Clear Sky Science · es
Cálculo eficiente y diseño de una arquitectura de multiplicador védico de doble precisión y alta velocidad
Por qué importa acelerar el cómputo
Cada vez que transmites un vídeo, usas la navegación en el teléfono o permites que un sistema de IA analice imágenes médicas, hardware especializado realiza silenciosamente miles de millones de pequeñas operaciones por segundo. Una gran parte de esas operaciones son multiplicaciones de números en punto flotante, la forma estándar en que los ordenadores representan valores reales como 3,14159. Este artículo explora una manera más inteligente de construir uno de esos componentes esenciales: un multiplicador de alta velocidad y bajo consumo energético que recurre a ideas de la matemática védica antigua para mejorar el hardware digital moderno.
De trucos matemáticos antiguos a chips modernos
La aritmética de punto flotante sustenta el procesamiento digital de señales, el procesamiento de imágenes, las comunicaciones y los aceleradores de aprendizaje profundo. Los multiplicadores estándar deben manejar palabras binarias anchas —64 bits para doble precisión— y hacerlo rápidamente sin desperdiciar área de chip ni energía. Enfoques tradicionales, como Booth, Karatsuba y los multiplicadores en arreglo, equilibran compensaciones entre velocidad, tamaño de hardware y complejidad de diseño. La matemática védica, un sistema de 16 reglas aritméticas clásicas desarrollado en India, incluye un método de multiplicación llamado Urdhva Tiryakbhyam, o “vertical y en cruz”. Forma productos parciales de manera altamente paralela, lo que puede reducir el número de pasos intermedios y el hardware necesario. Investigadores han adaptado recientemente estas ideas a circuitos digitales, pero los diseños existentes aún arrastran sobrecargas cuando se usan para operaciones de punto flotante de doble precisión.
Qué hace especial a este nuevo multiplicador
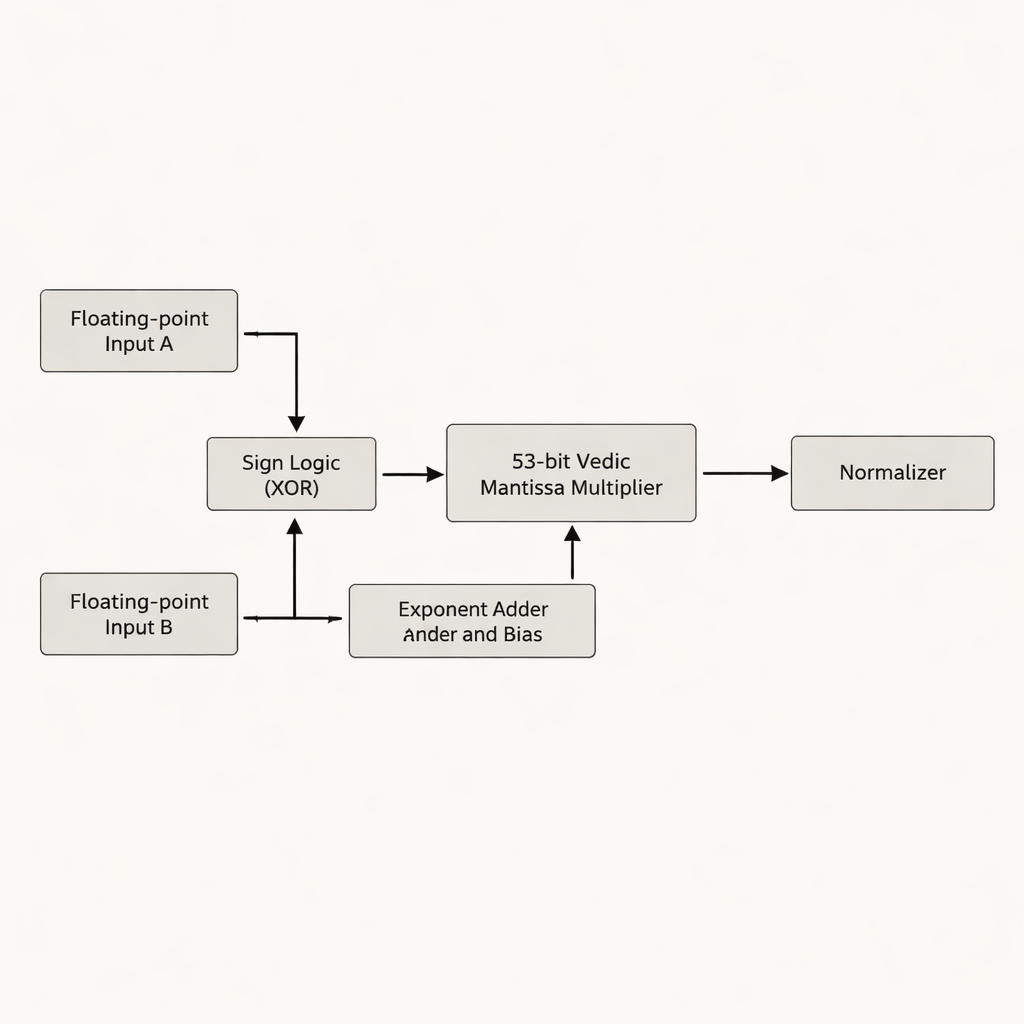
Los autores proponen un multiplicador de punto flotante de doble precisión que se centra en la mantisa —la parte de un número en punto flotante que contiene la mayoría de los dígitos significativos. En lugar de rellenar la mantisa de 52 bits hasta 54 bits, como hacen muchos diseños previos, trabajan con la verdadera mantisa efectiva de 53 bits, evitando bits “en blanco” desperdiciados que consumen almacenamiento y cableado adicional en el chip. El núcleo del diseño es un multiplicador védico de 53 bits basado en Urdhva Tiryakbhyam, dispuesto en una jerarquía de bloques constructores más pequeños: unidades de 3 bits forman unidades de 6 bits, que construyen unidades de 12 bits, 13 bits, 26 bits y 52 bits, todas combinadas en la etapa final de 53 bits. La arquitectura separa el trabajo en tres fases principales —cálculo del signo, suma y sesgado del exponente, y multiplicación de la mantisa seguida de normalización— acorde con la norma IEEE-754 mientras recorta circuitería redundante.
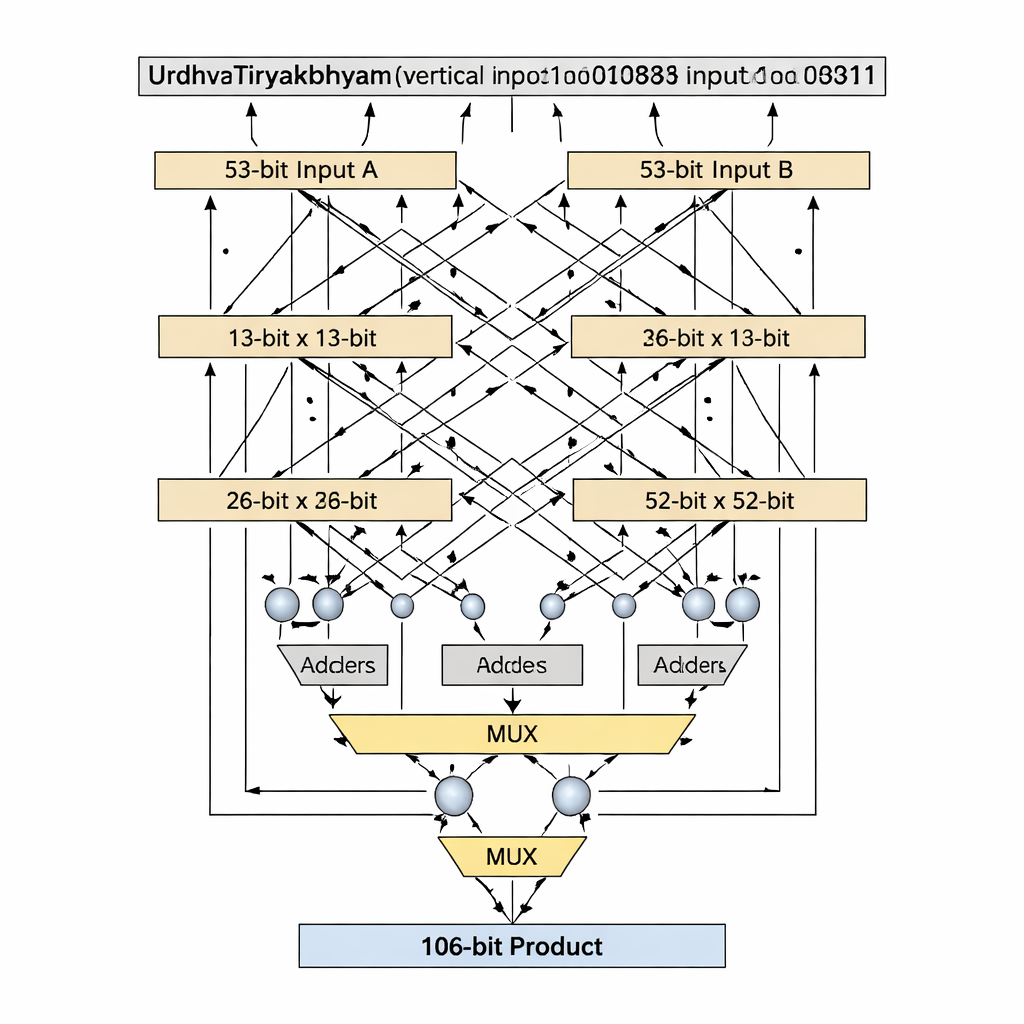
Bloques de tamaño primo para un hardware más limpio
Una innovación clave es cómo el diseño maneja anchuras de bit que son números primos, como 13 y 53, que no se dividen limpiamente en bloques de tamaño igual. Las descomposiciones védicas estándar asumen entradas divididas de forma uniforme, pero eso se vuelve incómodo o derrochador para longitudes primarias. Los autores introducen un algoritmo de “bits primos” que reutiliza astutamente un multiplicador védico más pequeño de (n−1) bits, además de sumadores, multiplexores y una única puerta lógica extra, para emular un multiplicador de n bits sin relleno. Para la etapa de 13 bits, las entradas se dividen en secciones de 1 bit y 12 bits; se crean productos parciales usando un multiplicador védico de 12 bits, selección condicional (vía multiplexores) basada en los bits más significativos y un pequeño número de sumadores. El mismo patrón escala hasta 53 bits con un núcleo de 52 bits. Esta descomposición a medida acorta la ruta crítica —la cadena más larga de lógica que debe recorrer una señal— mientras mantiene bajo el número de elementos lógicos.
Ganancias medidas en velocidad, tamaño y energía
El diseño se describió en el lenguaje de descripción de hardware Verilog e implementó en una FPGA Xilinx Zynq usando las herramientas Vivado. En multiplicadores védicos de 13, 26, 52, 53 y 64 bits, la unidad propuesta de 53 bits muestra un equilibrio favorable entre retardo, uso lógico (tablas de consulta y pines de E/S) y potencia estimada. Al compararlo con multiplicadores de doble precisión anteriores basados en Booth, Karatsuba y otras disposiciones védicas, la nueva arquitectura reduce significativamente el retardo en el peor caso y la cantidad de recursos de FPGA necesarios, sin añadir complejidad a la circuitería de punto flotante circundante. Porque la multiplicación de la mantisa es más rápida y la profundidad lógica es menor, la actividad de conmutación se reduce, lo que apunta a un mejor producto potencia–retardo aunque las comparaciones directas de potencia entre tecnologías sean difíciles de realizar.
Impacto en IA y procesamiento de señales
Para evaluar el diseño en una carga de trabajo real, los autores integraron su multiplicador védico de doble precisión en el motor de convolución de una red neuronal convolucional, donde las operaciones de multiplicar y acumular dominan el tiempo de ejecución. Sustituir los multiplicadores convencionales IEEE-754 y védicos previos por el nuevo diseño redujo la latencia de las convoluciones, bajó el consumo de energía y disminuyó el tiempo de inferencia, todo ello manteniendo la misma precisión de clasificación. Se esperan ventajas similares en otras tareas intensivas en cómputo, como filtrado digital, detección de bordes y canales de procesamiento de imágenes médicas, donde multiplicadores más rápidos incrementan directamente el rendimiento y pueden permitir que los dispositivos funcionen más fríos o con baterías más pequeñas.
Qué significa esto para la tecnología cotidiana
En términos sencillos, el artículo demuestra que tomar una idea de multiplicación ingeniosa de la matemática védica y adaptarla cuidadosamente a formatos binarios modernos puede producir un multiplicador más pequeño, rápido y energéticamente eficiente que los diseños estándar. Este bloque constructivo mejorado puede integrarse en procesadores, chips de procesamiento de señales y aceleradores de IA, conduciendo a análisis de datos más rápidos, dispositivos más sensibles y, potencialmente, menor consumo de energía en sistemas que van desde teléfonos inteligentes hasta escáneres médicos. Los autores también describen direcciones futuras, incluyendo lógica reversible para un uso energético aún menor e integración en unidades de proceso más grandes, lo que sugiere que esta unión entre aritmética antigua y hardware moderno apenas comienza.
Cita: Kumar, A.S., Sahitya, G., Kusuma, R. et al. Efficient computation and design of high speed double precision Vedic multiplier architecture. Sci Rep 16, 7364 (2026). https://doi.org/10.1038/s41598-026-38147-w
Palabras clave: Multiplicador védico, Aritmética de punto flotante, Diseño en FPGA, Procesamiento digital de señales, Redes neuronales convolucionales