida o distorsionada durante la limpieza independiente no puede recuperarse después en la etapa de fusión. Algunas investigaciones recientes introdujeron redes especiales ajustadas a un tipo específico de degradación o usaron modelos guiados por lenguaje para manejar una única modalidad degradada a la vez. Aun así, cuando tanto las imágenes infrarrojas como las visibles están degradadas —y a menudo lo están de maneras diferentes—, estas estrategias siguen dependiendo en gran medida del preprocesamiento manual y tienen dificultades con condiciones mixtas y del mundo real.
Una red de fusión que entiende la degradación
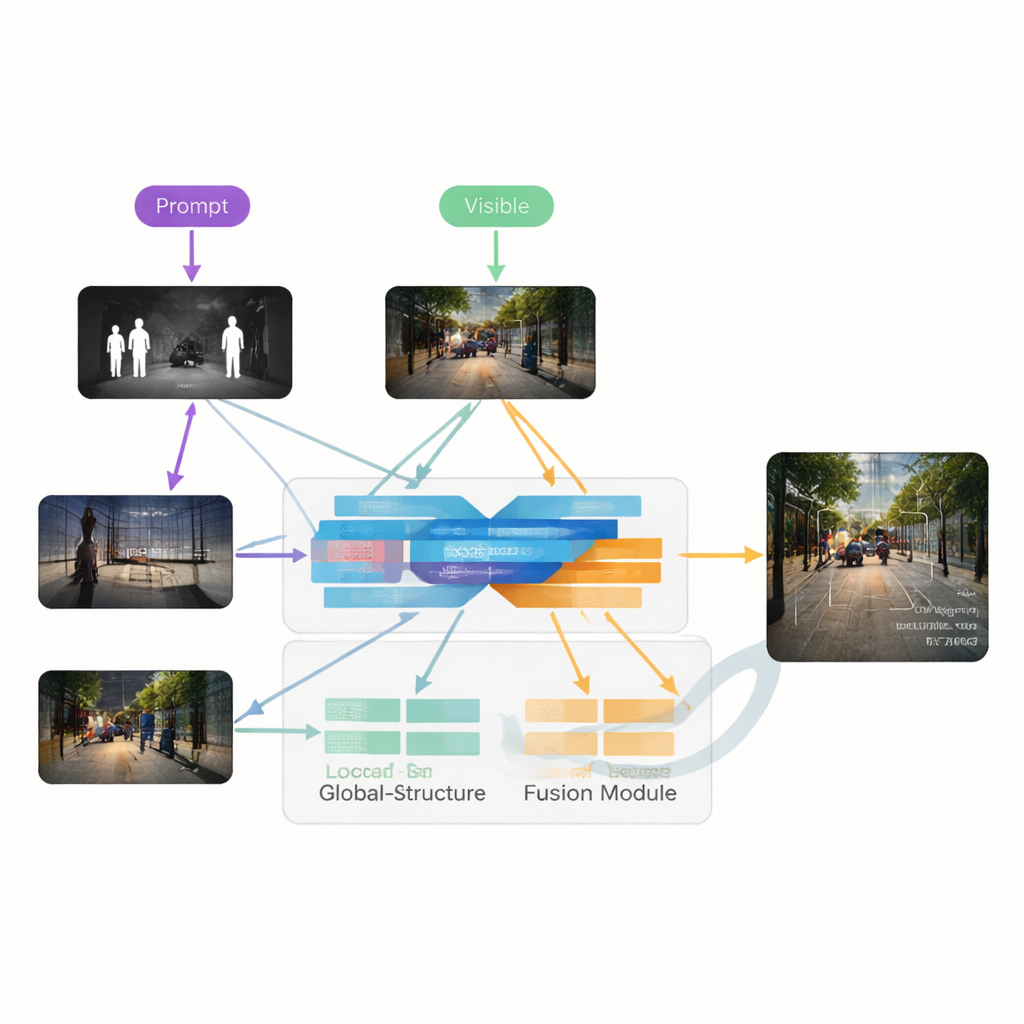
Los autores proponen VGDCFusion, un nuevo marco de aprendizaje profundo que integra el manejo de la degradación directamente en el proceso de fusión. La idea clave es informar a la red, con palabras, sobre qué tipo de problemas debe esperar y luego usar ese conocimiento en cada paso de la extracción y fusión de características. Breves indicaciones de texto describen la tarea (fusión infrarrojo–visible) y los problemas específicos presentes, como poca luz, sobreexposición, bajo contraste o ruido. Un potente modelo visión‑lenguaje —similar en espíritu a sistemas como CLIP— convierte estas indicaciones en descriptores numéricos compactos. Estos descriptores guían dos bloques principales: el Extractor Acoplado a Degradación con Indicaciones Específicas (SPDCE), que opera por separado en cada modalidad, y la Fusión Conjunta Acoplada a Degradación con Indicaciones (JPDCF), que combina información entre modalidades atendiendo a qué tipo de degradación persiste.
Cómo funciona el proceso de fusión guiada
Dentro de cada módulo SPDCE, la guía derivada de las indicaciones orienta a la red hacia las características relevantes y lejos de los artefactos. Capas de convolución multiescala examinan vecindarios pequeños para preservar bordes y texturas, mientras que capas Transformer capturan estructura y contexto a mayor escala. Juntas aprenden a resaltar, por ejemplo, firmas térmicas importantes en un fotograma infrarrojo ruidoso o marcas viales tenues en una imagen visible subexpuesta, al tiempo que suprimen el ruido del sensor y los defectos de iluminación. En paralelo, los módulos JPDCF toman las características limpiadas de ambas ramas y las combinan, nuevamente bajo la orientación de las indicaciones. Usan atención espacial y por canales para enfatizar regiones informativas, filtrar la degradación restante y reunir pistas complementarias —como alinear un contorno brillante de infrarrojo de un peatón con el color y la estructura de fondo de la cámara visible— antes de reconstruir una imagen fusionada de tres canales.
Poniendo el método a prueba
Para demostrar su utilidad, el equipo evaluó VGDCFusion en varios conjuntos de datos públicos que incluyen imágenes visibles con poca luz y sobreexpuestas, así como imágenes infrarrojas ruidosas o de bajo contraste. Compararon su método con una variedad de técnicas de fusión de última generación que abarcan autoencoders, redes convolucionales, redes generativas adversarias y Transformers. Usando medidas estándar de calidad de imagen, VGDCFusion produjo de forma consistente imágenes fusionadas con bordes más nítidos, mejor contraste y colores más naturales, incluso cuando los métodos competidores disponían de la ventaja de un preprocesamiento cuidadosamente ajustado. El nuevo enfoque mejoró métricas clave en torno a un 15 % en promedio en escenarios fuertemente degradados. Cuando las imágenes fusionadas se introdujeron en un sistema popular de detección de objetos, también condujo a una mayor precisión de detección que el uso de imágenes solo infrarrojas o visibles, o que otros sistemas de fusión.
Visión más clara para sistemas más seguros
En términos sencillos, este trabajo demuestra que decirle a una red de fusión de imágenes qué tipos de problemas visuales debe esperar —y permitirle arreglar y fusionar en un único paso estrechamente conectado— puede producir imágenes más limpias e informativas que tratar la mejora y la fusión como tareas separadas. Al acoplar la modelización de la degradación con el proceso de fusión y usar señales guiadas por lenguaje en cada capa, VGDCFusion puede adaptarse a formas variadas y mixtas de degradación de imagen sin ajustes humanos constantes. Este tipo de fusión inteligente y consciente de la degradación podría ayudar a futuros sistemas de visión, desde coches autónomos hasta cámaras de seguridad, a ver con más fiabilidad en las condiciones desordenadas e imperfectas del mundo real.
Cita: Zhao, J., Zhang, T. & Cui, G. A VLM guided network coupling degradation modeling for degradation aware infrared and visible image fusion. Sci Rep 16, 8249 (2026). https://doi.org/10.1038/s41598-026-38181-8
Palabras clave: fusión infrarrojo y visible, imágenes en baja iluminación, modelos visión‑lenguaje, degradación de imagen, percepción en conducción autónoma