Clear Sky Science · es
Un marco híbrido de ensamblaje apilado para la detección multietiqueta de emociones en texto
Por qué importa leer emociones en el texto
Cada día, la gente vuelca sus sentimientos en publicaciones en redes sociales, reseñas y mensajes. Ocultas en ese aluvión de palabras hay señales tempranas sobre problemas de salud mental, un aumento del discurso de odio y reacciones públicas ante crisis y desastres. Pero los ordenadores normalmente solo ven “positivo” o “negativo”, perdiéndose la mezcla de emociones que las personas reales suelen expresar a la vez. Este artículo explora una nueva forma de enseñar a las máquinas a reconocer varias emociones en un mismo texto y hacerlo no solo en inglés, sino también en idiomas que rara vez se benefician de la inteligencia artificial avanzada.
Avanzando más allá de lo simple positivo o negativo
Las herramientas tradicionales de análisis de sentimiento son como termómetros toscos: pueden decir si el estado de ánimo es bueno o malo, pero no si alguien siente ira, miedo, esperanza o alivio al mismo tiempo. Los autores sostienen que entender esta paleta emocional más rica es crucial para aplicaciones como la respuesta a desastres, el apoyo terapéutico y la atención al cliente. Un mensaje que mezcla miedo y urgencia, por ejemplo, puede exigir atención inmediata, mientras que uno que combina tristeza y optimismo puede solicitar otro tipo de apoyo. Capturar varias emociones en paralelo —conocido como detección de emociones “multietiqueta”— es por tanto un paso clave hacia sistemas más sensibles y conscientes del factor humano.
Dar voz a idiomas olvidados
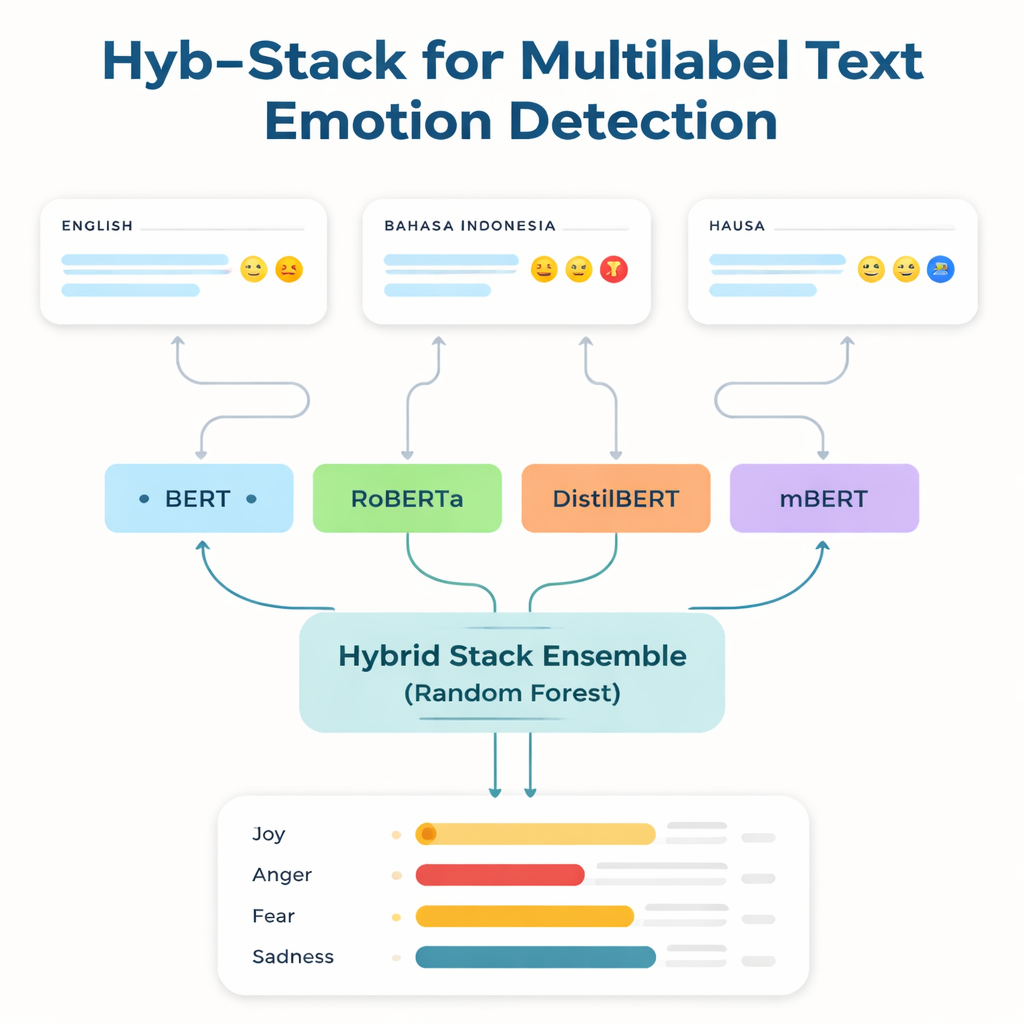
La mayoría de las potentes tecnologías lingüísticas se entrenan y ajustan en inglés y en unas pocas lenguas ampliamente usadas. Los hablantes de idiomas con pocos recursos —aquellos con pocos datos anotados y escasas herramientas digitales— suelen quedarse atrás. Para abordar esta brecha, los investigadores se centran en tres conjuntos de datos: un conocido banco de pruebas de emociones en inglés; una colección en bahasa indonesia centrada en lenguaje abusivo y de odio; y un nuevo corpus de Twitter en hausa que crearon, llamado HaEmoC_V1. El conjunto de hausa incluye más de doce mil tuits cuidadosamente limpiados y anotados, cada uno etiquetado con una o más de once emociones como ira, alegría, confianza, pesimismo y anticipación. Revisores expertos verificaron las etiquetas, y las puntuaciones de acuerdo muestran que las anotaciones son coherentes y fiables.
Combinar varios lectores inteligentes en uno
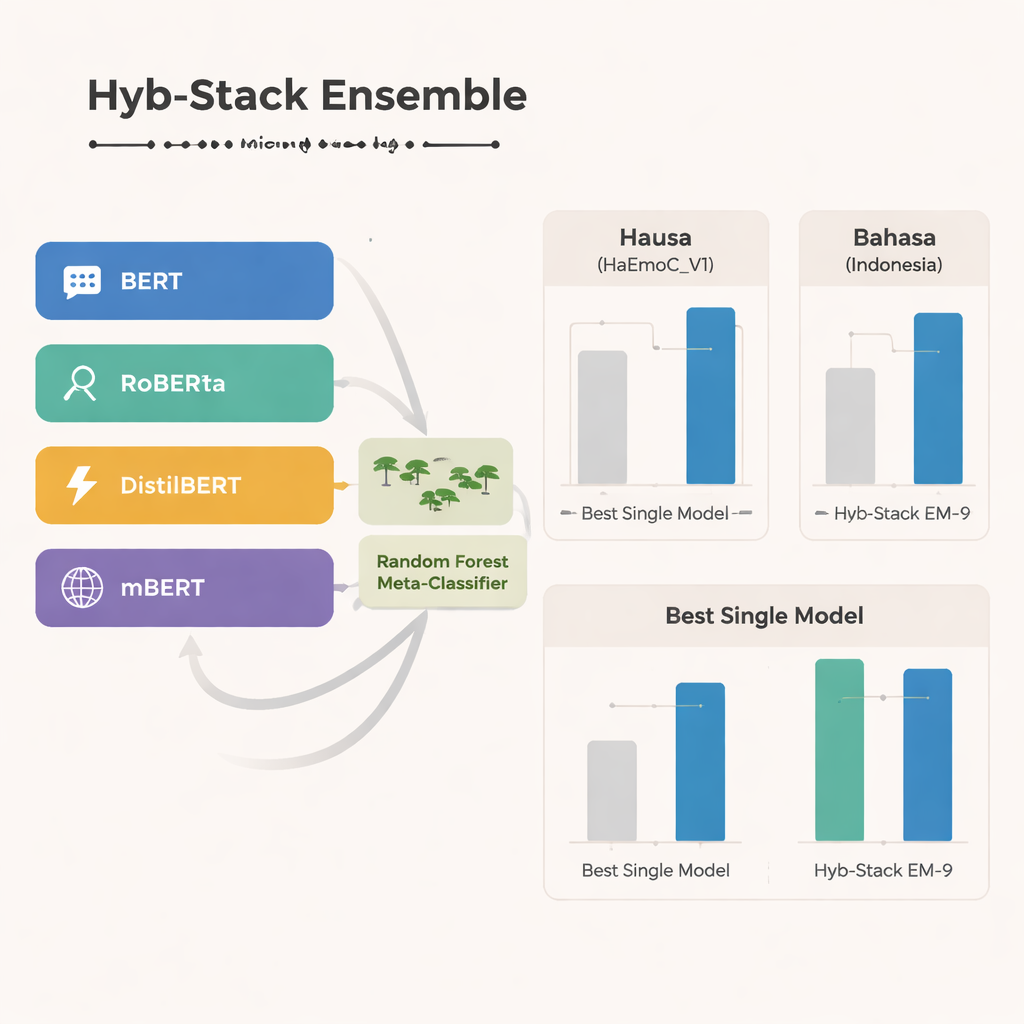
En el núcleo del estudio está Hyb-Stack, un ensamblaje apilado híbrido—una especie de “comité de expertos” para el lenguaje. Cuatro modelos avanzados basados en transformadores (BERT, RoBERTa, DistilBERT y el multilingüe mBERT) se afinan por separado para leer señales emocionales en el texto. En lugar de confiar en un solo modelo, Hyb-Stack permite que todos hagan predicciones y luego alimenta sus puntuaciones internas a un tomador de decisiones de segundo nivel: un clasificador Random Forest. Este meta-clasificador aprende a ponderar las diferentes fortalezas de cada modelo, capturando patrones complejos en cómo coocurren las emociones. El equipo también prueba métodos de ensamblaje más simples que solo promedian predicciones, con o sin ponderación por rendimiento previo, para evaluar si el apilado más elaborado realmente compensa.
Qué tan bien funciona el enfoque híbrido
En los tres idiomas, el mBERT multilingüe destaca como el modelo individual más fuerte, desempeñándose especialmente bien en los datos recién construidos de hausa y en el conjunto de discurso de odio en bahasa indonesia. Sin embargo, el ensamblaje híbrido llega todavía más lejos. Una combinación particular—denominada EM-9, que fusiona BERT, DistilBERT y mBERT dentro del marco Hyb-Stack—ofrece de forma consistente los mejores resultados. Logra puntuaciones F1 más altas, una medida común de precisión, que cualquier modelo individual o enfoque de promedio simple, con las mayores mejoras apareciendo en los conjuntos de datos de hausa y bahasa indonesia, con pocos recursos. Los análisis detallados de errores muestran que los fallos restantes suelen ocurrir entre emociones estrechamente relacionadas, como alegría frente a sorpresa o tristeza frente a miedo, reflejando la natural ambigüedad del sentir humano más que fallos claros del sistema.
Qué significa esto para sistemas del mundo real
Para un lector general, la principal conclusión es que combinar varios modelos de IA de forma inteligente puede ayudar a los ordenadores a leer emociones en texto con mayor precisión, especialmente en idiomas que durante mucho tiempo han sido descuidados por la tecnología. Al construir un corpus hausa de alta calidad y demostrar que los ensamblajes híbridos superan a modelos individuales y a esquemas de votación simples, los autores muestran un camino práctico hacia herramientas más inclusivas y emocionalmente conscientes. Trabajos futuros ampliarán el enfoque a matices emocionales más sutiles, lenguaje mixto, emojis y más idiomas poco representados, con el objetivo de crear sistemas que puedan percibir no solo si las personas están contentas o tristes, sino cómo y por qué sienten lo que sienten—sin importar el idioma que hablen.
Cita: Adamu, H., Azmi Murad, M.A. & Nasharuddin, N.A. A hybrid stacked ensemble learning framework for multilabel text emotion detection. Sci Rep 16, 7714 (2026). https://doi.org/10.1038/s41598-026-38172-9
Palabras clave: detección de emociones, PNL multilingüe, aprendizaje por ensamblaje, modelos transformadores, idiomas con pocos recursos